









Large Language Models (LLMs) have significantly impacted natural language processing (NLP), enabling machines to understand and generate human-like text.
However, the complexity of these models necessitates effective monitoring and debugging mechanisms to ensure optimal performance. This is where LLM tracing becomes essential.
In this article, we will explore the concept of LLM tracing, its significance, the methodologies involved, and how platforms like Orq.ai facilitate efficient tracing processes.
Understanding LLM Tracing
What is LLM Tracing?
LLM tracing is the process of monitoring and analyzing how a Large Language Model processes inputs, makes predictions, and generates outputs. By tracking each step in the model’s execution, developers gain visibility into its decision-making processes, allowing for more effective debugging, optimization, and evaluation.
At its core, LLM tracing enhances LLM monitoring, providing insights into key components such as embeddings, tokenization, and attention layers. It allows developers to trace how an input prompt flows through various layers of the model, influencing the final response. This granular view of execution is essential for root cause analysis, helping teams identify inefficiencies, unexpected biases, or model drift.

Credits: Fiddler AI
LLM tracing is closely related to application tracing, a concept widely used in software engineering to monitor distributed systems. Just as developers use tracing to track API requests and latency in microservices, LLM tracing helps map out how prompts are processed within language models.
By leveraging LLM tracing, teams can ensure that their models operate efficiently, produce accurate outputs, and adhere to safety and performance standards.
The Purpose and Benefits of LLM Tracing
Debugging and Monitoring
One of the primary benefits of LLM tracing is its ability to aid in debugging and monitoring complex models. By tracking how inputs are processed at each stage, from prompt templates to final outputs, developers can identify inefficiencies, detect runtime exceptions, and refine model behavior.
Tracing also enables performance monitoring, allowing teams to assess response times, token utilization, and overall computational efficiency. This is particularly useful in environments leveraging serverless functions, where optimizing compute resources is crucial. Additionally, techniques like batching can be evaluated to determine their impact on performance, ensuring that grouped queries execute efficiently.
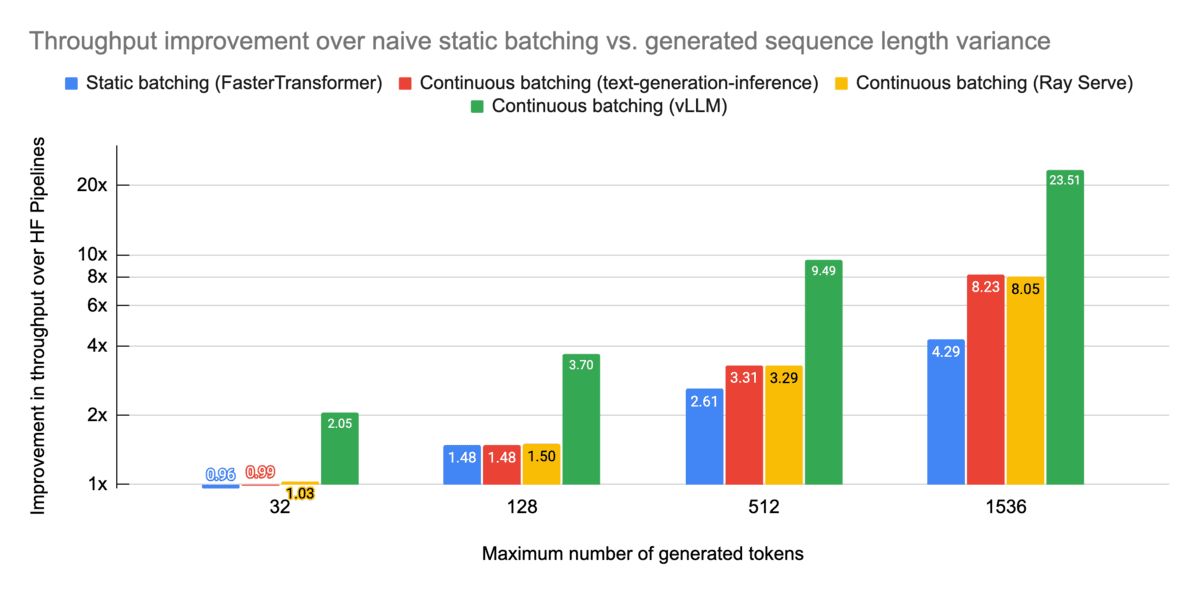
Credits: AnyScale
For large-scale applications, distributed tracing plays a key role in tracking interactions across multiple services and APIs, providing end-to-end visibility into an LLM’s execution pipeline.
Bias Detection and Ethical Compliance
Bias detection is critical in LLM applications, where unintended model biases can lead to skewed or ethically problematic outputs. By tracing model decisions, teams can analyze how retrieved documents, training data, and LLM parameters influence predictions, making it easier to pinpoint sources of bias.
