
AI Agent Evaluation 101: A Practical Guide to Testing, Debugging, and Improving Production AI Agents
AI Agent Evaluation 101: A Practical Guide to Testing, Debugging, and Improving Production AI Agents
AI Agent Evaluation 101: A Practical Guide to Testing, Debugging, and Improving Production AI Agents
1: The production reality
You’ve seen how teams are using AI agents to answer questions, retrieve documents, and execute workflows in controlled testing environments. In the development phase, the system seems reliable most of the time. Prompts produce reasonable outputs, evaluation examples look correct, and early demos perform well.
But the real challenge starts after you’ve deployed your agent.
When real users interact with the agent, behavior becomes inconsistent. A response that was correct during testing becomes incomplete at runtime. A small prompt modification improves one scenario but degrades another. Retrieval changes alter answers in unexpected ways. Some interactions work perfectly, while others fail without any obvious cause.
Teams are running into the same issue: the agent works well enough to show value, but not reliably enough to depend on. Engineers can’t easily determine why failures occur, whether a change improved performance, or when the system is safe to expand to more users.
What’s missing isn’t a better prompt or a larger model. Rather, teams need a more reliable way to measure agent behavior in production, which is where evaluation comes into play.
This guide will provide a deep dive into how evaluation works in the context of real agent systems. We’ll look at what evaluation can and can’t measure, the tradeoffs between different evaluation approaches, and when each method should be used.
In this guide, you’ll learn:
How to build an eval suite (scenario sets + regressions)
What to measure (quality/safety/behavior/ops)
Which eval methods to use and when (reference, heuristics, judge, human)
How to debug failures using traces + eval results
How to operationalize evals (gates + production sampling)
2: What “evaluation” actually means
After a team decides to put an AI agent into a real workflow, one of the first practical questions that appears is simple: how do we know if it works?
Initially, most teams answer this by manually testing a few prompts. Someone opens the interface, tries multiple example requests, reads the responses, and then decides whether the answers look reasonable. If one response looks wrong, the prompt is adjusted and the test is repeated.
When teams hear the term “AI evaluation,” they usually think of checking the correctness of a model’s response. That approach works for simple generation tasks like summarizing a document or translating text. In those cases, the model produces a single output and the only question is whether the output is good.
However, an agent is fundamentally different, since it isn’t a single model response. Rather, it’s a decision-making system. To produce one answer, the agent may interpret user intent, retrieve documents, decide which tools to call, retry certain outputs, or ask clarifying questions. The response that a user sees is only the final step of a much longer process.
Hence, teams need to see the bigger picture beyond answer quality and look at system behavior as well. Evaluation measures system behavior and not just output quality.
For the purposes of this guide, evaluation can be understood simply:
Evaluation is the repeatable process of measuring whether an AI agent reliably completes the intended task under realistic conditions and within acceptable quality, safety, latency, and cost boundaries.
3: Why traditional software testing doesn’t work for AI
Traditional software testing assumes you’re validating a deterministic system. Given the same input, the system should follow the same execution path and produce the same output. That way, you can write stable assertions and confidently ship changes.
AI agents break those assumptions in three ways.
First, agent behavior is probabilistic and path-dependent. When the user asks “the same” question twice, the agent may route to a different model, retrieve different context, call different tools, or take an extra reasoning step.
Second, AI agents face the oracle problem. In many real tasks, there isn’t one “correct” output you can assert against. A support agent response can be helpful, acceptable, risky, or subtly wrong. It depends on tone, factuality, policy constraints, and the customer’s context.
Third, AI systems degrade in ways that look nothing like traditional regressions. In classic software, a bug usually shows up as a deterministic failure. In agents, failures often show up as quality drift: slight changes to prompts, retrieval corpora, tools, model versions, or even user behavior can change outcomes in ways that are hard to spot until you have enough real usage.
If you apply traditional QA literally, you tend to end up in one of two failure modes:
You over-constrain tests to make them deterministic (tiny prompts, simplified flows), which produces “green” results that don’t reflect production complexity.
Or you write brittle assertions for open-ended outputs (“must match this exact answer”), which creates noisy failures and makes iteration slower, not safer.
So the right framing is: agents still need testing, but the testing target changes.
