









Large Language Models (LLMs) have transformed how artificial intelligence (AI) tackles complex tasks. While early iterations relied on single-agent systems, where one model handled all aspects of a given task, AI research has shifted toward multiagent architectures. These systems distribute responsibilities across different agents, each specializing in distinct functions like retrieval, reasoning, or decision-making. By working together, LLM agents can solve problems more efficiently, improve response accuracy, and adapt to dynamic environments.
However, as multiagent systems become more sophisticated, evaluating their performance grows increasingly complex. Traditional assessment methods fall short when measuring coordination, scalability, and inter-agent communication. This is where evaluation frameworks come in. A well-structured LLM agent framework provides the necessary benchmarks to assess collaboration quality, resource efficiency, and output reliability.
In this article, we explore the evolution of multiagent LLM systems, key metrics for assessment, and the best tools available for evaluation. Whether you're optimizing an existing system or building from the ground up, understanding these principles is essential for developing high-performing AI models.
Understanding Multi-Agent LLM Systems
Definition and Components
AI models have evolved beyond single-agent systems, paving the way for multi-agent AI architectures. Unlike traditional LLMs that operate in isolation, multi-agent systems distribute tasks across multiple specialized entities, each designed to handle a specific function. This LLM agent architecture enhances efficiency by enabling different agents to collaborate in real time, improving decision-making and task execution.
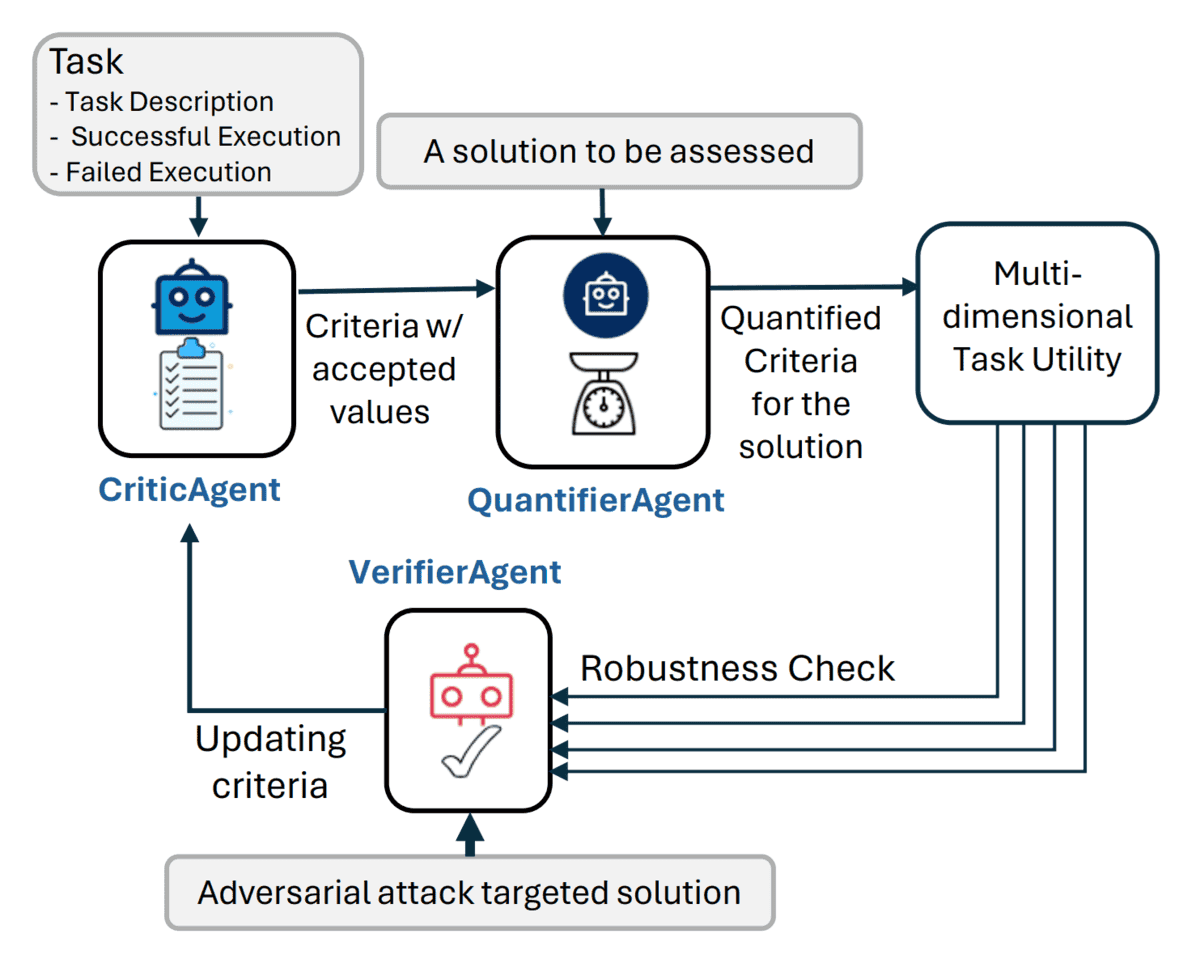
Credits: Microsoft
A multi-agent system typically consists of:
Task-Specific Agents: Each agent specializes in a particular domain, such as retrieval, summarization, or reasoning.
Coordinator Agents: These oversee interactions between agents, ensuring seamless collaboration.
External Tool Integrators: Agents that interface with APIs, databases, and external resources to enhance responses.
Since these systems rely on multiple entities working in tandem, robust agent evaluation is critical. Performance benchmarks must assess how well agents communicate, allocate resources, and complete assigned tasks. Organizations often implement an agent feedback form to monitor effectiveness, measure response accuracy, and refine system outputs.
By structuring AI models around multi-agent principles, developers can create more adaptive, scalable, and intelligent solutions. However, the effectiveness of these systems hinges on proper evaluation methods, which will be explored in later sections.