Tracing also supports prompt management, ensuring that predefined inputs generate fair and accurate responses. In regulated industries, these insights help enforce ethical guidelines and safety constraints, ensuring compliance with industry standards.
Performance Optimization
LLM tracing provides quality insights that inform iterative improvements, leading to enhanced performance and accuracy. By continuously analyzing tracing data, teams can fine-tune hyperparameters, improve dataset creation, and optimize response generation.
Furthermore, framework support for tracing tools allows teams to integrate best practices across different AI platforms, ensuring seamless model evaluation and refinement.
How Does LLM Tracing Work?
Input Processing
The tracing process begins with analyzing how an LLM processes incoming text. This includes tokenization, where raw text is broken down into smaller units, and embedding generation, which transforms tokens into numerical representations.
By tracing input handling, developers can assess token usage to optimize cost efficiency and cost monitoring strategies. Additionally, insights from tracing help refine causality tracing, ensuring that input-output relationships are well understood in complex workflows.
Model Layer Analysis
Once inputs are processed, they pass through multiple layers within the model, including attention mechanisms and feedforward networks. Tracing each layer’s computations provides visibility into the model inference pipeline, revealing how different components interact to produce a response.
Credits: Enterprise Knowledge
Developers often use nested traces to break down computations at various depths, allowing for a detailed understanding of attention scores, activation functions, and intermediate states. By monitoring these layers, teams can diagnose inefficiencies, improve response quality, and ensure alignment with expected behavior.
Output Examination
The final output of an LLM is determined by multiple post-processing steps, including logit computation, probability distributions, and decoding mechanisms. Tracing helps evaluate how outputs are generated and whether they align with expectations.
Key factors to assess include LLM function calls, where external APIs or tools may be invoked to enhance response generation, and application latency, which measures the time taken to produce an output. In real-time applications, minimizing delays is crucial for user experience and scalability.
Gradient Flow Monitoring (Training Phase)
During training, backpropagation updates model weights based on error gradients. Gradient flow monitoring ensures that learning progresses smoothly without issues like vanishing or exploding gradients.
Techniques such as event queuing help manage updates efficiently, while methods like the flush method ensure that stale or redundant gradient data is removed from computation buffers. These optimizations improve learning stability, leading to better-trained models.
Tools and Platforms for LLM Tracing
Several LLM tracing tools are available to help teams monitor, debug, and optimize their models. Below are some of the most widely used platforms for LLM application tracing:
LangSmith: Offers comprehensive logging, real-time monitoring, and detailed visualizations. Integrated with LangChain, it enables seamless LLM agent tracing for debugging complex workflows.
Arize Phoenix: The Arize LLM tracing platform provides extensive visualization of LLM predictions, supports multiple frameworks, and includes performance analysis tools for improved model evaluation. Many developers turn to Phoenix LLM tracing for deep observability.
Helicone: An LLM tracing open-source tool providing real-time monitoring, detailed logging, and a generous free tier.
Langfuse: Focused on observability, metrics, and prompt management, this open-source tool enables teams to track and optimize LLM responses effectively.
HoneyHive: Known for its user-friendly interface, this tool simplifies performance monitoring and comprehensive logging for teams that need intuitive tracing solutions.
MLflow: While primarily an ML lifecycle management tool, MLflow LLM tracing offers integrations for tracking model runs, logging parameters, and visualizing LLM performance over time.
Datadog: A popular enterprise observability platform, Datadog LLM tracing provides real-time application monitoring, tracing, and infrastructure insights. It is widely used in production environments but may require significant setup.
While these tools provide valuable insights, they may not be ideal for all teams. Some platforms require extensive configuration, while others, like MLflow LLM tracing, are better suited for experiment tracking rather than real-time tracing. Datadog LLM tracing, on the other hand, offers robust monitoring but can be complex to integrate for AI-specific use cases. Additionally, tools focused on LLM knowledge tracing or LLM agent tracing may not provide the immediate insights needed for rapid iteration and optimization.
For teams seeking an all-in-one solution, Orq.ai offers end-to-end LLM observability, combining tracing, performance monitoring, and real-time control in a single platform.
LLM Tracing with Orq.ai
Orq.ai is a Generative AI Collaboration Platform designed to help software teams build, ship, and optimize LLM applications at scale. With robust LLM observability features, Orq.ai ensures that teams can monitor model behavior, troubleshoot issues, and continuously improve performance — all within a user-friendly interface.
At the core of Orq.ai’s LLM tracing tools is Traces, a feature that enables teams to map every interaction within their LLM pipelines. Whether tracking token usage, analyzing response latency, or identifying bottlenecks, Traces provide granular insights into LLM performance. To further enhance real-time debugging, Orq.ai offers detailed logging, allowing users to pinpoint and resolve issues efficiently.