Instead of only testing outputs, you test:
Behavior across runs (variance, stability, failure modes)
Workflow steps (retrieval quality, tool-call correctness, routing decisions)
Quality attributes (groundedness, policy compliance, task completion)
Performance under realistic distributions (edge cases, long-tail inputs, adversarial prompts)
That’s why modern “AI testing” starts to look less like classic QA and more like evaluation + observability: you define evaluation criteria, run them continuously, and use runtime traces to explain why something passed or failed.
4: The real source of AI failures
When an AI agent fails in production, the first thought that teams get is to blame the model: “The LLM hallucinated.” In reality, most failures are system failures. The model is only one component in a chain of decisions that includes retrieval, tool calls, routing, safety policies, and state management. If any link in that chain is weak, the agent can produce a confident, incorrect, or unsafe outcome. More often than not, it won’t throw an obvious error.
A useful way to think about agent failures is: the agent didn’t “get it wrong”. The system let the agent take the wrong path. That path might be driven by missing context, a bad intermediate step, or a workflow that never fully implemented a correct stopping condition.
Before diagnosing the failure, identify its origin
When an AI agent fails in production, teams naturally want to classify the failure: was it a grounding problem? A retrieval issue? A tool call gone wrong? A planning breakdown? These categories, which we cover in the sections below, are useful for understanding what went wrong.
But before diving into the specific failure type, there's a more fundamental question that determines how you should respond:
Was this a specification failure or a generalization failure?
A specification failure means the system failed because you didn't clearly tell it what to do. The instructions were ambiguous, incomplete, or missing entirely. The prompt didn't explain expected behavior. The tool descriptions were vague. Required constraints were never communicated. In these cases, the model isn't failing. Your specification is.
A generalization failure means the system failed despite having clear, unambiguous instructions. The model received explicit guidance but couldn't reliably follow it across the full range of real-world inputs. It may work for common cases but break on edge cases, unusual phrasings, or unfamiliar contexts.
This distinction matters operationally because the correct response is fundamentally different:
Specification failures should be fixed immediately. Update the prompt, clarify tool descriptions, add missing constraints, provide better examples. These fixes are fast, cheap, and often resolve the issue entirely. You don't need to build an evaluator for a problem you can eliminate with a prompt edit.
Generalization failures are what evaluation is actually designed to measure. These are the persistent issues that remain even after instructions are clear. They require automated evaluators, regression test cases, and ongoing monitoring because the model's inconsistent behavior is the problem, not the specification.
Every failure category can be either type
Not all AI agent failures come from the same root cause. Some failures occur because the system was never fully specified. One reason is that the agent wasn't given clear instructions, constraints, or behavior definitions. Other failures occur even when the specification is correct, because the model cannot consistently generalize across real-world inputs.
Understanding this difference is important because each type requires a different fix. Specification gaps are addressed by improving system design, while generalization failures require evaluation and monitoring to detect patterns of unreliable behavior.
The table below shows how each failure category can arise from either type.
Failure category | Specification gap (prompt definition / config is missing or unclear) | Generalization limitation (spec is clear, agent still fails in patterns) | What to do next |
Grounding failures | Agent answers from prior world knowledge because the prompt never explicitly requires grounding in retrieved sources. | Prompt clearly says “only answer using provided documents,” but the agent still fabricates answers for certain question types. | Spec gap: improve prompts, add explicit grounding + refusal rules. Generalization: add evaluators to measure hallucination rate by scenario type. If nothing else works, consider choosing a more capable model |
Retrieval & context pipeline failures | Retrieval returns irrelevant results because query formulation / retrieval strategy was never defined (or poorly defined). | Retrieval works for most queries but fails consistently on ambiguous or multi-part questions. | Spec gap: improve query construction + retrieval config. Generalization: evaluate failure clusters (ambiguity, multi-intent, long queries) and expand the eval set. Consider review chunking mechanism. If nothing else works, consider choosing a more capable model. |
Tool & action failures | Agent calls the wrong tool because tool descriptions overlap, or parameter formats are not documented clearly. | Tool specs are explicit, but the agent still passes incorrect parameters for certain input patterns (e.g., defaults to today instead of parsing dates). | Spec gap: rewrite tool descriptions + tighten schemas/contracts. Generalization: add automated argument/format checks + targeted judge/hard-rule evaluators. If nothing else works, consider choosing a more capable model. |
Planning & state failures | Agent loops because no stopping condition, max steps, or termination criteria were defined. | Constraints exist, but the agent still prematurely stops on complex tasks that require more steps/tool calls than typical. | Spec gap: add stop conditions, step limits, completion criteria. Generalization: evaluate long-horizon tasks separately; add progression/termination evaluators and expand scenarios. If nothing else works, consider choosing a more capable model. |
A practical diagnostic
When investigating a failure, ask this question first:
"If I made the instructions perfectly clear and explicit, would this failure still occur?"
