










As software teams deploy increasingly sophisticated LLM agents across real-world applications, ensuring these systems behave reliably, ethically, and efficiently is no longer optional: it’s foundational. From autonomous task solvers to multi-agent orchestration pipelines, llm agents are becoming central to how organizations scale AI in production. But with growing complexity comes the need for rigorous, continuous evaluation.
Agent evaluation isn’t just about catching bugs or measuring performance; it’s about building trust in automation. It’s a systematic approach to understanding how agent AI behaves across diverse inputs, edge cases, and user expectations. Whether you’re debugging hallucinations, assessing bias, or validating agent workflows, a robust evaluation process separates proof-of-concept demos from production-grade systems.
In this blog post, we explore what makes agent evaluation essential for modern AI development teams. We break down the key dimensions of AI agent evaluation, outline proven methodologies, and highlight the role of evaluation-driven development in shipping reliable agent AI at scale. We’ll also look at how tools like Orq.ai can support teams in building, testing, and optimizing LLM agents through an integrated evaluation platform.
Understanding AI Agent Evaluation
Evaluating AI agents is becoming a core part of building dependable, production-ready language model applications. As agent architectures evolve and become more complex, the need for structured, repeatable, and meaningful evaluation grows alongside them.
What is AI Agent Evaluation?
AI agent evaluation refers to the process of systematically assessing how well an autonomous agent, typically powered by large language models (LLMs), performs across defined tasks, user intents, and interaction flows. Whether you’re working with a single llm agent or orchestrating a team of agents, understanding how each one behaves under different conditions is critical.

Credits: Medium
Evaluation involves designing representative test cases, applying relevant metrics, and conducting both quantitative and qualitative analysis. Common evaluation agent workflows often include skill evaluation, trace analysis, and router evaluation, especially in systems with branching logic or modular capabilities.
Traditional NLP concepts like precision, recall, and exact match still play a role in evaluating agent responses, but the dynamic nature of multi-turn conversations and real-time environments demands more nuanced, custom evaluation metrics. In some cases, qualitative testing examples and human-in-the-loop review may complement automated tests to offer a more complete picture.
Why Evaluate AI Agents?
The evolution of AI agents has accelerated dramatically, but performance in controlled demos doesn’t always translate into production reliability. Without proper evaluation, llm agents may fail in subtle but critical ways, such as providing incomplete answers, hallucinating facts, or behaving inconsistently across similar prompts.
Un-evaluated agents pose several risks:
Bias amplification, especially in sensitive decision-making contexts
Security vulnerabilities from misinterpreted or adversarial inputs
Workflow breakdowns due to poor routing or state management
Comprehensive agent evaluation mitigates these risks by providing visibility into how agents perform across diverse and unpredictable scenarios. It also enables evaluation-driven development, where feedback from real-world behavior feeds directly back into your training, prompting, and routing strategies.
Moreover, meeting compliance requirements, whether around fairness, auditability, or explainability, requires evidence-based assessment. Incorporating production monitoring, automated testing pipelines, and custom evaluation metrics gives teams the confidence to iterate quickly without sacrificing trust or safety.
Key Components of AI Agent Evaluation
Building a reliable evaluation stack starts with breaking down the key dimensions that define agent behavior. A structured evaluation process helps teams focus on what matters most, whether that’s minimizing latency, improving response quality, or ensuring consistent behavior across changing conditions. Below, we explore the primary components that shape how to evaluate an agent machine effectively.
Performance Metrics
Performance metrics are foundational to any AI evaluation workflow. They help quantify how well an agent executes tasks and where it may be falling short.
Accuracy measures how closely the agent’s output matches the intended result, often using exact match, in-order match, or any-order match techniques depending on the task type.
Response time reflects system latency and overall user experience.
Resource utilization highlights efficiency and infrastructure impact.
For more complex outputs, a final response evaluation might involve comparing generated text against expected outputs using code-based evaluators or heuristic scoring. These metrics are often best interpreted through structured experiments that account for different variables and usage patterns.
Robustness Testing
Robustness testing examines how agents behave under stress: ambiguous inputs, edge cases, malformed prompts, or adversarial examples. This is especially important when deploying LLM agents in user-facing environments, where unexpected queries are the norm, not the exception.
Trajectory evaluation can be helpful here, tracking the sequence of decisions an agent makes and analyzing whether each step aligns with expected behavior. Robust agents don’t just give the right answer: they navigate complex paths reliably to get there.
Ethical and Bias Assessment
A key question in modern AI development is not just can an agent complete a task, but should it respond in a particular way. Bias, stereotyping, and fairness issues often surface in subtle ways, especially when dealing with subjective or open-ended tasks.
