









Multi-agent LLM systems are exactly what they sound like: AI architectures composed of multiple specialized agents, each typically powered by large language models (LLMs), working together to complete complex tasks. Instead of relying on a single LLM to perform an end-to-end workflow, these systems divide responsibilities among agents like planners, researchers, verifiers, and executors.
This modular structure aims to improve scalability, boost reasoning depth, and mimic collaborative human workflows. It’s a powerful concept with growing traction in the world of Generative AI. However, despite the hype, many teams are realizing that combining multiple systems doesn’t guarantee better results. These architectures often introduce new points of failure, both technical and organizational.
From poor task handoffs to systems failing to follow a normal conversational structure, the challenges are becoming more apparent as adoption increases.
In this article, we explore why multi-agent LLM systems fail, what kinds of system failures are most common, and how development teams can build more reliable, scalable LLM systems, especially when transitioning from prototype to production.
The Performance Gap: Expectations vs. Reality
On paper, multi-agent LLM systems promise modular intelligence, collaborative reasoning, and improved fault tolerance. In reality, however, performance benchmarks and operational feedback often paint a different picture.
Credits: Superannotate
When compared to single-agent setups, multi-agent architectures, despite their promise, can fall short on efficiency, reliability, and even accuracy.
Benchmark Evaluations
In controlled tests, many multi-agent systems have struggled to outperform strong single-agent baselines. For instance, while orchestrated agents in frameworks like MetaGPT or AG2 aim to simulate team-like collaboration among LLMs, their performance often degrades as coordination complexity increases.
Benchmark datasets assessing long-horizon planning or tool-use workflows have shown that single-agent systems, like OpenAI's o1, sometimes deliver better task completion rates due to fewer dependencies and a more streamlined information flow. This counterintuitive finding highlights a key limitation in generalizability: the more complex and dynamic the system, the harder it becomes to guarantee consistent outcomes across tasks and domains. In other words, complexity doesn't always translate to competence.
Real-World Case Studies
Looking beyond controlled tests, several case studies in production environments further illustrate this performance gap. According to a Reddit thread, one startup attempting to deploy a multi-agent research assistant using AG2 workflows found that task handoffs frequently failed due to prompt misalignment between agents. Despite modular design, the system’s verifier agent often rejected useful outputs due to differing criteria from the planner agent.
Another engineering team using MetaGPT for software generation noted that agents often misunderstood shared objectives, resulting in redundant code, versioning conflicts, or unnecessary tool invocations. Rather than increasing speed or flexibility, the multi-agent setup slowed them down, requiring manual oversight that negated much of the intended automation. This issue has been reported in several academic papers, such as one published by Michigan State University and the University of Arizona.
In both case studies, initial enthusiasm around modularity gave way to the realization that orchestration overhead and task fragility outweighed the theoretical benefits.
Generalizability
One of the key promises of multi-agent LLM systems is generalizability, which is the ability to adapt workflows and capabilities across varied domains. Yet, this is where many of them hit a wall. As seen in recent AG2 deployments, agent performance often degrades sharply outside the domain for which it was fine-tuned or scripted. Unlike single-agent systems that rely on a holistic understanding of task context, multi-agent systems depend on smooth inter-agent communication, which rarely translates well across use cases without custom prompt engineering or role redefinition.
In practice, this creates a paradox: the more general you want the system to be, the more specific the coordination rules you have to build. Without rigorous oversight and testing, generalizability remains an open challenge for scalable multi-agent deployment.
The Multi-Agent System Failure Taxonomy (MAST Framework)
To understand why multi-agent LLM systems (MAS) break down in practice, academics have introduced the MAST Framework, an acronym for Misalignment, Ambiguity, Specification errors, and Termination gaps.

Credits: LLM Watch
This framework distills over a dozen recurring failure modes reported across real-world applications, lab benchmarks like ProgramDev, and community experiments in environments such as AppWorld.
Specification & System Design Flaws
Before any agent is deployed, success hinges on how the system is framed. Many MAS failures stem from misalignment at the blueprint level.
Ambiguous or Conflicting Initial Instructions
If the initial goal or system prompt is under-specified or open to interpretation, agents will diverge in behavior. The lack of a shared context results in fragmented logic, inconsistent formats, and faulty execution plans. This is especially problematic in GAIA and AppWorld-style deployments where agent roles are not initialized with a unified task schema.
Improper Role Delineation Between Agents
Multi-agent systems rely on agent coordination to divide and conquer a task. But without clear functional boundaries, agents can end up duplicating effort or overriding each other. In some cases, agents assume similar roles (e.g., two “planners”), leading to endless loops or competitive behavior. Unlike single-agent frameworks, which maintain internal coherence, multi-agent setups demand strong role definitions, something that’s often overlooked.