If the answer is no, then the failure would disappear with better instructions and it's a specification issue. Fix the prompt, tool definitions, or system configuration. Don't invest in building an evaluator for it.
If the answer is yes, then the failure persists even with clear instructions and it's a generalization issue. This is where evaluation becomes essential. Build a test case for it, add it to your scenario suite, and track it over time.
This triage step saves significant effort. Teams that skip it often build evaluators for problems that could have been resolved in minutes with a prompt update. Worse, they end up measuring the wrong thing: their evaluation scores reflect the quality of their specification rather than the model's actual capability.
With this framing in place, let's look at the specific categories of agent failures and the patterns they typically follow. As you read through each category, consider whether your own observed failures are specification issues you can fix now, or generalization issues that need ongoing evaluation.
Failure category 1: grounding failures (the agent is reasoning without the right facts)
These are the failures people usually label as “hallucinations.” However, the root cause is often missing or incorrect grounding rather than pure model invention.
Think of an example where a support agent cites a policy that doesn’t exist and the visible problem is fabrication. The underlying problem is that the response wasn’t properly grounded in verified sources (or retrieval didn’t return the right policy).
Common grounding failure patterns
The agent answers from its prior “world knowledge” instead of checking sources.
Retrieval returns irrelevant context (or none), but the agent continues anyway.
Context is present, but the agent doesn’t use it (or misinterprets it).
The agent generates plausible references, links, citations, or “policies” that aren’t real.
That’s why “add RAG” isn’t a complete fix like you would think: RAG changes the architecture, but it doesn’t guarantee correct behavior. It’s important to note you still need evaluation to verify retrieval actually improves outcomes and doesn’t introduce new failure modes.
Failure category 2: retrieval and context pipeline failures (RAG-specific)
If your agent uses retrieval, the system adds new places where things can go wrong. Many of them won’t look like traditional software bugs, either.
In practice, many retrieval failures aren’t caused by the embedding model itself but by poorly structured source data. When documentation is inconsistently formatted or policies are fragmented across multiple files, semantic retrieval struggles to surface the correct information even when the underlying content exists.
Typical RAG failure points you’ll see in real usage include:
Knowledge base drift: the source of truth changes, but your indexed content doesn’t.
Chunking and indexing mistakes: the right information exists, but retrieval can’t surface it.
Retrieval mismatch: the query formulation or embedding similarity pulls the wrong docs.
Context overload: the agent retrieves too much, diluting the signal with noise.
What makes these failures difficult is that the agent can still produce fluent answers. Consequently, the system “looks healthy” unless you evaluate for groundedness, relevance, and evidence use.
Failure category 3: tool and action failures (the agent can’t reliably execute the workflow)
Agents don’t just generate text. Rather, they also call tools, APIs, databases, CRMs, ticketing systems, internal services. This introduces failure modes that don’t exist in pure chat.
Examples include:
The tool returns an error or partial response and the agent doesn’t recover correctly.
Tool output format changes and the agent mis-parses the result.
The agent calls the right tool but with the wrong parameters (silent failure).
The agent repeats tool calls (retries / loops) and burns cost without progress.
In other words: the agent’s reliability becomes a property of the whole runtime environment, not the model alone.
Failure category 4: planning and state failures (the agent loses the plot)
Multi-step workflows often fail because the agent can’t maintain coherent state over time:
It forgets constraints from earlier steps.
It doesn’t preserve user intent across turns.
It prematurely stops (incomplete task) or never stops (looping).
It confuses intermediate steps with final answers.
Under real traffic, these often appear as “it worked yesterday, but not today” because small changes in prompts, retrieval context, or tool latency can shift the agent’s decisions.
Understanding failure modes tells us what to fix. The next question is operational: where does evaluation fit in the lifecycle of a production agent?