Advantages Over Single-Agent Systems
As AI systems grow more complex, single-agent models often struggle with tasks that require adaptability, scalability, and nuanced decision-making. Multi-agent AI systems address these limitations by leveraging multiple specialized agents that work together to enhance performance in dynamic environments.
Improved Decision-Making and Adaptability
One of the key strengths of multi-agent learning is its ability to refine decision-making through collaboration. Instead of a single model handling all aspects of a task, different agents can share information, cross-verify responses, and refine outputs based on shared knowledge. This structure allows for:
Context-Aware Reasoning: Agents dynamically adjust their responses based on new data and evolving conditions.
Error Mitigation: By integrating multiple perspectives, agents can detect inconsistencies and correct errors in real time.
Adaptive Strategies: Learning from interactions enables agents to modify their approach, improving problem-solving efficiency.
These capabilities contribute to emergent properties: unpredictable yet beneficial behaviors that arise from agent collaboration. Unlike single-agent systems, which rely on predefined responses, multi-agent architectures can generate novel insights and strategies based on shared intelligence.
Enhanced Scalability and Performance in Dynamic Tasks
A major advantage of multi-agent architectures is their ability to handle large-scale operations efficiently. By distributing workloads across multiple entities, these systems optimize parallel processing, allowing them to tackle complex tasks faster than traditional models. This is particularly useful in:
Large-Scale Data Processing: Agents can independently analyze subsets of data and compile results efficiently.
Multi-Step Problem Solving: Tasks that require sequential reasoning benefit from modularized execution.
Autonomous System Management: In AI-driven applications like robotics and finance, multi-agent control ensures stable and responsive automation.
As AI research progresses, some theorists speculate whether advanced multi-agent systems could offer insights into the hard problem of consciousness: the question of whether machine intelligence can achieve subjective awareness. While we are far from such breakthroughs, today’s multi-agent LLMs are already demonstrating unprecedented levels of intelligence and autonomy.
By leveraging multi-agent AI, organizations can build more resilient, scalable, and efficient AI applications. However, ensuring their reliability requires comprehensive evaluation frameworks, which we will explore in the next section.
