
Log
Observe
Improve

Tracing
Trace every AI interaction from prompt to response
Orq.ai captures every LLM call, tool action, and agent step mapped into clear, navigable traces. Explore execution paths, inspect tokens, review prompts, and understand exactly how your AI reached its final output.
Execution paths
token-level insight
spans
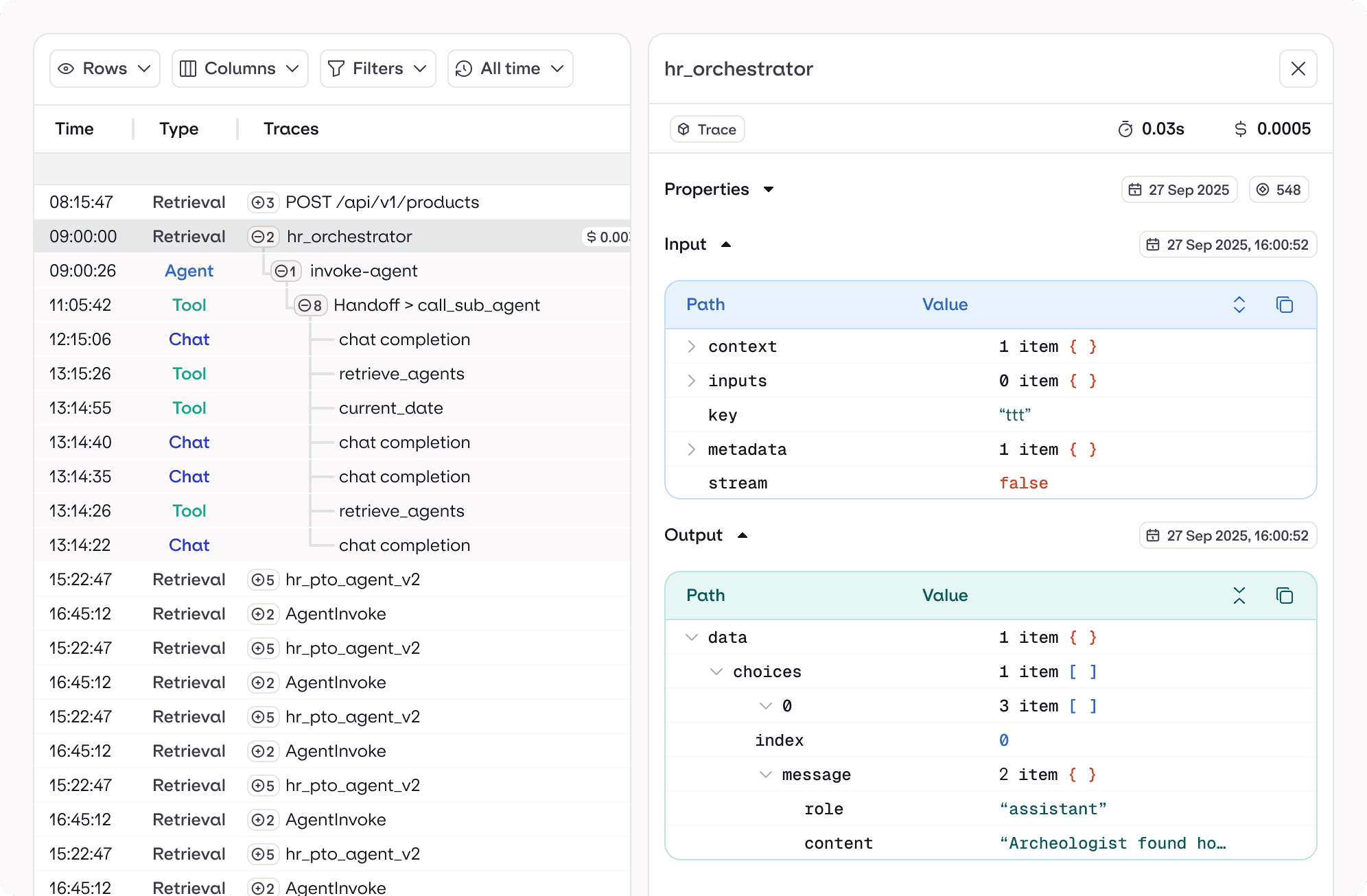
Custom events
Tool use
Enriched metadata
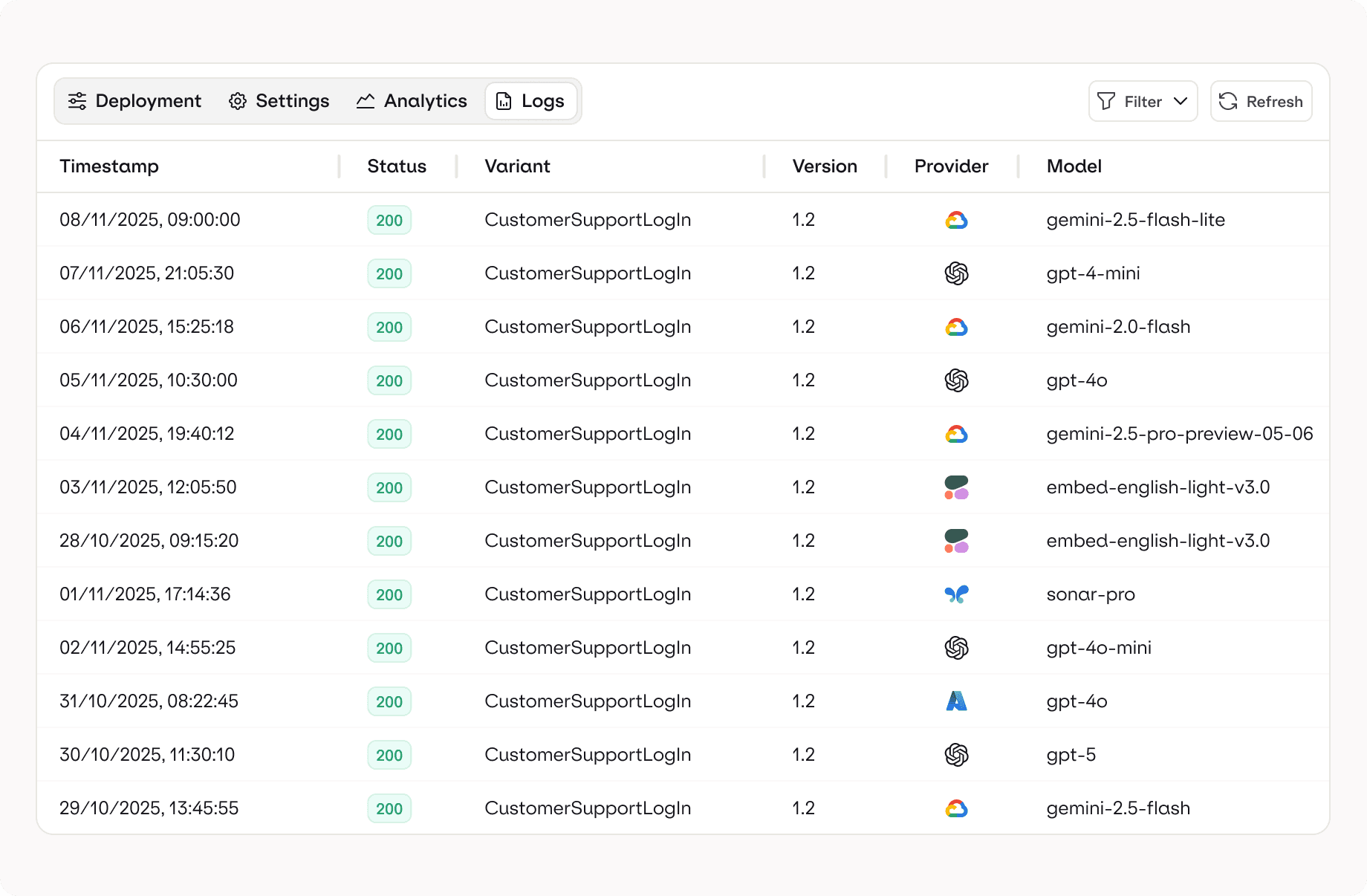
Advanced TRACING
Trace everything that matters automatically
Add custom events, metadata, user IDs, or request context. Orq.ai enriches logs with timings, costs, model details, and system state so debugging and analysis become effortless.