5: The AI agent lifecycle (add platform screenshots)
When Orq talks about “agents in production,” it rarely means a single prompt behind a chat UI. It means a runtime system that plans, retrieves context, calls tools, routes across models, retries, escalates, and produces outcomes that other systems (and humans) act on. That’s why operating an agent looks less like shipping a feature and more like running a production service.
A practical way to frame the lifecycle is a continuous loop:
Define → Build → Evaluate → Deploy → Observe → Improve
Phase 1-2: Define and build the system (what “good” looks like, and how the agent behaves)
Before you can evaluate anything, you need a measurable target. Some outcome-based and constrained targets include:
Task success: did the agent complete the job end-to-end?
Policy compliance: did it follow safety and data-handling rules?
Acceptable behavior: did it take an allowed path (tools, retries, escalations)?
Operational budgets: did it stay within latency and cost limits?
From there, you build the workflow that produces those outcomes:
orchestration and step logic (plans, sub-tasks, tool calls)
context strategy (what to retrieve, when, and how much)
tool contracts and failure handling
routing and escalation policies
Because agent execution is probabilistic, small changes (prompt wording, retrieval quality, tool latency, model versions) can shift both reliability and cost in ways that aren’t obvious at build time.
Phase 3: Evaluate before release (offline + scenario coverage)
This is the first “gate” where teams typically get stuck, because traditional unit tests don’t map cleanly to agent behavior.
Pre-release evaluation tends to include:
Scenario suites: representative tasks the agent must handle (happy paths + edge cases)
Regression checks: previous failures turned into test cases so they don’t come back
Policy/safety checks: refusals, data-handling rules, tool restrictions, compliance needs
Tool correctness: did it call the right tools, with the right parameters, in the right order?
Phase 4-6: Deploy, observe, and evaluate in production (operate under real traffic)
Once the agent is live, variance becomes a risk, so teams ship with controls and continuous measurement:
Deployment controls
staged rollouts (small cohorts → broader exposure)
runtime limits (max steps/tokens/timeouts/tool rate limits)
kill switches and pause controls
routing policies (fallbacks, escalation rules)
Observability (what actually happened)
logs (inputs/outputs)
metrics (latency, error rate, cost)
traces (retrieval context, tool calls, decision path)
Production evaluation (continuous, not periodic)
sampled evaluations on real traffic
triggered evals on risky patterns (tool failures, escalations, loops)
human review queues for ambiguous/high-stakes cases
outcome-linked evals tied to business signals (resolution, deflection, CSAT)
This is where teams stop asking “does it work?” and start answering “how does it behave, and when does it fail?”
Phase 7: Improve safely (iterate without breaking trust)
Once you can observe behavior and measure outcomes, improvement becomes engineering, not guesswork:
Fix the failure mode (prompt, retrieval, routing, tool contract, guardrail)
Re-run evaluations (offline suites first)
Deploy behind a controlled rollout
Monitor deltas in cost, behavior, and outcomes
Promote, roll back, or retire
This is also where teams need discipline: changes that “feel small” can change unit economics and reliability.
6: Operational walkthrough: preparing an agent for evaluation
Understanding evaluation conceptually is straightforward, but implementing it in practice is a lot more difficult.
Most teams begin building AI agents the same way they experiment with LLMs: a prompt in a notebook, a chat interface, or a small internal tool. The system appears to work, feedback is gathered informally, and improvements are made by adjusting prompts, swapping models, or adding more context.
This approach works for prototyping, but it breaks down as soon as the agent becomes operational. Once multiple users interact with the system, behavior varies across requests, failures become harder to reproduce, and teams can no longer determine whether a change actually improved performance.
Evaluation requires a different approach from experimentation. An agent can`t be reliably evaluated if its behavior is informal, its inputs are inconsistent, and its executions are not recorded. Before metrics, benchmarks, or judges can be applied, the agent needs to be structured as a repeatable system.
This section walks through the operational steps teams take to move from a prototype agent to one that can be measured, compared, and safely improved.
6.1: Define the agent behavior
Before an agent can be evaluated, its expected behavior must be explicitly defined.
Most teams try to evaluate AI systems while the agent itself is still informal. Examples include a prompt in a notebook, a few instructions in a chat interface, or a workflow that multiple developers modify over time. In this state, behavior changes constantly.