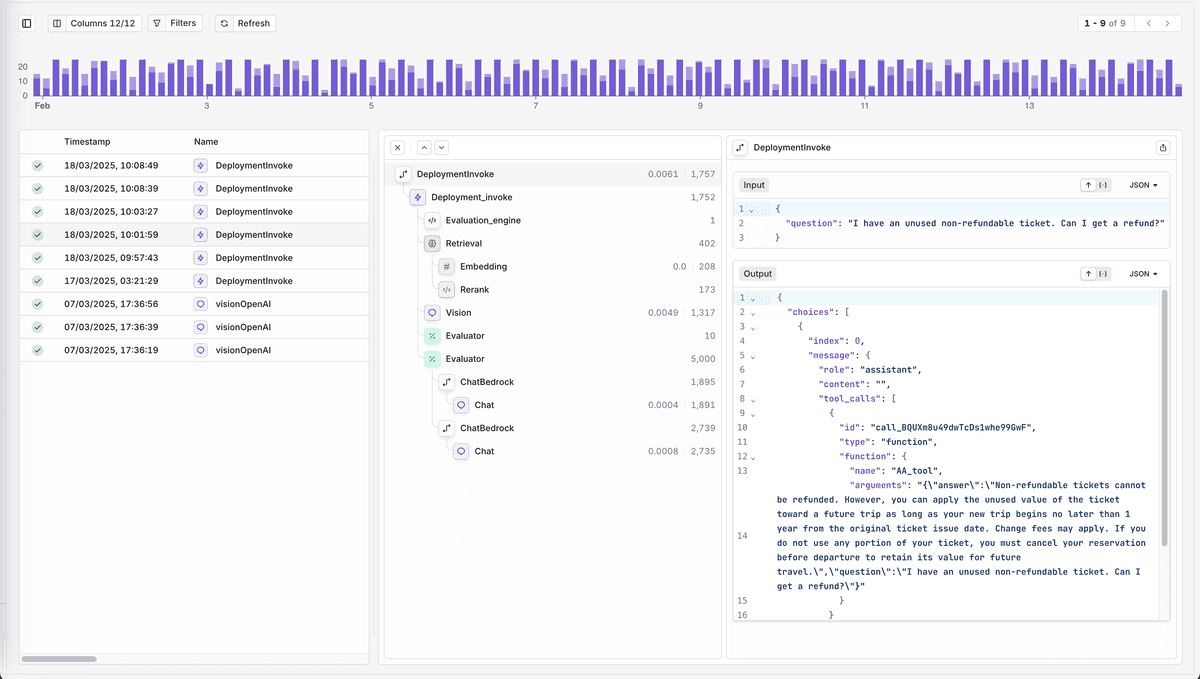
Overview of Traces in Orq.ai's Platform
Some of the key LLM Observability capabilities provided through Orq.ai’s platform include:
Traces: Orq.ai’s Traces feature maps all interactions within the LLM pipeline, providing full visibility into the flow of data and model behavior. It tracks the input-to-output process, ensuring that every step is observable and debuggable.
Advanced Logging: Detailed logs capture key events such as model errors, token usage, and latency. This logging helps teams troubleshoot and debug LLM chains, ensuring smooth operation and quick identification of issues.
Intuitive Dashboards: Orq.ai offers interactive dashboards that visualize key operational metrics, including token usage, response times, and performance metrics. These dashboards give teams a clear, real-time view of how their models are performing.
Evaluator Library: The Evaluator Library allows teams to test and evaluate various LLM configurations, including prompt setups and RAG pipelines. This feature helps fine-tune models to enhance accuracy and improve response quality.
User Feedback Logs: Capture and analyze user feedback logs to understand where LLMs may be underperforming. This data enables continuous model improvement and ensures the LLM is delivering the most accurate and relevant responses.
Security Features: Orq.ai prioritizes security with PII detection, data masking, and SOC-2 compliance to prevent the accidental exposure of sensitive information during the LLM tracing process.
These features, combined with Orq.ai’s ease of use and seamless integration into existing workflows, allow teams to achieve better observability, enhanced debugging, and optimized LLM performance.
Book a demo with our team to learn more about our platform’s LLM observability offering today.
LLM Tracing: Key Takeaways
LLM tracing is a critical component of optimizing and ensuring the reliability of large language models. By providing transparency into model behavior, tracing helps teams debug issues, detect biases, and fine-tune performance at scale. As LLM applications continue to evolve, the need for robust observability and real-time monitoring will only grow.
With tools like Orq.ai, software teams can access powerful tracing capabilities to seamlessly integrate into their development workflows. From tracking inputs and outputs to debugging LLM chains and optimizing model performance, Orq.ai offers an end-to-end solution that enhances the entire LLM lifecycle.
As the future of Generative AI unfolds, having the right tools to manage and optimize LLMs will be essential for building reliable, scalable, and efficient applications. Whether you are looking to troubleshoot, enhance, or simply gain deeper insights into your models, LLM tracing with Orq.ai ensures that you have the control and visibility needed to succeed.

