









Large Language Models (LLMs) are transforming the way machines process and generate human-like text. From answering complex questions to crafting detailed essays, these models are being integrated into a growing number of applications. But with their expanding role comes a critical need to measure their performance, ensuring they deliver accurate, reliable, and effective results.
To achieve consistent and objective assessments, LLM benchmarks have been established as standardized tests that measure the capabilities of these models. These benchmarks play a pivotal role in the AI leaderboard, providing a comparative analysis of different models' performances. By utilizing AI benchmarks, researchers and developers can identify strengths and weaknesses in LLMs, guiding future improvements and innovations.
In this comprehensive guide, we will delve into the significance of benchmarking LLMs, explore various LLM performance benchmarks, and discuss how these evaluations contribute to the advancement of artificial intelligence.
1. Understanding LLM Benchmarks
Evaluating the performance of Large Language Models (LLMs) requires a structured approach to ensure reliability, consistency, and fairness. As AI continues to advance, comparing models against standardized criteria helps developers and researchers optimize their systems for real-world applications. This is where LLM model benchmarks come into play.
A well-structured LLM benchmark leaderboard provides a clear comparison of different models based on their capabilities, efficiency, and accuracy. These assessments help identify which models perform best in various tasks, including reasoning, coding, and language understanding. Understanding the key components of current LLM benchmarks is crucial for both developers and decision-makers looking to deploy the most effective AI models.
1.1 What Are LLM Benchmarks?
At their core, LLM benchmarks are standardized tests designed to evaluate the performance of language models. These tests consist of predefined datasets, tasks, and evaluation criteria that allow for objective measurement of an LLM’s capabilities.
The components of best LLM benchmarks typically include:
Sample Data – Text-based datasets covering diverse topics and industries.
Tasks – Specific challenges such as text completion, question-answering, summarization, and translation.
Evaluation Metrics – Performance indicators like accuracy, F1 score, perplexity, and human-annotated quality assessments.
Scoring Mechanisms – Algorithms that assign quantitative scores based on model outputs to ensure objective comparison.

Credits: Data Science Dojo
With the increasing demand for LLM product development, specialized benchmarks such as LLM coding benchmarks and code LLM benchmarks have emerged to assess how well models perform on programming-related tasks, further expanding the scope of LLM evaluation.
1.2 Purpose and Importance
The role of open-source LLM benchmarks and proprietary evaluation methods is vital in shaping the development of future AI models. Their key purposes include:
Ensuring Consistency: By using standardized tests, benchmarks provide a uniform method for comparing different models, ensuring that results are objective and reliable.
Guiding Model Development: Performance insights from LLM benchmarks explained allow AI developers to refine their models, optimizing them for accuracy, efficiency, and application-specific needs.
Informing Stakeholders: AI researchers, businesses, and policymakers rely on LLM model benchmarks to make informed decisions about adopting and integrating AI systems into their workflows.
As the AI industry progresses, current LLM benchmarks continue to evolve, incorporating new metrics and test scenarios to keep up with the latest advancements in language model technology.
2. Key Metrics for Evaluating LLMs
Assessing the effectiveness of Large Language Models (LLMs) requires a deep understanding of various performance metrics. These metrics serve as the foundation for evaluating how well a model performs across different tasks, from text generation to coding tasks. A strong evaluation suite ensures that models are measured consistently, allowing researchers and developers to compare results across benchmarks like MT-Bench and the MMMU Benchmark.

Credits: Microsoft
Each metric plays a unique role in determining model performance, helping guide improvements throughout the AI development lifecycle. Below, we explore some of the most critical factors used in evaluating LLMs.
2.1 Accuracy and Precision
Accuracy and precision are two fundamental metrics that assess an LLM’s ability to generate correct and relevant responses.
Accuracy refers to the proportion of correct outputs among all predictions made by the model.
Precision focuses on how many of the model’s positive predictions are actually correct, making it especially important for applications where false positives can be problematic.
In real-world applications, these metrics help evaluate LLMs across various domains, including search engines, tool use automation, and enterprise chatbots. Many open-source models leverage accuracy and precision benchmarks to refine their outputs and improve reliability.
2.2 Recall and F1 Score
While accuracy and precision focus on correct predictions, recall and F1 score consider the balance between true positives and false negatives.
Recall measures how well a model identifies all relevant instances from a dataset.
F1 Score is a harmonic mean of precision and recall, providing a balanced metric when both false positives and false negatives are critical concerns.