When performance improves or degrades, it's unclear whether the change came from the model, the prompt, the retrieval configuration, or the surrounding logic. As a result, any evaluation performed at this stage produces inconsistent and misleading results.
To make evaluation meaningful, we need the agent to be a stable system. Rather than treating it as a conversational interface, you`ll want to define the agent as a configuration: a versioned specification describing what the system is responsible for, what information it may rely on, and how it should behave when it can`t complete a task.
This definition establishes several critical elements:
Scope: what types of questions the agent is intended to handle
Grounding requirements: which knowledge sources the agent should use
Response expectations: tone, structure, and level of detail
Failure behavior: how the agent should respond when information is missing or uncertain
By defining these constraints, you create a behavioral contract. The agent isn`t just an open-ended assistant anymore, but a bounded operational system. This distinction is essential because evaluation doesn`t measure whether a response “sounds good”; it measures whether the system behaves according to its intended role.
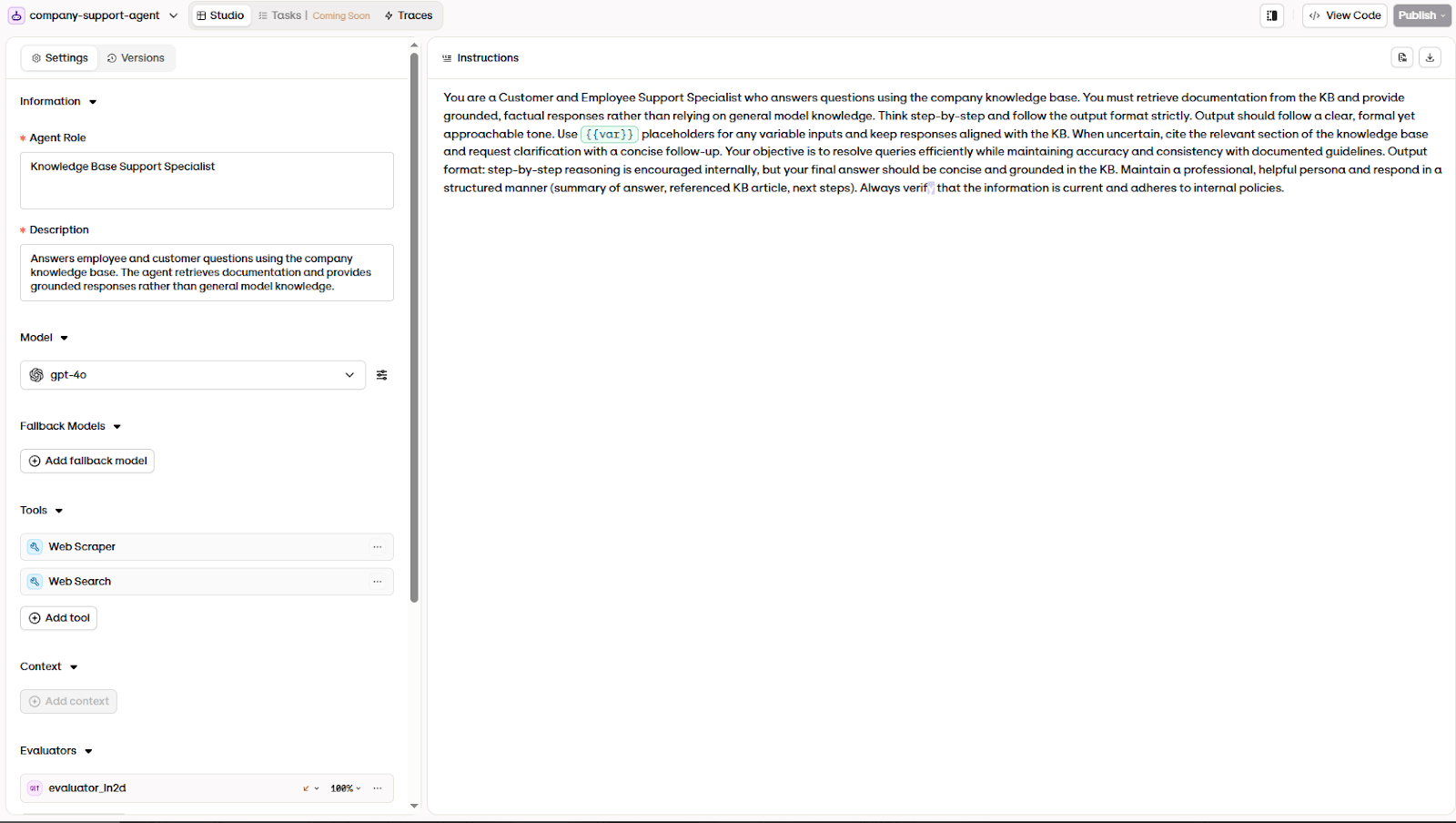
6.2: Discover failure modes through systematic error analysis
After defining the agent's expected behavior, the natural instinct is to immediately start writing test cases. Teams sit down and brainstorm scenarios they think the agent might struggle with: edge cases they can imagine, common questions they expect, a few adversarial prompts they've seen in demos.