Poor Decompositions of Tasks
Task decomposition is a key driver of performance gains in MAS, but only when done well. Many failure modes arise when planners assign subtasks that are either too granular, too broad, or not serializable. According to findings in the ProgramDev benchmark, poorly partitioned code generation tasks produced incoherent outputs that couldn’t be reintegrated, despite being technically “completed” by individual agents.
Inter-Agent Misalignment & Coordination Breakdowns
Once agents are live, the challenge becomes maintaining alignment in execution. A large portion of MAS failures can be traced to this stage.
Communication Ambiguity
Without standardized formats or message protocols, agents frequently misinterpret intermediate outputs. This leads to inter-agent misalignment, where one agent's "complete" response is unusable or confusing to the next. Studies in GAIA show that unclear agent-to-agent transfers drastically increase failure rates, especially in dynamic reasoning tasks.
Redundant or Circular Work
Another classic failure mode occurs when agents duplicate each other’s efforts, or worse, loop indefinitely. In the AppWorld environment, multiple agents tasked with information retrieval often re-fetched or re-analyzed the same data points, wasting compute and time. Logs of conversation traces revealed agents re-executing tasks due to misunderstood or mislogged status flags.
Uncoordinated Agent Outputs
Even if individual agents perform well in isolation, collective performance breaks down when outputs are incompatible. For example, a planner may assign steps in YAML while the executor expects JSON. These small mismatches cause cascading errors that undermine the entire workflow. Modern approaches like LLM-as-a-Judge pipelines attempt to catch these problems, but are still brittle compared to oversight by expert human annotators.
Task Verification & Termination Gaps
A final class of failure modes involves how systems validate work and decide when a task is finished.
Lack of Oversight or Judge Agents
Without a referee, human or LLM-based, no agent is responsible for ensuring the overall correctness of outputs. This leads to workflows where incorrect or incomplete results go unchecked. The LLM-as-a-Judge pipeline, while promising, still lags behind expert human annotators in reliability, especially on complex or subjective tasks.
Inadequate Termination or Loop Detection
Poor stop conditions cause agents to continue running far beyond their useful window. This is common in AG2 workflows, where agents continue to "reason" long after a goal has been reached, often generating unnecessary subtasks. Robust termination logic is still an open problem in MAS research.
Poor Error Handling, Memory Decay
Many agents don’t retain long-term memory or robust error states. As a result, when something goes wrong, whether it's an API failure or a missing tool response, agents may retry indefinitely or silently fail. In one case study from the AppWorld test suite, the absence of retry limiters led to runaway costs in a task designed to complete in under 10 seconds.
Underlying Causes & Cross-Cutting Issues
While it’s tempting to treat each failure mode in multi-agent LLM systems as isolated, the truth is more complex.

Credits: Medium
Beneath the surface lies a network of cross-cutting issues that amplify risk and degrade performance across seemingly unrelated workflows. Understanding these root causes is essential for any team looking to move from experimentation to production.
Compounding Errors
In multi-agent workflows, one small mistake rarely stays small. A single misinterpreted message or misrouted output early in the workflow can cascade through subsequent steps, leading to major downstream failures. This pattern, where small specification issues or minor role ambiguities snowball into systemic breakdowns, is well-documented in systematic analysis of tool-using agents and long-horizon planning environments.
For example, a slightly off-target task decomposition from a planning agent might result in irrelevant search queries, which in turn feed unusable data to a summarizer, leading the verifier to reject a response entirely. This is the essence of the multi-agent systems problem: performance is only as strong as the weakest link in the chain.
Misaligned Goals & Incentive Structures
Multi-agent systems are designed to mimic team-based collaboration, but without proper alignment of task objectives, they behave more like competing silos than cohesive units. In practice, agents often "optimize" for subgoals that don't align with the overarching mission, a phenomenon similar to specification gaming in reinforcement learning. One agent might aggressively shorten outputs to meet a token limit, while another expects exhaustive detail, creating a silent failure state.
These goal mismatches are often baked into the initial prompt engineering or organizational design of the system, especially when agent goals are defined independently. A recurring lesson from high-fidelity environments like GAIA is that agents need not only technical interoperability but shared intent and success criteria.
Trust, Security & Legal Concerns in Multi-Agent Contexts
When agents collaborate, they often operate with partial autonomy, API access, and execution privileges, raising red flags around security and trust. Without centralized control or robust audit trails, systems can be exploited or misused, even unintentionally. For example, a verifier agent misclassifying a harmful suggestion as benign, due to limited context or degraded memory, could lead to reputational or legal consequences.
This concern becomes more pressing in sensitive domains like healthcare or finance, where even low-frequency errors can have high-stakes outcomes. Establishing secure execution boundaries and introducing scalable evaluation frameworks to detect these blind spots is crucial for long-term viability.