For example, BFCL, a benchmark designed to assess factual consistency, relies heavily on recall and F1 score to determine whether an LLM is making factually correct claims. In MGSM (Mathematical Generalization and Symbolic Manipulation), these metrics help evaluate models on complex reasoning and problem-solving tasks.
2.3 Perplexity
Perplexity is a key metric in evaluating language models, measuring how well an LLM predicts the next word in a sequence. A lower perplexity score indicates that the model is more confident in its predictions and better at understanding natural language.
A model with low perplexity is more fluent and coherent in text generation.
High perplexity may indicate inconsistencies or difficulty in processing long-range dependencies.
In ranking LLMs, some benchmarks incorporate the Elo ranking system, a method borrowed from competitive gaming and chess, to provide a dynamic assessment of model capabilities. Whether assessing open-source models or proprietary AI systems, perplexity remains one of the most widely used metrics for benchmarking language fluency and predictive accuracy.
2.4 BLEU and ROUGE Scores
When evaluating LLMs for text generation tasks such as translation and summarization, BLEU (Bilingual Evaluation Understudy) and ROUGE (Recall-Oriented Understudy for Gisting Evaluation) scores are two of the most widely used metrics.
BLEU Score measures the similarity between a machine-generated text and a set of reference translations by analyzing n-gram overlaps (short sequences of words). A higher BLEU score indicates a closer match to human-generated content.
ROUGE Score is particularly useful for summarization tasks, assessing recall-based text overlap to determine how much of the original content is retained in the generated summary.
These metrics play a crucial role in LLM evaluation, especially for models designed to perform language transformation tasks. However, as multimodal models that incorporate text, image, and audio processing continue to evolve, there is an increasing need for benchmarks that go beyond purely text-based assessments.
2.5 Human Evaluation
Despite the effectiveness of automated metrics, human evaluation remains an essential component of LLM evaluation. While numbers provide consistency, human judges offer qualitative insights that automated metrics cannot fully capture.
Key aspects considered in human evaluation include:
Coherence – Does the model generate logically structured and well-connected responses?
Relevance – Are the outputs contextually appropriate and useful for the given task?
Semantic Meaning – Does the generated text align with the intended meaning of the prompt?
Benchmarks such as GSM8K, which focus on arithmetic reasoning, often benefit from human evaluation to determine whether models correctly apply logical and mathematical principles. This combination of qualitative and quantitative analysis ensures a more well-rounded assessment of an LLM’s true capabilities.
3. Prominent LLM Benchmarks
With the rapid growth of Large Language Models (LLMs), standardized benchmarks play a crucial role in measuring model capabilities and guiding improvements. These benchmarks provide structured evaluations that help researchers and developers compare different models across various tasks. From AI model ranking to in-depth LLM comparison, these evaluations ensure that models are assessed fairly and consistently.
By utilizing a mix of proprietary and open benchmarks, organizations can gain insights into how different LLMs perform in areas such as multitask learning, question answering, and programming. Below, we explore some of the most widely used LLM performance benchmarks and their significance in evaluating modern AI models.
3.1 Massive Multitask Language Understanding (MMLU)
The Massive Multitask Language Understanding (MMLU) benchmark is designed to evaluate an LLM’s ability to handle a diverse range of topics, from history and law to mathematics and coding. It is one of the most widely cited benchmark models, assessing knowledge across 57 subjects at different difficulty levels.
Key Features of MMLU:
Objective: Test an LLM’s ability to generalize across multiple disciplines.
Sample Tasks: Multiple-choice questions covering science, humanities, and professional subjects.
Evaluation Criteria: Accuracy in selecting the correct answer compared to human baseline performance.
As part of an LLM benchmark comparison, MMLU provides critical insights into how well a model retains and applies broad knowledge, making it essential for free LLM evaluations and proprietary model assessments alike.
3.2 General Purpose Question Answering (GPQA)
The General Purpose Question Answering (GPQA) benchmark is another vital tool in assessing an LLM’s reasoning capabilities. Unlike traditional Q&A datasets, GPQA emphasizes complex, multi-step reasoning, testing an AI’s ability to process and synthesize information before generating an answer.
Benchmark Structure and Scoring:
Assessing Reasoning Capabilities: Models must analyze context, retrieve relevant facts, and form logical conclusions.
Scoring System: Based on accuracy and logical consistency, with emphasis on understanding rather than memorization.
Comparison to Human Performance: Used as a bench AI standard to measure how closely an AI model aligns with expert-level reasoning.
GPQA is often included in LLM benchmark comparisons, helping to highlight differences in reasoning abilities between various models and identify areas for improvement in logical inference.