Smart Automation Rules
Turn observability into automated action
Set rules that trigger workflows when specific patterns appear: slow responses, hallucinations, toxic output, or model failures. Orq.ai’s trace automation lets you reroute requests, flag regressions, or notify teams instantly.
Annotation queue
dataset curation
online evaluators
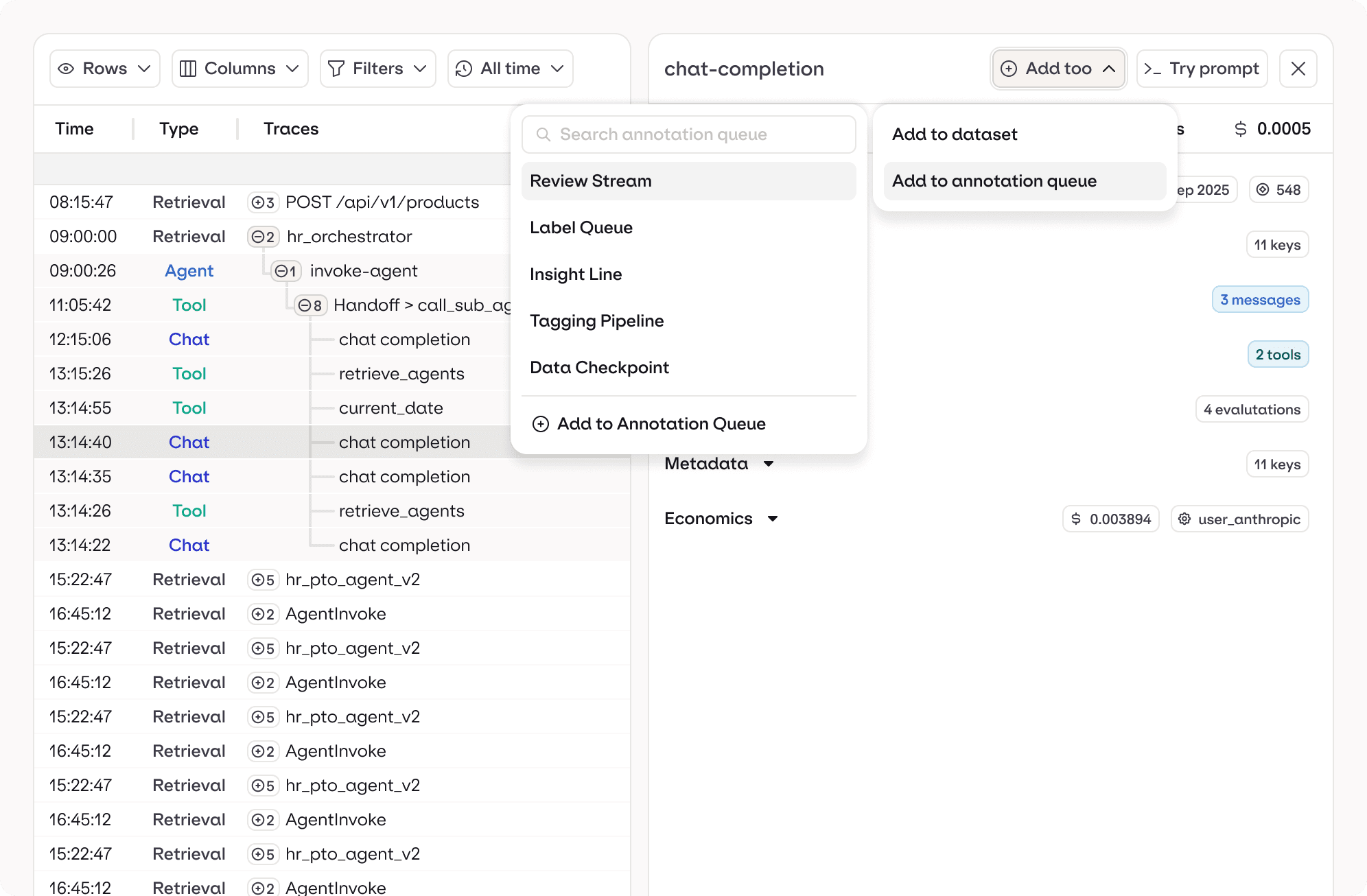