Key Metrics for Evaluating Multi-Agent LLM Systems
As multi-agent LLM eval systems grow more sophisticated, assessing their performance requires comprehensive evaluation systems that go beyond traditional benchmarks. Since these models rely on dynamic agent interactions, evaluation must consider collaboration, efficiency, scalability, and ethical implications.
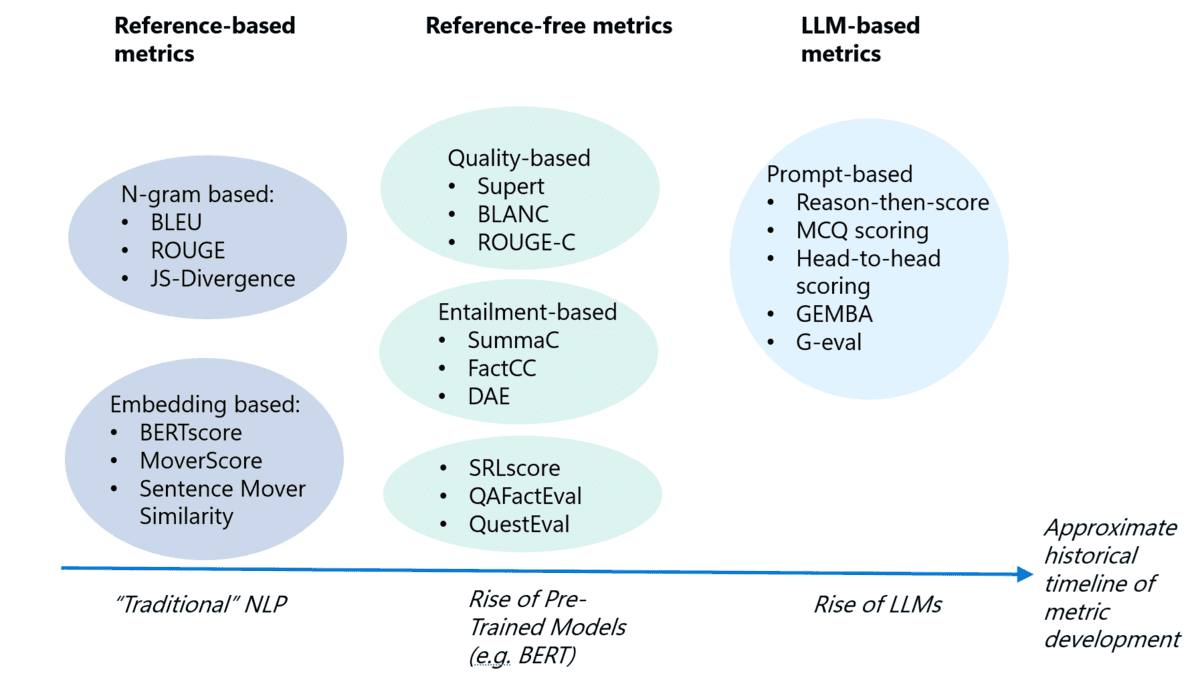
Credits: Microsoft
Below are the core metrics used to measure the effectiveness of multi-agent LLMs.
Collaboration & Coordination
In multi-agent systems, success depends on how well different agents work together to achieve a shared goal. Coordination is assessed using:
Communication Efficiency: How effectively agents exchange information.
Decision Synchronization: Whether agents align their actions to optimize outcomes.
Adaptive Feedback Loops: Mechanisms that allow agents to refine their responses based on prior interactions.
Tools like Ragas evaluation frameworks help quantify collaboration quality by analyzing structured outputs, inter-agent messaging, and response coherence.
Resource Utilization
While multi-agent architectures enable powerful AI applications, they also introduce computational overhead. Evaluating resource utilization focuses on:
Memory and Processing Load: Measuring how efficiently agents use computational power.
Task Prioritization: Ensuring agents allocate resources based on task importance.