An effective bias assessment includes diverse test cases, demographic variations, and qualitative review. Your evaluator selection, automated or human-in-the-loop, matters here, as does ensuring that your testing methods are transparent and reproducible.
Ethical evaluation should be baked into your workflow from day one, not treated as an afterthought or compliance checkbox.
Security Evaluation
Agents that process open-ended user input are inherently exposed to a range of security risks, from prompt injection to data leakage. Security evaluation aims to surface these issues before they appear in production.
This may involve:
Fuzz testing and red-teaming prompts
Testing agent behavior against known attack patterns
Evaluating how the agent handles sensitive or adversarial content
Incorporating security into your structured evaluation process allows teams to catch vulnerabilities early and apply guardrails as needed. This is particularly crucial when LLMs are embedded in customer-facing applications or internal systems with access to private data.
Methodologies for Evaluating AI Agents
As the complexity of agent systems increases, the evaluation approach must evolve in parallel. The shift toward modular, multi-step reasoning, emergent behavior, and dynamic orchestration highlights the importance of a methodical, framework-driven approach to testing. These methodologies don’t just validate performance; they shape how we understand the trajectory of AI agent evolution and influence how systems are iteratively improved.
Building a Comprehensive Test Suite
Effective evaluation starts with coverage. A well-rounded test suite should reflect both typical use cases and the messy, unpredictable edge cases that arise in real-world deployment.
This includes:
Clear input-output pairs for structured tasks
Multi-turn prompts to test consistency across interactions
Corner-case scenarios to stress-test agent logic
Coverage can be increased through component-wise evaluation, where each subsystem of the agent (e.g., task routing, memory handling, output formatting) is tested individually. This granular approach surfaces issues that holistic evaluations might miss.
By capturing both expected and atypical behaviors, you improve both confidence in the system and the ability to respond to failures during runtime. Observing how the agent handles these cases also lays the groundwork for deeper observability strategies at production scale.
Analyzing Agent Workflows
Beyond inputs and outputs, evaluating the internal decision-making of an agent is key to building reliable systems. This is especially true in agents that chain reasoning steps or operate with planning and memory components.
Workflow analysis involves:
Tracing the sequence of decisions made by the agent
Identifying where errors occur and why
Mapping input-output relationships back to underlying logic
This method is particularly helpful when agents use external tools, APIs, or memory-based reasoning. Understanding the “why” behind the final answer offers clarity that simple correctness metrics can’t provide.
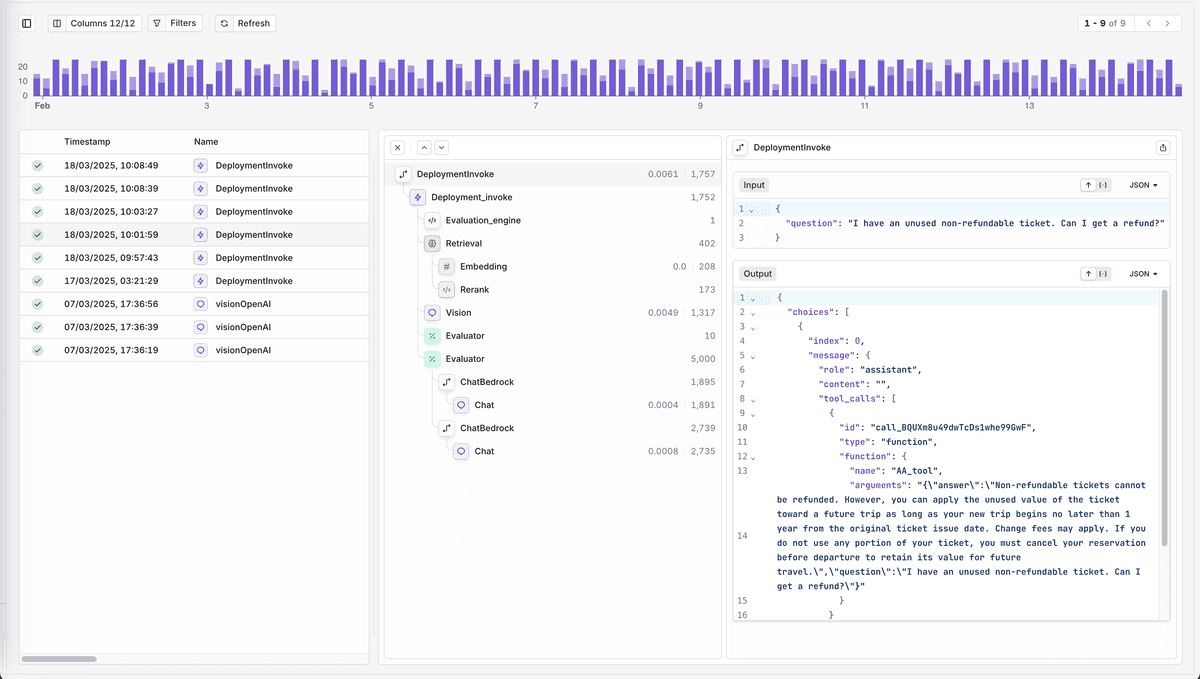
Overview of tracing in Orq.ai
Workflow analysis also supports llm monitoring, helping teams monitor the full execution path of the agent in both test and production environments.