Live Insights
Drift monitoring
Custom reports
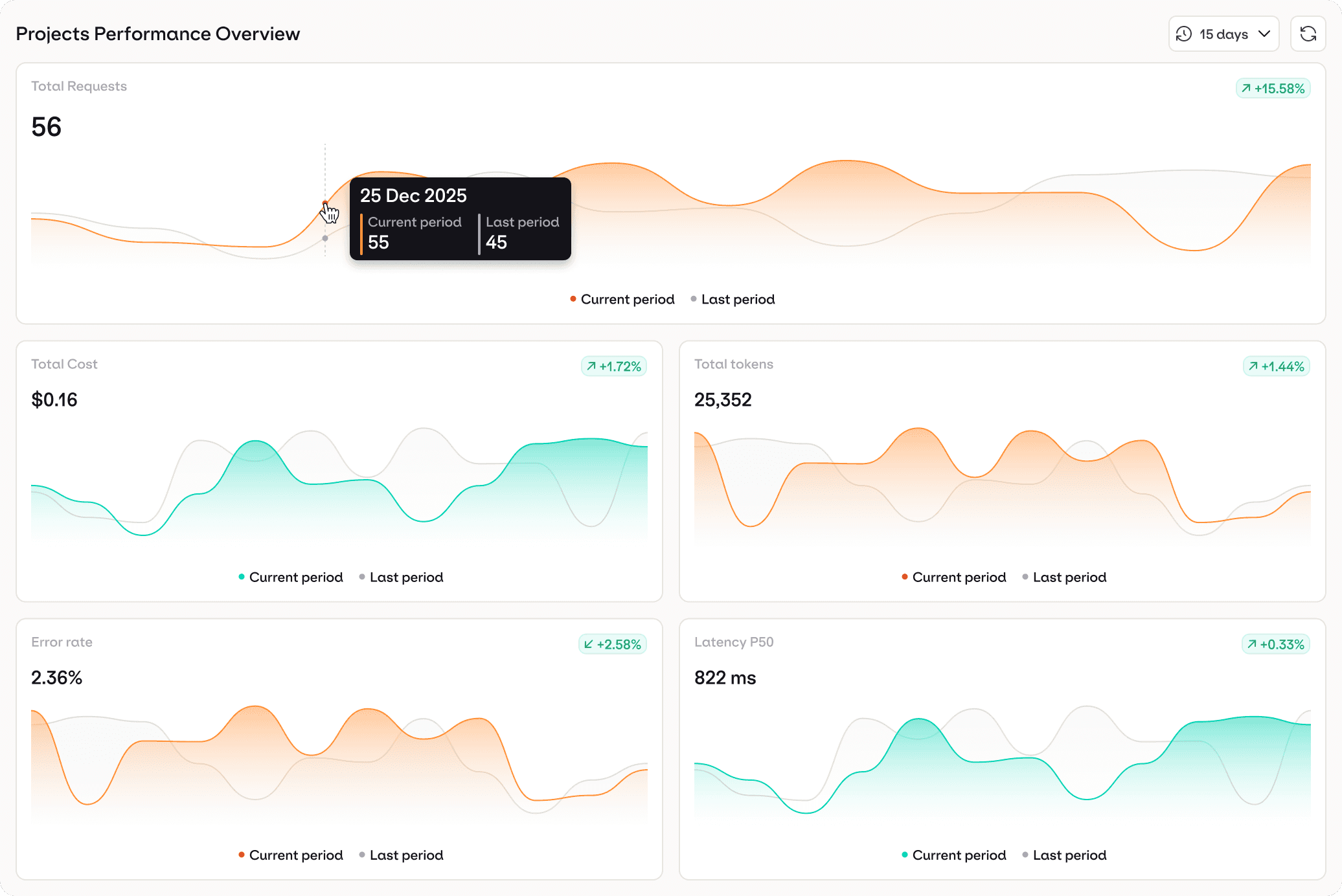
Dashboards & Analytics
Monitor health, performance, and costs in real time
Get built-in dashboards for latency, errors, token usage, routing efficiency, and drift. Create custom reports or dig into deployment-level analytics to understand how your AI performs in the real world.