3.3 HumanEval
As AI plays a larger role in software development, specialized benchmarks like HumanEval have been developed to assess coding proficiency in LLMs. This benchmark, originally introduced by OpenAI, is specifically designed to evaluate a model’s ability to generate correct and functional code based on natural language prompts.
Key Aspects of HumanEval:
Task Examples: Models are given a problem statement and must generate Python functions that pass unit tests.
Performance Metrics: Accuracy is determined by whether the generated code executes correctly and meets test case requirements.
Use in AI Model Ranking: HumanEval results are frequently used to compare the programming abilities of different LLMs.
HumanEval is particularly valuable for organizations seeking a benchmark model to measure LLMs' effectiveness in average bench coding challenges. As LLMs continue to be integrated into software development workflows, this benchmark provides a clear measure of AI-assisted coding capabilities.
3.5 Beyond the Imitation Game (BIG-bench)
The Beyond the Imitation Game Benchmark (BIG-bench) is one of the most comprehensive and ambitious LLM evaluation frameworks. Unlike traditional benchmarks that focus on specific tasks like translation or coding, BigBench assesses models across a diverse range of challenges, including abstract reasoning, ethical decision-making, and creative problem-solving.
Benchmark Design and Objectives:
Exploring Diverse and Challenging Tasks: BIG-bench includes over 200 unique test sets, covering everything from logic puzzles to philosophical debates.
Benchmark Structure: Tasks range from standard multiple-choice problems to open-ended questions requiring nuanced responses.
Comparison with Human Performance: This benchmark helps identify gaps where AI still struggles compared to human cognition.
Another notable benchmark that complements BIG-bench is TruthfulQA, which evaluates how well models generate factually correct and non-misleading information. Since misinformation is a major challenge in AI applications, TruthfulQA helps ensure that LLMs generate reliable responses, making it a critical component of LLM evaluation benchmarks.
By incorporating benchmarks like BIG-bench and TruthfulQA, researchers gain a more holistic understanding of an LLM’s capabilities, identifying areas where AI excels and where improvements are needed. These evaluations also highlight how LLMs handle multilingual capabilities, providing insights into performance across different linguistic and cultural contexts.
4. Comparative Analysis of Leading LLMs
As the landscape of Large Language Models (LLMs) rapidly evolves, comparing their capabilities across standardized benchmarks is essential for understanding their strengths and weaknesses. A structured LLM scoreboard provides insights into how different models perform across tasks such as reasoning, coding, multilingual translation, and tool use.
From cutting-edge proprietary models like Claude 3.5 Sonnet and GPT-4o to open-source alternatives like Meta Llama 3.1, this comparative analysis explores how each model fares across various benchmarks and real-world applications.
4.1 Performance Across Benchmarks
Benchmarking LLMs allows researchers to quantify differences in performance across various tasks, helping organizations choose the most suitable model for their specific needs. The comparison table highlights leading models and their strengths across key evaluation criteria:
Model | MMLU | GPQA | Human | MATH | BIG-bench | TruthfulQA |
|---|---|---|---|---|---|---|
Claude 3.5 Sonnet | ★★★★☆ | ★★★★★ | ★★★☆☆ | ★★★★☆ | ★★★★☆ | ★★★★★ |
GPT-4o | ★★★★★ | ★★★★☆ | ★★★★☆ | ★★★★★ | ★★★★★ | ★★★★★ |
Meta Llama 3.1 405b | ★★★★☆ | ★★★☆☆ | ★★★★☆ | ★★★☆☆ | ★★★☆☆ | ★★★★☆ |
Claude 3.5 Sonnet demonstrates exceptional performance in graduate-level reasoning tasks, achieving top scores on the GPQA benchmark. It also excels in the MMLU benchmark, showcasing strong general knowledge and reasoning capabilities.
GPT-4o shows leading performance in mathematical problem-solving, particularly on the MATH benchmark. It also offers faster average latency compared to Claude 3.5 Sonnet, making it efficient for certain applications.
Meta Llama 3.1 (405B) offers competitive performance across a range of tasks, including general knowledge, mathematics, and code generation. Its strong multilingual capabilities and open-source nature make it an attractive alternative, especially for developers seeking cost-effective solutions.
The emergence of new benchmark speed running models has also introduced a trend where models are optimized to outperform benchmarks rapidly, raising questions about their real-world adaptability versus benchmark-driven tuning.