Optimization via Neural Correlates: Identifying activity patterns that indicate computational bottlenecks.
By analyzing state graph representations, developers can track system performance and identify inefficiencies.
Scalability
As the number of agents grows, systems must maintain efficiency without degradation in performance. Scalability is measured through:
Linear vs. Exponential Growth: Whether computational demands scale predictably.
Task Distribution Effectiveness: Ensuring workloads are evenly balanced.
Latency in Decision-Making: Evaluating response time as the agent network expands.
A well-designed multi-agent LLM eval system should handle increasing complexity without excessive lag or inefficiencies.
Output Quality
The effectiveness of a multi-agent system ultimately depends on the quality of its outputs. Key factors include:
Accuracy: Do the responses align with factual data?
Coherence: Are agent-generated outputs structured and logical?
Consistency Across Interactions: Do repeated queries yield reliable results?
To track these aspects, evaluation scores derived from benchmark datasets can quantify model performance and guide improvements.
Ethical Considerations
As multi-agent AI systems advance, ethical concerns become increasingly relevant. Evaluation must consider:
Bias Detection: Ensuring fair and unbiased responses across diverse inputs.
Transparency in Decision-Making: Providing insight into why an agent chose a specific action.
Potential for Sentience and Self-Awareness: While current models lack true cognition, some researchers explore whether advanced AI systems could exhibit primitive forms of self-awareness.
By incorporating ethical assessments into evaluation pipelines, AI developers can ensure that multi-agent systems remain fair, explainable, and aligned with human values.
Building an Effective Evaluation Pipeline
Evaluating multi-agent LLM systems requires a structured approach that tracks agent interactions, aligns with specific goals, and implements robust evaluation frameworks. An effective pipeline ensures that different agents perform optimally and that their outputs remain reliable, efficient, and scalable.
Agent Interaction Logging
To understand how multi-agent AI systems make decisions, logging agent interactions is essential. This involves:
Recording Decision Trees: Mapping out agent responses to track reasoning patterns.
Monitoring Conditional Edges: Evaluating how an agent shifts between choices based on context.
LoopControlNode Implementations: Identifying feedback loops where agents refine their outputs based on prior interactions.
By structuring agent interactions into graph-based models, developers can gain insights into system behavior, optimizing both performance and automatic summarization of decision processes.
Defining Evaluation Metrics
To create a meaningful evaluation pipeline, metrics must be designed around the system’s objectives. Key considerations include:
Output Accuracy: Measuring how well responses align with ground truth data.
Cognitive Load Management: Ensuring agents distribute tasks efficiently.
Simulation of Consciousness: While true AI consciousness remains theoretical, some evaluation models explore whether multi-agent systems display rudimentary subjective experience in their problem-solving approaches.
By leveraging concepts like integrated information theory, researchers assess whether multi-agent systems exhibit signs of emergent intelligence, decision-making complexity, or self-reflection.
Implementing Evaluation Frameworks
Once logging and metrics are in place, the next step is integrating tools to measure agent performance effectively. This includes:
Automated Benchmarking: Comparing results across different frameworks.
Scalability Stress Tests: Evaluating system efficiency under increased agent loads.
Mapping to Biological Substrate Models: Some AI researchers draw comparisons between multi-agent networks and neural architectures, assessing whether advanced systems resemble biological cognition.
A well-structured evaluation pipeline not only tracks performance but also provides insights into AI consciousness, thus helping researchers understand how multi-agent systems evolve over time.
Existing Evaluation Frameworks and Tools
Evaluating multi-agent AI systems requires specialized frameworks that can track performance, measure collaboration, and ensure output quality. Below are some of the leading evaluation tools available today, each with its strengths and limitations.
ChatEval
Overview: ChatEval is designed to assess the quality of AI-generated text across various benchmarks. It provides detailed performance metrics for GPT-4, Claude, and Gemini, making it a useful tool for comparing LLM outputs.
Limitations: Primarily focused on single-agent systems, limiting its effectiveness for multi-agent AI evaluation. It also lacks deep interaction tracking and real-time adaptability.