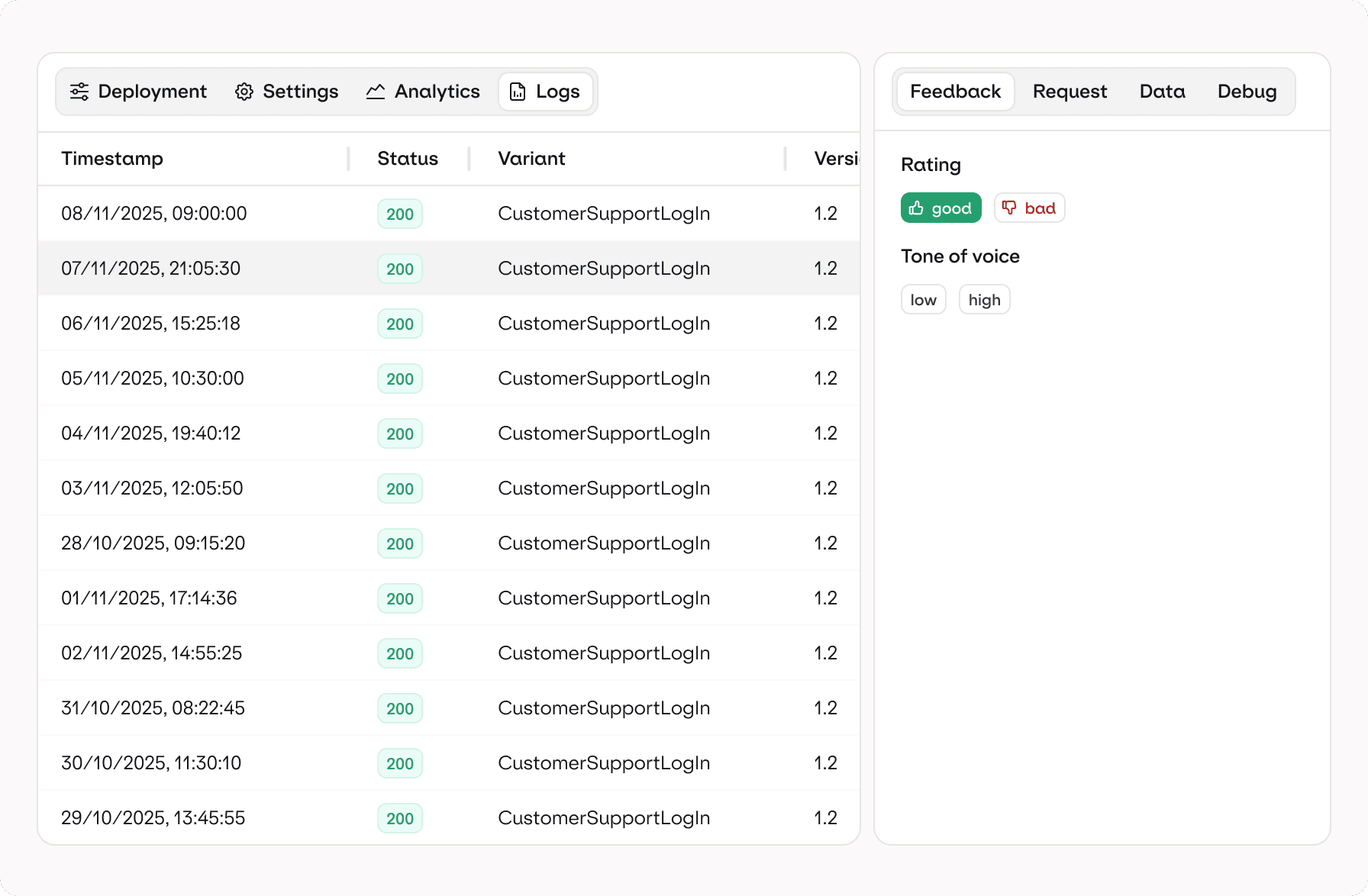
Feedback Loops
Capture feedback and feed it back into your AI pipeline
Let users rate responses or flag issues. Orq.ai logs feedback directly into the trace, powering evaluation loops, retraining workflows, and continuous AI improvement.