4.2 Open-Source vs. Proprietary Models
The debate between open-source models and proprietary LLMs continues to shape AI development. While open-source models like Meta Llama 3.1 provide greater transparency and flexibility, proprietary models like Claude 3.5 Sonnet and GPT-4o often achieve superior performance due to extensive training resources and fine-tuning.
Key Comparisons:
Meta Llama 3.1 offers strong reasoning and coding abilities while allowing for customization, making it ideal for research and enterprise applications.
Claude 3.5 Sonnet and GPT-4o consistently outperform in knowledge-intensive tasks, benefiting from larger datasets and proprietary optimizations.
Proprietary models typically lead in llm scoreboard rankings, but open-source alternatives continue to close the gap, particularly in tool use and adaptability.
4.3 Multilingual and Tool Use Capabilities
As LLMs expand their global reach, evaluating multilingual capabilities and tool use becomes increasingly important.
Claude 3.5 Sonnet has demonstrated strong multilingual fluency, particularly in high-resource languages, with ongoing improvements in low-resource languages.
GPT-4o excels in tool use, including function-calling and real-time integrations with external applications.
Meta Llama 3.1 provides competitive multilingual support and robust adaptability in open-source environments.
The future of LLMs lies in their ability to not only achieve high scores in traditional benchmarks but also adapt to real-world applications, including cross-lingual tasks and advanced tool use automation.
5. Limitations and Challenges of Current Benchmarks
While LLM benchmarks play a crucial role in evaluating model performance, they are not without limitations. As AI development progresses, researchers and developers face challenges in ensuring that benchmarks remain fair, reliable, and representative of real-world applications. Issues such as data contamination, narrow task focus, and benchmark saturation can compromise the integrity of evaluations, necessitating continuous innovation in benchmarking methodologies.
5.1 Data Contamination
One of the most pressing challenges in LLM evaluation benchmarks is data contamination — the risk that models have been trained on benchmark datasets, leading to artificially inflated performance. When an LLM has prior exposure to benchmark data, its results no longer reflect true generalization, but rather memorization.
Key concerns with data contamination:
Compromised evaluation integrity: If an LLM has already seen benchmark questions, its scores do not accurately reflect its reasoning abilities.
Diminished benchmark reliability: Popular benchmarks risk becoming obsolete as models overfit to them.
Need for dynamic benchmarks: Continuous updates and the introduction of new, unseen tasks can help mitigate contamination risks.
Ensuring the credibility of LLM performance benchmarks requires vigilance in dataset curation and verification techniques that detect potential overlaps between training data and evaluation sets.
5.2 Narrow Task Focus
Another major limitation of current benchmark models is their tendency to focus on narrow, predefined tasks that may not fully capture an LLM’s adaptability to real-world challenges. Many benchmarks test isolated skills—such as multiple-choice reasoning or code generation — but fail to assess broader capabilities like multi-step decision-making, complex problem-solving, and interactive learning.
Why a broader evaluation scope is needed:
Generalization beyond benchmarks: Models that perform well on specific tasks may struggle in unstructured, real-world environments.
Lack of adaptability testing: Current benchmarks rarely assess how well LLMs improve over time with iterative learning.
Emerging needs in AI applications: Fields like multimodal capabilities and real-time reasoning require benchmarks that move beyond static, single-task assessments.
Addressing these limitations will require innovative LLM evaluation frameworks that incorporate diverse, real-world tasks, rather than relying solely on predefined datasets.
5.3 Benchmark Saturation
As AI models continue to advance, some have begun to surpass the benchmarks originally designed to test their capabilities. This phenomenon, known as benchmark saturation, creates challenges in keeping evaluations relevant and ensuring that benchmarks remain a meaningful measure of progress.
Problems arising from benchmark saturation:
Models achieve near-perfect scores: When an LLM consistently outperforms existing benchmarks, it becomes difficult to differentiate between models.
Diminished competitive value: If benchmarks fail to evolve, they no longer drive innovation in AI development.
Need for dynamic benchmarking: Incorporating new benchmark speed running models that evolve in real-time could help maintain meaningful evaluations.
The future of LLM benchmark comparison lies in developing adaptive benchmarks that update regularly, introduce novel challenges, and better reflect real-world AI deployment scenarios.
LLM Benchmarks: Key Takeaways
LLM benchmarks play a critical role in shaping the development, evaluation, and optimization of large language models. By providing standardized metrics, they enable researchers and organizations to compare models, assess strengths and weaknesses, and drive advancements in AI technology. However, as AI continues to evolve, so must our benchmarking methodologies. Addressing challenges like data contamination, benchmark saturation, and real-world adaptability will require ongoing collaboration and innovation.