Best For: Researchers comparing single-turn conversational outputs across different LLMs.
LangGraph
Overview: LangGraph enables structured workflows for LLM-based applications, allowing developers to construct and analyze multi-step interactions between agents.
Limitations: While useful for workflow visualization, it lacks built-in benchmarking for evaluating multi-agent AI systems at scale.
Best For: Developers creating complex multi-agent workflows who need a flexible graph-based tool.
DeepEval
Overview: DeepEval offers a robust framework for LLM performance testing, including accuracy, consistency, and response quality metrics.
Limitations: Geared more toward benchmarking single models like GPT-4 and Claude, rather than full multi-agent AI ecosystems.
Best For: Organizations conducting rigorous performance assessments of standalone LLMs.
TruLens
Overview: TruLens provides real-time observability and explainability tools for LLMs, helping users understand how models arrive at decisions.
Limitations: Does not natively support multi-agent evaluations or scalability testing.
Best For: Teams prioritizing interpretability in AI-driven decision-making.
Ragas
Overview: Ragas specializes in retrieval-augmented generation (RAG) evaluation, ensuring LLMs retrieve and utilize relevant data effectively.
Limitations: Best suited for RAG-based systems, rather than comprehensive multi-agent AI evaluation.
Best For: Enterprises integrating LLMs with external knowledge bases.
DeepCheck
Overview: DeepCheck offers automated testing for LLM applications, monitoring bias, consistency, and adherence to predefined rules.
Limitations: Lacks advanced capabilities for evaluating inter-agent collaboration in multi-agent AI settings.
Best For: Teams ensuring compliance and ethical AI performance in LLM applications.
While these tools offer valuable insights, they often lack the scalability, real-time adaptability, and comprehensive evaluation needed for multi-agent AI systems.
Orq.ai provides a streamlined, scalable, and efficient alternative—specifically designed to evaluate multi-agent LLMs with deep interaction tracking, real-time feedback loops, and automated benchmarking for models like GPT-4, Claude, and Gemini.
Orq.ai for Multi-Agent LLM Evaluation
Orq.ai is a Generative AI Collaboration Platform that empowers software teams to build, deploy, and optimize Large Language Model (LLM) applications at scale. By providing comprehensive tools in a user-friendly interface, Orq.ai streamlines the development of reliable GenAI applications, facilitating real-time control and performance optimization.
Enhancing Multi-Agent Evaluation with Orq.ai
Orq.ai offers a robust suite of evaluation tools tailored for multi-agent LLM systems:
Evaluation Library: Access a diverse range of pre-built evaluators or create custom ones to assess your AI application's performance effectively.
Human Evaluation: Incorporate feedback from subject-matter experts or end-users to build golden datasets, enhancing the accuracy and reliability of your AI models.
LLMs as a Judge: Utilize language models to evaluate outputs in test environments, ensuring prompt and model configurations meet desired standards before production deployment.
Guardrails: Implement automatic evaluations to minimize unwanted AI outputs, ensuring responsible and controlled AI behavior.