One promising solution here involves dual annotation pipelines where expert human annotators are paired with LLM judges, and agreement is measured using metrics like Cohen’s Kappa score to identify ambiguous or contested outputs across agents.
Scalability Complexities: Coordination and Source Diversity
Finally, even if a multi-agent system functions well at a small scale, scaling it introduces new layers of complexity. As agent counts increase and heterogeneous agent sources are introduced (e.g., combining OpenAI models with OSS agents like OpenHermes or Claude), maintaining consistent behavior becomes a major challenge.
Coordination bottlenecks often emerge when agents must queue for shared tools or synchronize over limited memory bandwidth. Meanwhile, inconsistencies in capabilities or styles between agents create friction in collaborative reasoning. Without enforced format standards, shared context, and dynamic role adaptation, these growing pains compound quickly.
In other words, scaling MAS isn’t just about compute and APIs: it’s about redesigning the system to ensure coherence under growth.
Orq.ai: Agentic AI Engineering & Evaluation Platform
Orq.ai is a Generative AI Collaboration Platform that helps software teams design, deploy, and optimize agentic LLM systems at scale. As organizations move beyond single-agent use cases, they’re quickly discovering that multi-agent systems introduce unique architectural, operational, and collaboration challenges that traditional DevOps tooling isn’t equipped to solve.
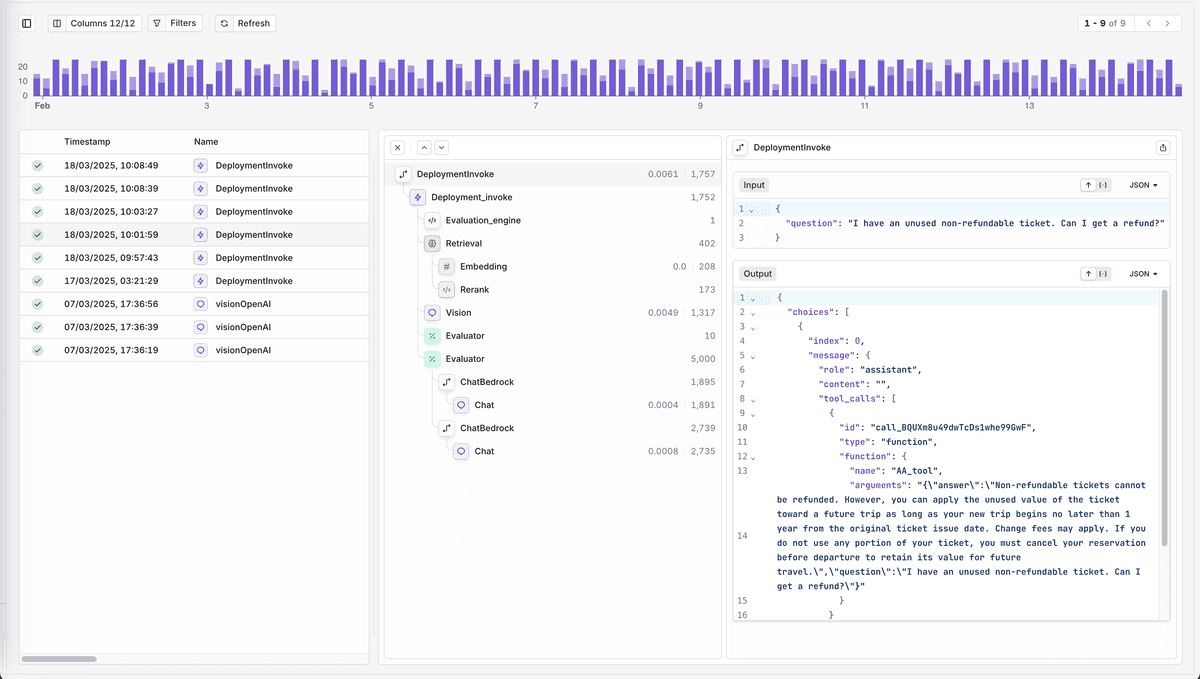
Overview of Traces in Orq.ai's Platform
That’s where Orq.ai comes in. By offering out-of-the-box tooling in a user-friendly interface, Orq.ai empowers both developers and non-technical stakeholders to build reliable, multi-agent workflows from the ground up, debug system behavior, enforce quality standards, and continuously improve system performance in production.
Here’s an overview of how Orq.ai supports multi-agent LLM systems:
Generative AI Gateway: Connect to 200+ models from OpenAI, Anthropic, Azure, and more. Build agent stacks using best-fit models per role; e.g. planning with Claude, verifying with GPT-4o, all orchestrated through a unified control panel.