At Orq.ai, we recognize the importance of robust LLM evaluation in building high-performing AI applications. Our Generative AI Collaboration Platform includes an out-of-the-box evaluator library, enabling AI teams to seamlessly test, compare, and monitor models using diverse evaluation metrics. With built-in observability, security, and AI deployment tools, Orq.ai empowers organizations to optimize their LLM performance with confidence.
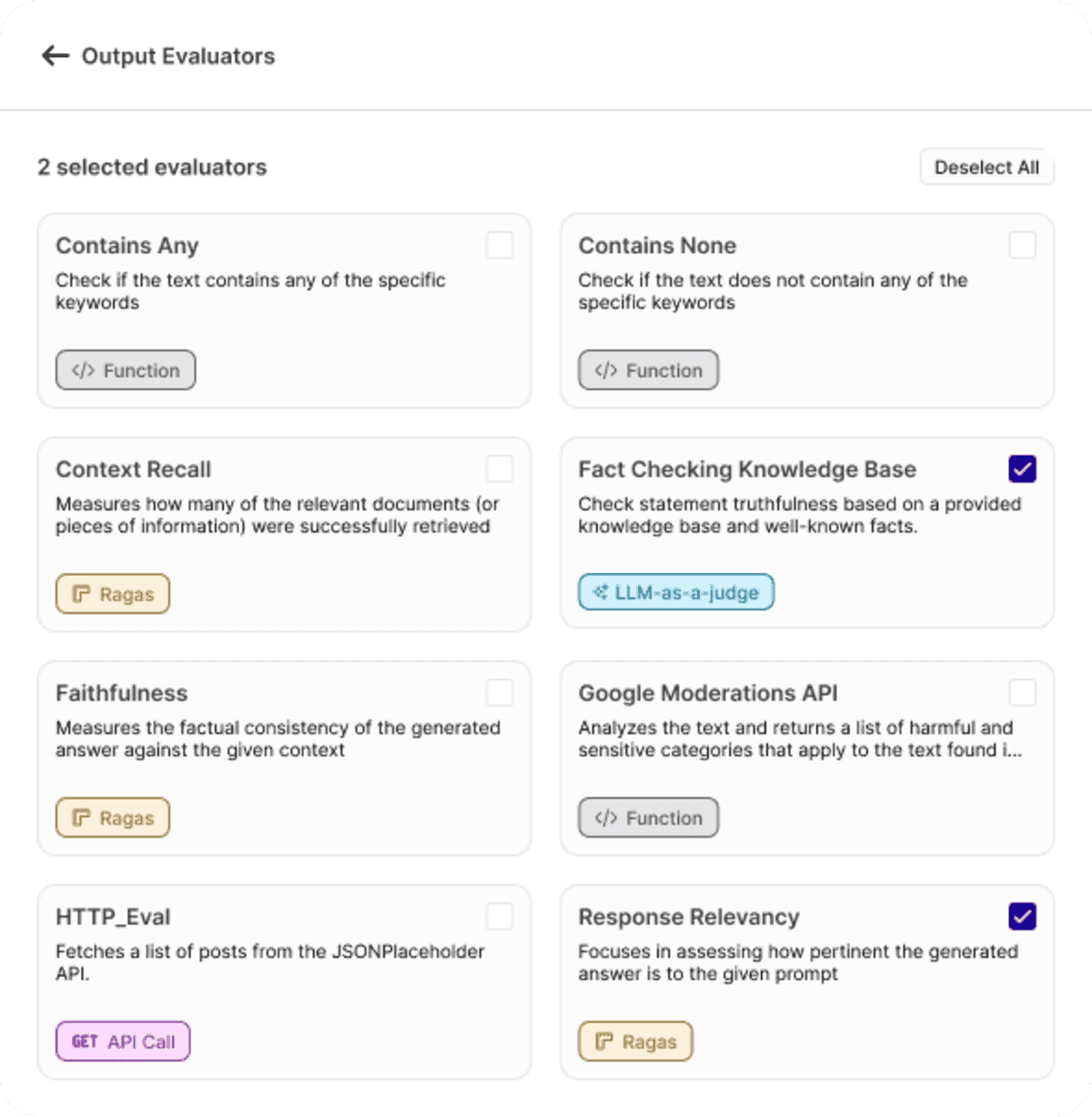
Sample of Evaluator Library in Orq.ai
Want to see how Orq.ai can streamline your AI evaluation and deployment process? Book a demo today and explore the future of AI benchmarking.