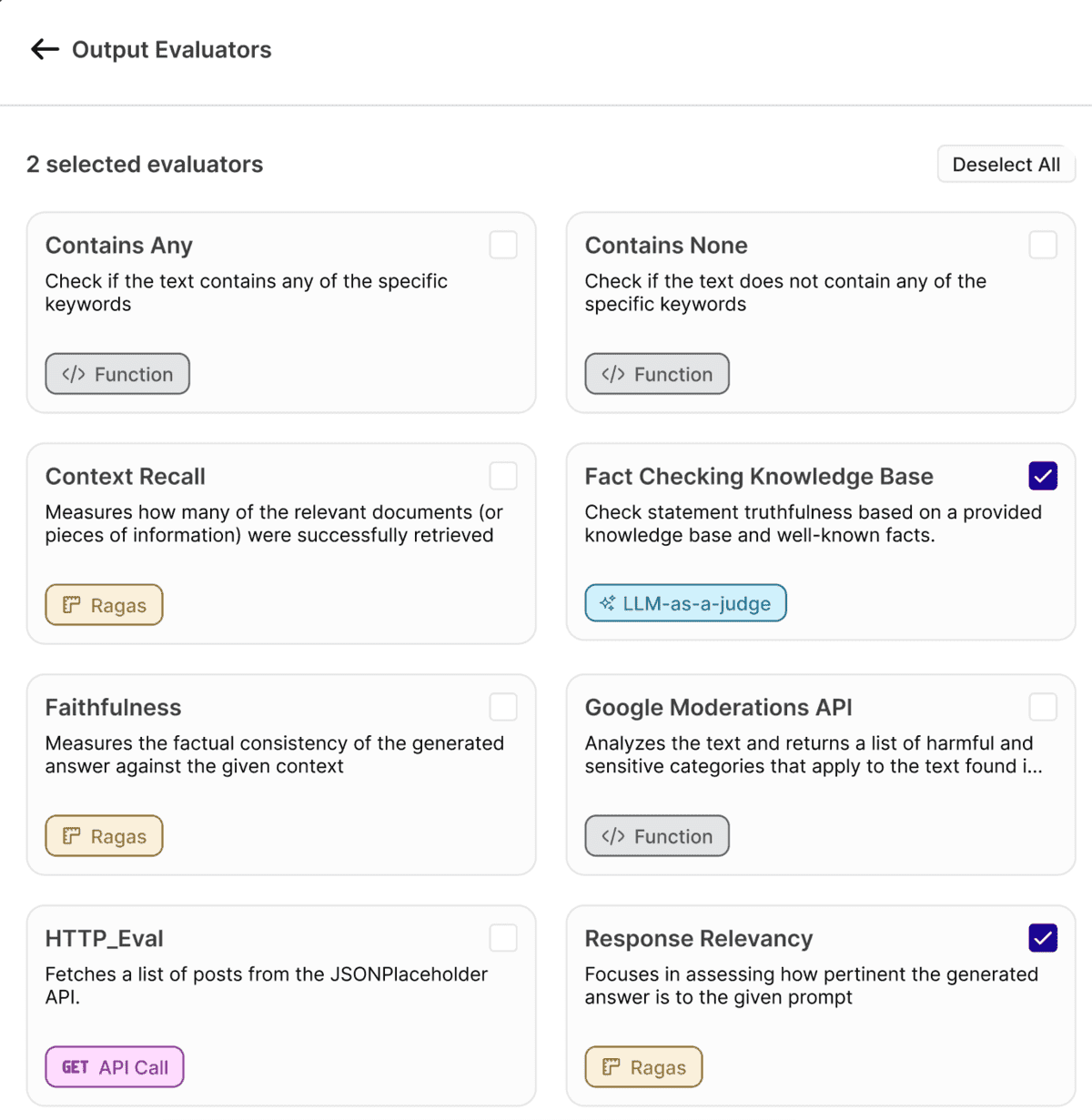
Snapshot of common evaluators in Orq.ai's Evaluator Library
Real-Time Monitoring & Optimization
Orq.ai's observability features provide real-time insights into your AI application's performance:
Dashboards & Reporting: Gain granular insights into cost, latency, token usage, and evaluation results through centralized dashboards, facilitating informed decision-making.
Experiment Analytics: Analyze and validate LLM interactions before deployment, using detailed logs to ensure compliance, security, and optimal system performance.
Human-in-the-Loop: Store and utilize human feedback on AI-generated responses, enabling continuous refinement and improvement of AI products.