Utilizing Automated Evaluation Frameworks
Automated evaluation frameworks reduce manual effort and bring consistency to how agent outputs are assessed. These can include:
Programmatic assertions for expected outputs
Embedding-based similarity scoring
Chain-of-thought grading and reasoning path validation
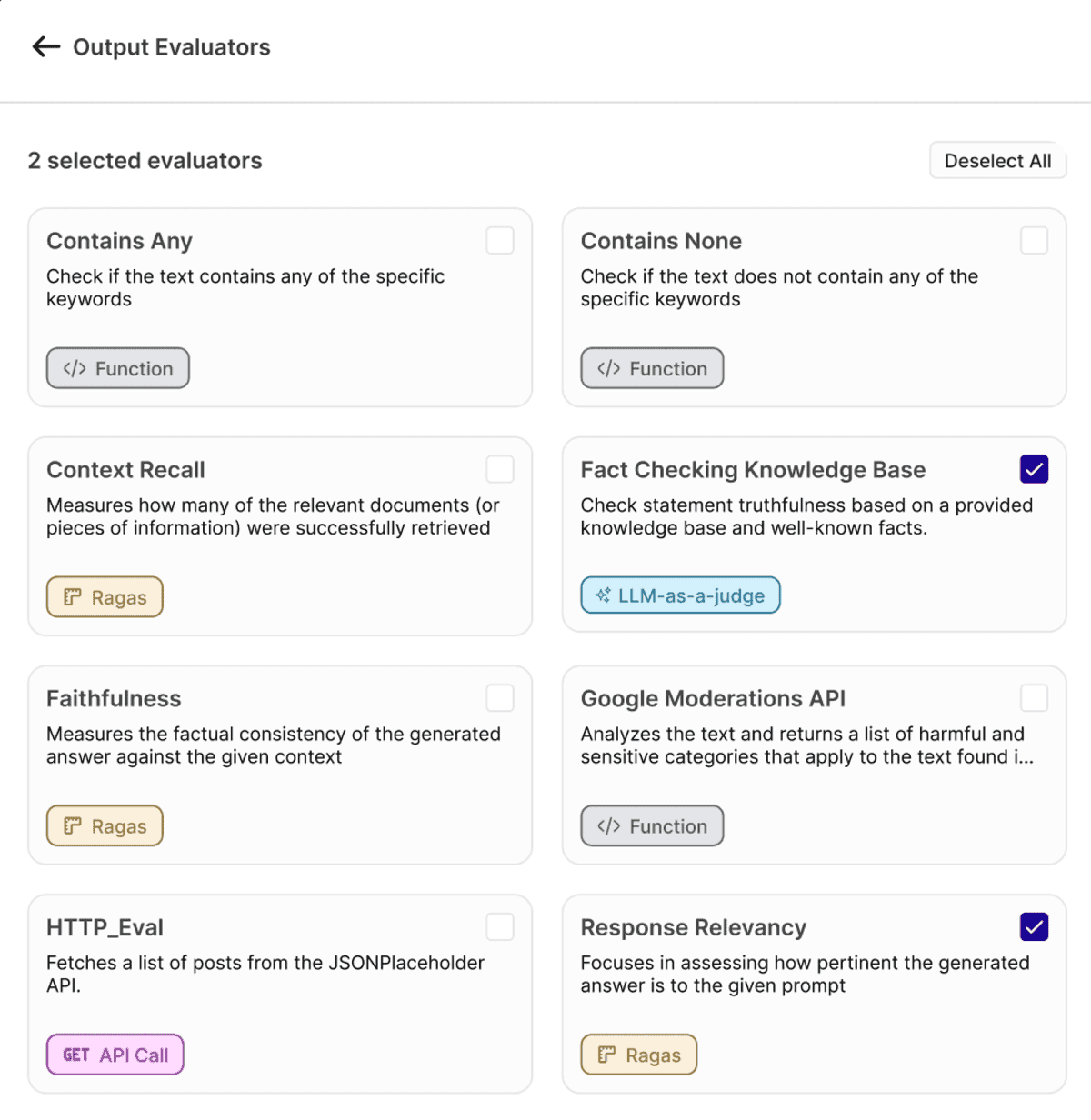
Overview of selected programmatic evaluators in Orq.ai's Evaluator Library
Increasingly, teams are adopting AI evaluators, which are LLMs themselves tasked with judging the quality of another agent’s response. When paired with human-in-the-loop reviewers, this hybrid approach balances scale with nuance, particularly in subjective or open-ended tasks.