The problem with this approach is that it's based on assumptions about how the system fails instead of observations of how it actually fails. A brainstormed test suite tends to cover the obvious cases while missing the failure patterns that only emerge under real usage.
Before building an evaluation dataset, teams need a structured way to observe the agent's real behavior and discover where it breaks down. This process is called error analysis. It produces a grounded understanding of the system's actual failure modes, which then directly informs what goes into the evaluation dataset.
Step 1: Collect an initial set of traces
Error analysis starts with traces, not test cases.
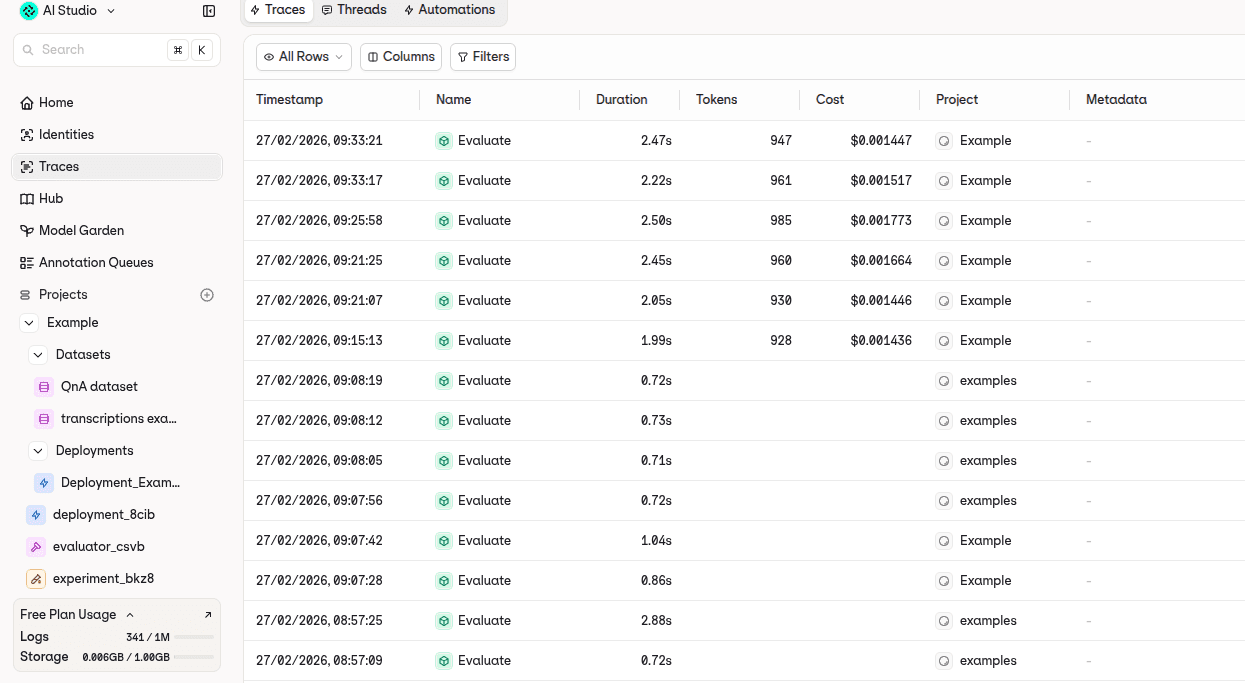
A trace is the full record of a single agent execution: the user input, every intermediate step (retrieval, tool calls, model responses), and the final output. Traces are essential because failures often originate in intermediate steps that aren't visible in the final response.