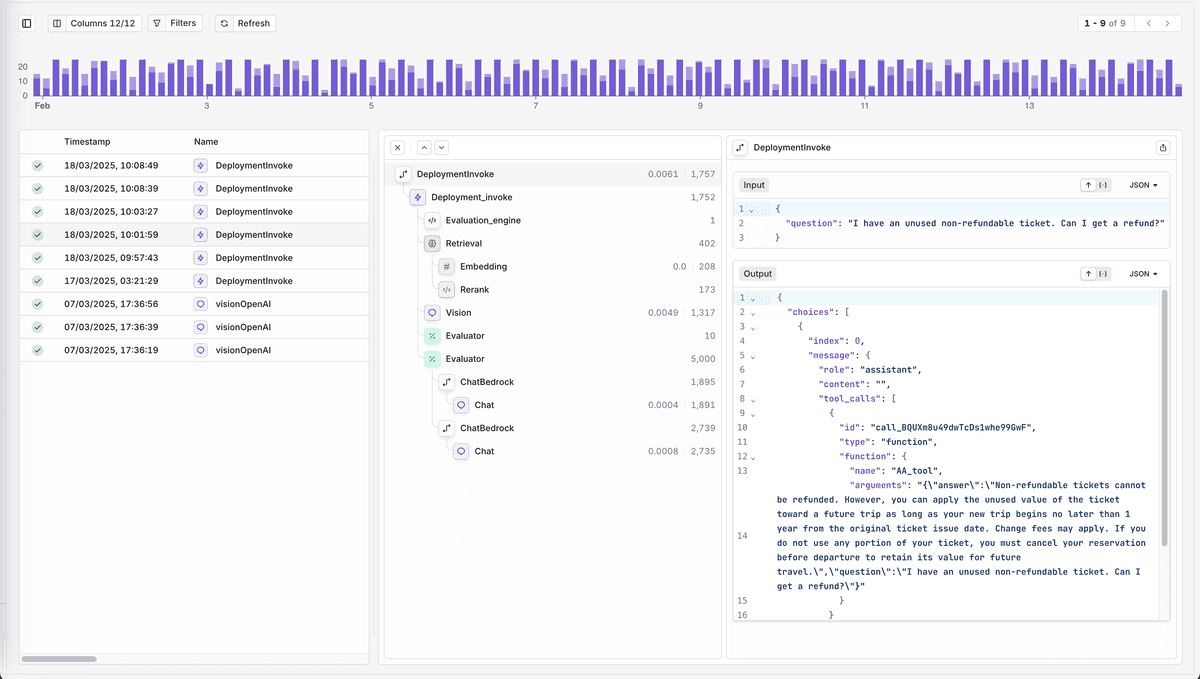
Overview of Traces in Orq.ai's Platform
Customizable Metrics & Seamless Integration
Orq.ai supports extensive customization and integration capabilities:
Custom Evaluators: Develop tailored evaluation metrics to align with specific project goals, ensuring assessments are relevant and comprehensive.
Extensive Model Support: Integrate seamlessly with over 130 AI models from leading providers, allowing flexibility in testing and deploying various model capabilities within a single platform.
Dataset Management: Build and manage curated datasets to benchmark performance, facilitating consistent and reliable evaluations. Orq.ai
By integrating these features, Orq.ai offers a comprehensive solution for evaluating and optimizing multi-agent LLM systems, ensuring robust performance and reliability throughout the AI development lifecycle.
Book a demo with our team to explore our platform’s agentic evaluation frameworks.
Multi Agent LLM Eval Systems: Key Takeaways
As multi-agent LLM systems become increasingly sophisticated, robust evaluation frameworks are essential for ensuring their efficiency, scalability, and reliability. From defining key evaluation metrics to implementing structured assessment pipelines, organizations must adopt a comprehensive approach to measuring multi-agent AI performance.
Existing tools like ChatEval, LangGraph, and DeepEval provide valuable insights, but they often lack the scalability and real-time adaptability required for multi-agent LLM eval systems. That’s where Orq.ai stands out, offering seamless integration, customizable evaluation metrics, and real-time monitoring to help teams build, optimize, and deploy reliable AI applications at scale.
In this article, we explored the fundamentals of multi-agent AI evaluation, the criteria for measuring success, leading tools in the space, and how Orq.ai delivers a more effective approach to multi-agent LLM assessments. As AI continues to evolve, having the right evaluation system in place will be critical for ensuring optimal performance and responsible deployment.