User Feedback
human evals
annotations
Logging Policies
Retention rules
Compliance ready
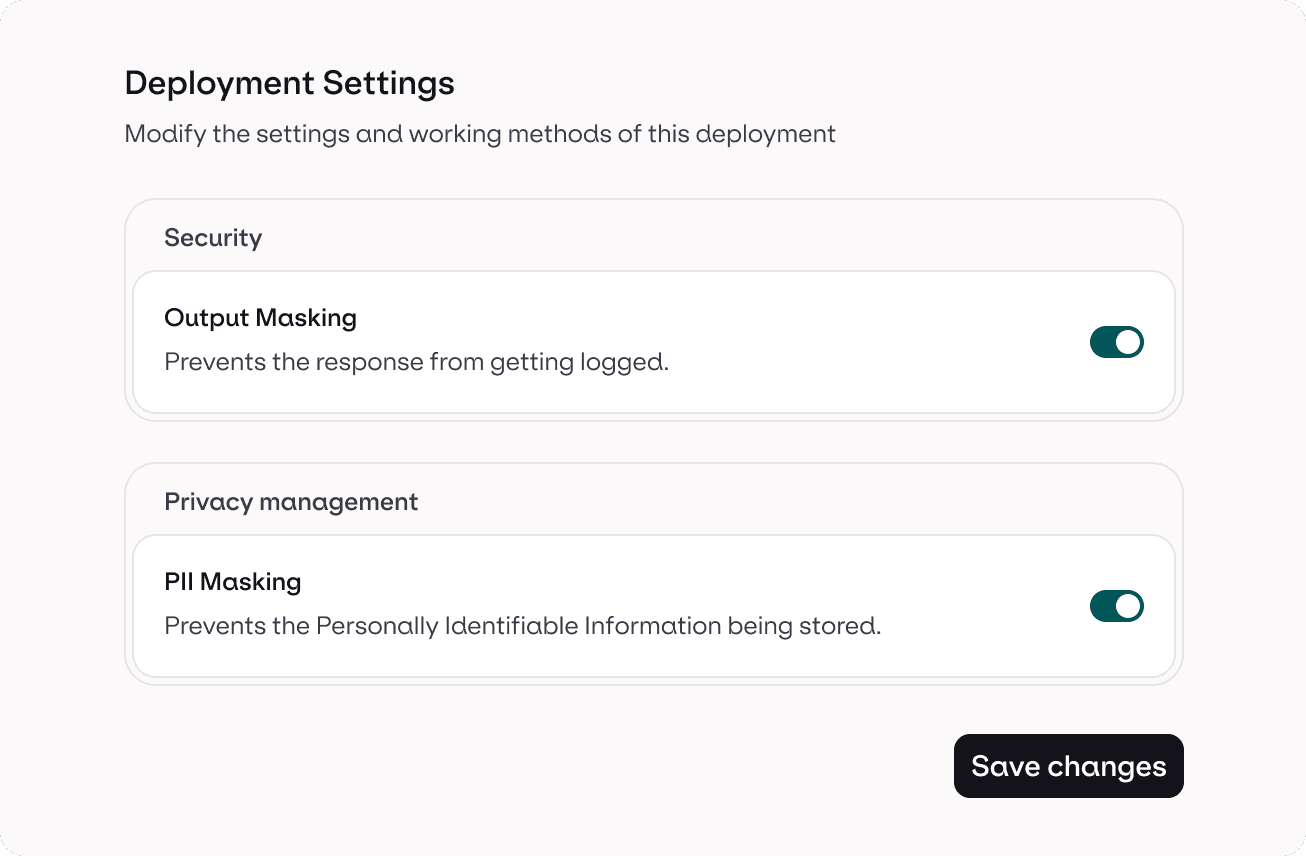
Data & Privacy Management
Control what you capture and what you don’t
Define privacy rules, manage retention policies, and choose what’s stored or anonymized. Orq.ai keeps logs transparent and compliant while preserving the insight you need to debug and monitor production AI.
Redaction rules
Auto-masking
Secure logging
Privacy-First Logging
Keep sensitive data out of your logs automatically
Enable built-in PII and sensitive data masking to remove names, emails, addresses, IDs, and more. Your observability stays useful without exposing private or regulated data.