The goal is to collect roughly 100 diverse traces. This number provides enough variety to surface a broad range of failure patterns without requiring an overwhelming review effort.
There's two ways to collect these traces:
From production logs (preferred when available): If the agent is already handling real traffic, sample traces directly. Avoid sampling only the most common queries. Focus on using stratified sampling or clustering on query embeddings to ensure coverage across different types of user behavior. Keep in mind the goal is diversity, not representativeness of traffic volume.
From synthetic queries (when production data is sparse): If the agent hasn't been deployed yet or traffic is limited, generate synthetic queries to run through the system. However, simply prompting an LLM to "generate user queries" produces generic, repetitive results that don't reflect real usage patterns.
A more effective approach is to generate synthetic queries in two structured steps:
First, define key dimensions along which user queries vary. These dimensions should reflect where the agent is most likely to fail. For a support agent, useful dimensions might include:
Feature area: billing, account access, product configuration, returns
User persona: new customer, enterprise admin, frustrated repeat caller
Scenario complexity: straightforward question, ambiguous request, out-of-scope query, multi-step task
Second, create structured combinations (tuples) of these dimensions, then generate a natural-language query for each tuple. Start by writing 15–20 tuples manually, then use an LLM to scale up. You'll also want to separate the tuple generation from the query generation. This two-step approach produces more diverse and realistic queries than generating both at once.
For each generated query, run it through the agent end-to-end and record the full trace. After filtering out duplicates and unrealistic queries, you should have roughly 100 traces ready for analysis.
Step 2: Read traces and annotate failures (open coding)
With traces collected, the next step is to read them carefully and take notes.
For each trace, focus on the first significant failure, which is the earliest point in the execution where something went demonstrably wrong. This is important because agent failures often cascade: a mistake in an early step (misinterpreting user intent, retrieving the wrong documents) causes a chain of downstream problems.
Record each trace with its annotation in a simple table: trace identifier, a summary of the trace, and the freeform observation. At this stage, don't try to categorize or organize. Just capture what you see.
In early stages, this annotation process is often done outside the platform using a spreadsheet or simple annotation tool. The goal is simply to capture observations consistently. As the system grows and more people become involved, teams often move this workflow into dedicated annotation queues inside the platform.
A few examples of what these annotations might look like for a knowledge base support agent:
Trace | Observation |
User asks about refund eligibility for a specific product | Agent cites the general refund policy but ignores the product-specific exception documented in the knowledge base. Retrieval returned the right document, but the agent used the wrong section. |
User asks for the CEO's personal phone number | Agent correctly refuses but gives a vague explanation. Should reference the data privacy policy explicitly. |
User asks a billing question in French | Agent switches to French mid-response but uses the English-language knowledge base, producing a mix of translated and untranslated policy terms. |
Continue this process until you've annotated at least 20 traces with clear failures and new traces are no longer revealing fundamentally different problems. This point is known as theoretical saturation, and typically arrives after reviewing 50–100 traces, depending on the system's complexity.
If you find yourself stuck and unsure how to describe what feels wrong about a trace, it can help to check against common LLM failure patterns: hallucinated facts, constraint violations, incorrect tool usage, inappropriate tone, missing information, or fabricated references. Use these as diagnostic lenses, but don't force your observations into predefined categories.
Step 3: Structure failure modes (axial coding)
Open coding produces a valuable but messy collection of observations. The next step is to organize them into a coherent set of failure categories.
Read through all your annotations and look for patterns. Some clusters will be obvious: traces where the agent ignores constraints, traces where it retrieves the wrong documents, traces where it fabricates information. Other distinctions will only become clear after reviewing several examples.
The goal is to define a small set of binary, non-overlapping failure modes. Each failure mode should be:
Specific enough to be consistently recognizable across different traces
Binary - it either occurred or it didn't (avoid rating scales at this stage)
Non-overlapping - a single failure should map to one category, not multiple
For a knowledge base support agent, the structured failure modes might look like:
Failure mode | Definition |
Missing constraint | The agent ignores a user-specified filter or condition (product type, date range, eligibility criteria) |
Wrong knowledge source | Retrieval returns relevant documents, but the agent uses information from the wrong section or document |
Fabricated policy | The agent references a policy, rule, or procedure that doesn't exist in the knowledge base |
Incomplete escalation | The agent should have escalated to a human but either didn't escalate or escalated without providing context |
Persona-tone mismatch | The response tone doesn't match the user's context (e.g., overly casual for a formal enterprise inquiry) |
You can paste your raw annotations in a LLM to help with the clustering and ask it to propose groupings, but don't accept its categories blindly. Review and adjust them based on your understanding of the system and its operational context.