As the AI agent evolution continues, evaluation methods that account for reasoning depth, error recovery, and context handling will be essential: not just to measure success, but to understand how systems behave and improve over time.
Tools and Platforms for AI Agent Evaluation
As the landscape of AI agent development expands, a variety of tools and platforms have emerged to assist teams in evaluating and refining their agents. Selecting the appropriate tool depends on factors such as team composition, project requirements, and desired collaboration levels.
Overview of Existing Evaluation Tools
LangChain: Known for its developer-centric approach, LangChain offers a suite of tools tailored for building and evaluating AI agents. Its focus on code-based evaluators and trajectory analysis provides granular control over agent assessment. However, this emphasis on developer tools can make it challenging for non-technical stakeholders to engage fully in the evaluation process.
LangGraph: An extension of LangChain, LangGraph introduces graph-based structures to model complex agent workflows. This facilitates detailed analysis of agent decision paths and interactions. While powerful, the complexity of LangGraph's framework may present a steep learning curve for teams without specialized expertise.
CrewAI: Designed to support multi-agent systems, CrewAI emphasizes collaboration and task delegation among agents. It integrates tools like Patronus for evaluation purposes, allowing agents to assess and score inputs and outputs. While CrewAI offers robust features for agent collaboration, integrating and customizing evaluation tools within the platform may require additional effort to align with specific project needs.
Arize AI: Arize AI, also known as Arize Phoenix, focuses on observability, monitoring, and performance tracking for machine learning and LLM applications. It supports LLM evaluation with features like embedding drift detection, performance tracing, and fine-grained analysis of agent outputs. While Arize excels in post-deployment monitoring, it may require integration with additional tooling to support pre-production experimentation or non-technical evaluation workflows.
Orq.ai: Agent Evaluation Platform
Orq.ai provides a comprehensive platform designed to streamline the evaluation and optimization of AI agents.
Key features include:
Integrated Evaluation Environment: Orq.ai offers a unified interface for testing and monitoring AI agents, enabling teams to conduct assessments within a single, cohesive environment.
Real-Time Performance Analytics: The platform delivers immediate insights into agent performance metrics such as accuracy, response time, and resource utilization, facilitating prompt adjustments and continuous improvement.
Customizable Testing Scenarios: Teams can create tailored test cases that reflect real-world applications and challenges, ensuring agents are evaluated under conditions that closely mimic their intended operational environment.
Collaboration and Version Control: Orq.ai supports team collaboration with features for tracking changes and maintaining version histories, allowing for coordinated development and evaluation efforts across diverse team members.
Emphasis on Ethical Evaluation: The platform includes tools designed to detect and mitigate biases, promoting fairness and ethical considerations in agent decision-making processes.

Setting up evaluators and guardrails in Orq.ai
By integrating these features, Orq.ai provides a balanced solution that caters to both technical and non-technical stakeholders, facilitating a comprehensive and inclusive approach to AI agent evaluation.
Book a demo with our team to explore our platform today.
Agent Evaluation: Key Takeaways
As AI agents become more capable and more deeply embedded into real-world applications, the importance of rigorous evaluation only grows. Agent behavior is not static; it shifts with changes in context, input complexity, and user expectations. That’s why a thoughtful, end-to-end evaluation agent strategy isn’t just a box to check; it’s a core part of building trustworthy systems.
From defining the right metrics to creating diverse test cases, from implementing component-wise evaluation to integrating observability across production environments, evaluating AI agents is a multi-dimensional process. And it doesn’t stop at deployment—continuous evaluation, skill assessment, and ethical oversight are necessary to ensure that agents remain robust, accurate, and fair as they evolve.
While many teams still rely on fragmented tooling to handle different stages of AI agent evaluation, there’s growing recognition of the need to consolidate workflows. Single-tool use—where development, testing, monitoring, and optimization are handled within one cohesive platform—can drastically reduce complexity and help teams move faster without compromising quality.
By following these principles, and leveraging the right frameworks and platforms, teams can confidently navigate the fast-moving world of AI agent evolution and ship reliable, responsible AI systems that stand up to real-world complexity.