Playgrounds & Experiments: Rapidly test agent interactions, role assignments, and system prompts in sandboxed environments. Simulate turn-by-turn agent conversations, run isolated experiments on agent role performance, and detect early signs of inter-agent misalignment before deployment.
Evaluators: Use RAGAS, LLM-as-a-Judge pipelines, or custom metrics to monitor and evaluate complex multi-agent exchanges. Define evaluators that score agent responses based on accuracy, coherence, completeness, or alignment with overall system goals. This is crucial to validate collaborative output.
Deployments: Move seamlessly from prototype to production with controlled handoffs, output validators, fallback logic, and loop detection. Ensure robust performance even in AGI-adjacent workflows where autonomy and unpredictability are high.
Observability & Evaluation: Visualize conversation traces across agents, pinpoint compounding errors, and correlate them with system metrics like cost, latency, or task success. Orq.ai brings transparency to agent coordination, surfacing subtle sources of system failure before they spiral into production issues.
Security & Privacy: Operate safely at scale with SOC2 certification and full compliance with GDPR and the EU AI Act. Perfect for enterprises experimenting with multi-agent models in high-stakes domains like finance, legal, or healthcare.
Create a free account to explore Orq.ai’s capabilities in action or book a demo with our team to learn how we support complex agentic workflows.
Multi-agent LLM System Failures: Key Takeaways
The vision behind multi-agent LLM systems is powerful: modular AI agents collaborating to solve complex tasks with greater autonomy, depth, and scalability. But in practice, the road to realizing that vision is paved with failures; from brittle task handoffs and misaligned goals to poor termination logic and inefficient coordination.
Through the MAST (Multi-Agent System Failure Taxonomy), it has been determined that these challenges are not isolated glitches; they’re deeply systemic. Many breakdowns stem from upstream specification flaws, weak role definitions, and inadequate oversight mechanisms, all of which become amplified in multi-agent contexts. Others are the result of overlooked inter-agent misalignment, insufficient error detection, and coordination overload as systems scale.
Overcoming these hurdles requires more than model fine-tuning or better prompts. It calls for a combined technical and governance-driven approach: tooling that can support iterative design, scalable evaluation, and robust orchestration, paired with disciplined processes around prompt engineering, agent evaluation, and collaborative debugging.
This is where frameworks like MAST, methodologies such as Grounded Theory, and platforms like Orq.ai come into play. By enabling teams to trace, analyze, and act on multi-agent system behaviors in real time, they transform complexity into clarity and failure into feedback.
As multi-agent workflows continue to evolve from prototype concepts into enterprise-critical infrastructure, investing in strong foundations now will be the difference between fragile demos and production-grade success.
Ready to reduce failure and build for scale? Explore how Orq.ai empowers teams to operationalize reliable agentic systems today.
FAQs
What are multi-agent LLM systems, and how do they work?
Multi-agent LLM systems are AI architectures composed of multiple specialized agents, each typically powered by large language models, working collaboratively to complete a complex task. Each agent is assigned a distinct role (e.g., planner, researcher, verifier), and together they pass information between one another in an agentic workflow. These systems aim to improve modularity, reasoning depth, and scalability, but they introduce new coordination and evaluation challenges that don't exist in single-agent setups.
Why do multi-agent LLM systems fail more often than single-agent systems?
Multi-agent systems often fail due to compounded errors across agents, poor task decomposition, communication breakdowns, and inter-agent misalignment. Each agent may interpret goals or prompts differently, leading to contradictory outputs or infinite loops. Unlike single-agent frameworks, these systems must manage multiple decision points and dependencies, making them more fragile without proper orchestration, oversight, and termination mechanisms.
What is the MAST framework, and how does it help?
The MAST (Multi-Agent System Failure Taxonomy) framework organizes common failure modes into three main categories: Specification flaws, Agent misalignment, and Termination gaps. It helps teams perform a systematic analysis of why their agentic workflows break down, guiding improvements in system architecture, agent design, and evaluation pipelines. MAST is particularly useful for debugging complex systems in production.
Can better prompts fix multi-agent system failures?
Improved prompts can reduce some errors, but prompt tuning alone rarely resolves deeper structural issues. Most multi-agent systems problems stem from architectural weaknesses, inconsistent agent incentives, or flawed task objectives. To reduce failures, teams must focus on holistic design, including governance processes, robust evaluation, and tools like Orq.ai that offer scalable evaluation and observability across agent workflows.
How can I make my multi-agent LLM system more reliable?
To build reliable multi-agent systems, start with clear role definitions, well-structured task decomposition, and strong verification logic. Use platforms like Orq.ai for integrated experimentation, traceable evaluations, and production-grade deployment. Incorporating feedback loops, LLM-as-a-Judge pipelines, and benchmarks like ProgramDev can help maintain output quality over time.