OpenTelemetry
libraries
openai compatible
SDK-Ready Observability
Connect your stack instantly with zero friction
Orq.ai integrates with OpenTelemetry, LangChain, Autogen, OpenAI Agents, and Google AI SDKs. Drop in a snippet and Orq.ai captures traces, logs, events, and metrics automatically - no rewrites required.
Platform Solutions
Discover more solutions to build reliable AI products
Integrates with your stack
Works with major providers and open-source models; popular vector stores & frameworks.

Assurance
Compliance & data protection
Orq.ai is SOC 2-certified, GDPR-compliant, and aligned with the EU AI Act. Designed to help teams navigate risk and build responsibly.
Flexibility
Multiple deployment options
Run in the cloud, inside your VPC, or fully on-premise. Choose the model hosting setup that fits your security requirements.
Enterprise ready
Access controls & data privacy
Define custom permissions with role-based access control. Use built-in PII and response masking to protect sensitive data.
Transparency
Flexible data residency
Choose from US or EU-based model hosting. Store and process sensitive data regionally across both open and closed ecosystems.
FAQ
Frequently asked questions
What is LLM observability, and why is it important?
LLM observability refers to the comprehensive monitoring and analysis of large language model (LLM) applications. It provides visibility into various components, including prompts, responses, data sources, and system performance. This observability is crucial for ensuring the accuracy, reliability, and efficiency of LLM-powered applications. By implementing observability practices, teams can detect anomalies, troubleshoot issues, and optimize performance, leading to more robust and trustworthy AI systems.
How does LLM observability differ from traditional monitoring?
While traditional monitoring focuses on tracking predefined metrics like CPU usage or error rates, LLM observability delves deeper into understanding the behavior of LLM applications. It encompasses tracing the flow of data through the system, analyzing prompt-response interactions, and evaluating the contextual relevance of outputs. This holistic approach enables teams to identify root causes of issues, such as hallucinations or biases, that traditional monitoring might overlook.
What features should I look for in a platform offering LLM observability?
When evaluating tools for LLM observability, it's important to look for features that provide deep visibility into your application's behavior and performance. A robust observability platform should include:
Tracing and Debugging Tools: These let you follow each request and response through your LLM pipeline, making it easier to pinpoint where problems occur.
Detailed Logging: Comprehensive logs help you understand how your system handles prompts, how data flows, and where things might break down.
Automated and Manual Evaluations: Look for support for both rule-based and human-in-the-loop evaluations to assess response quality, relevance, and correctness.
Performance Monitoring: Metrics like latency, throughput, and token usage are critical for understanding how your LLM application performs at scale.
Prompt and Response Analytics: Analyzing inputs and outputs over time can help refine prompt engineering and identify patterns in model behavior.
Data Privacy Controls: Especially important for production environments, these ensure compliance and protect sensitive user data.
Platforms like Orq.ai bring all of these capabilities together, allowing teams to build, operate, and iterate on LLM applications with confidence.
How can LLM observability improve the performance of AI applications?
By providing insights into the inner workings of LLM applications, observability enables teams to identify and address issues that affect performance. For instance, tracing can reveal inefficient prompt structures, while output evaluations can highlight areas where the model's responses lack relevance or accuracy. Addressing these issues leads to more efficient, accurate, and user-friendly AI applications.
What tools and features does Orq.ai offer for LLM observability?
Orq.ai provides a suite of tools designed to enhance LLM observability:
Tracing: Visualize the flow of data through LLM applications to identify and troubleshoot issues.
Advanced Logging: Collect and analyze detailed logs to gain insights into system behavior.
Evaluator Library: Utilize built-in and custom evaluators to assess the quality of LLM outputs.
Dashboards: Monitor key performance indicators in real-time to track system health and performance.
User Feedback Mechanisms: Gather and analyze user feedback to inform improvements.
Data Privacy Management: Implement safeguards to protect sensitive information and ensure compliance with data protection standards.
Integrations
Integrate Orq.ai with 3rd party frameworks.

AI Gateway
Connect to your favorite AI models, or bring your own. Unified in a single API.

SDKs & API
Get started with one line of code. API access for all components.

Cookbooks
Speed up your delivery with detailed guides.