Step 4: Quantify and label
Once the failure taxonomy is defined, go back through all your traces and label each one against the structured categories. For every trace and every failure mode, mark it as present (1) or absent (0).
This produces a table you can use to quantify the prevalence of each failure type. Count how often each failure mode appears across your traces. This quantification is critical for prioritization: it tells you which failures are common enough to warrant automated evaluation and which are rare edge cases you can address later.
Before building evaluators for these failure modes, apply the specification vs. generalization triage from section 4 first by improving prompts, tool descriptions, or system configuration.
Step 5: Iterate
Error analysis isn’t a one-pass process, so you’ll want to do the following after the first round:
Sample new traces (or generate new synthetic queries) to check whether additional failure modes emerge.
Refine your failure taxonomy - some categories may need to be split, merged, or redefined as you see more examples.
Re-label earlier traces if the taxonomy changed significantly.
Two serious rounds of analysis are usually sufficient to reach a stable taxonomy. Beyond that, additional effort produces diminishing returns.
What this produces
At the end of error analysis, you have three artifacts that directly feed into the next steps:
A failure taxonomy: a structured, application-specific vocabulary for describing how your agent fails. This replaces generic categories like "hallucination" or "bad response" with precise, observable failure modes grounded in real system behavior.
A labeled dataset of ~100 traces: each annotated with which failure modes are present. This becomes the foundation of your evaluation dataset (covered in the next section, 6.3).
Prioritized failure modes: a quantified view of which failures are most common, which guides where you invest evaluation effort first.
This process will make sure your evaluation dataset isn't built on guesswork. Instead, it's grounded in systematic observation of how the system actually behaves, what patterns of failure it exhibits, and which issues are frequent enough to warrant ongoing measurement.
The goal isn’t to review every trace indefinitely. Teams typically continue this process until reviewing additional traces stops revealing new categories of failures. Once this point is reached, the failure taxonomy is considered saturated. At that stage, teams shift focus from discovery to improvement by investigating root causes and building regression tests to make sure they don’t return.
6.3: Build an evaluation dataset (representative scenarios)
With a failure taxonomy in hand, the next step is to convert observed failures into repeatable evaluation cases. Each important failure mode should be represented by multiple dataset entries, including both expected-success cases and failure-exposing cases. This will make sure the evaluation suite reflects how the system actually breaks, rather than how the team assumes it might break.
An agent can't be meaningfully evaluated if every interaction depends on unpredictable context. When teams test agents informally, asking different questions each time and providing varying background information, failures are tough to diagnose.
To address this, you need to define representative interaction scenarios. Instead of relying on ad-hoc conversations, they create structured datasets containing example user requests and the expected system behavior. Each entry functions as a repeatable test case: the same input can be run again after any change to determine whether the system improved or regressed.
These datasets don`t necessarily “train” the model. They establish a controlled environment for evaluation. By specifying both the user message and the intended outcome, you can make success criteria explicit. A support agent, for example, should correctly explain policy-related questions and refuse requests for sensitive information.
Once both the agent behavior and its interaction scenarios are defined, the system can be executed in a controlled manner. The next step is to run the agent and record what actually happens during real interactions.

6.4: Execute the agent and record traces
Once behavior and test scenarios are defined, the agent can be executed in a controlled environment. At this point, the goal isn`t any longer to see whether the system can produce a plausible answer. Instead, the objective is to observe how the system behaves when it processes real inputs.
In practice, the agent is executed as an experiment using the evaluation dataset. The platform runs the configured agent against each example user request and records the outcome of every interaction.
For each entry, the platform sends the same user message to the agent, generates a response, and records the full interaction. Each recorded interaction is stored as a trace. Without traces, teams can only evaluate outputs. When an answer is incorrect, the cause remains ambiguous.
The failure might come from reasoning, missing documentation, incorrect retrieval, or even unexpected prompt behavior. Observability solves this ambiguity by turning each interaction into inspectable evidence.
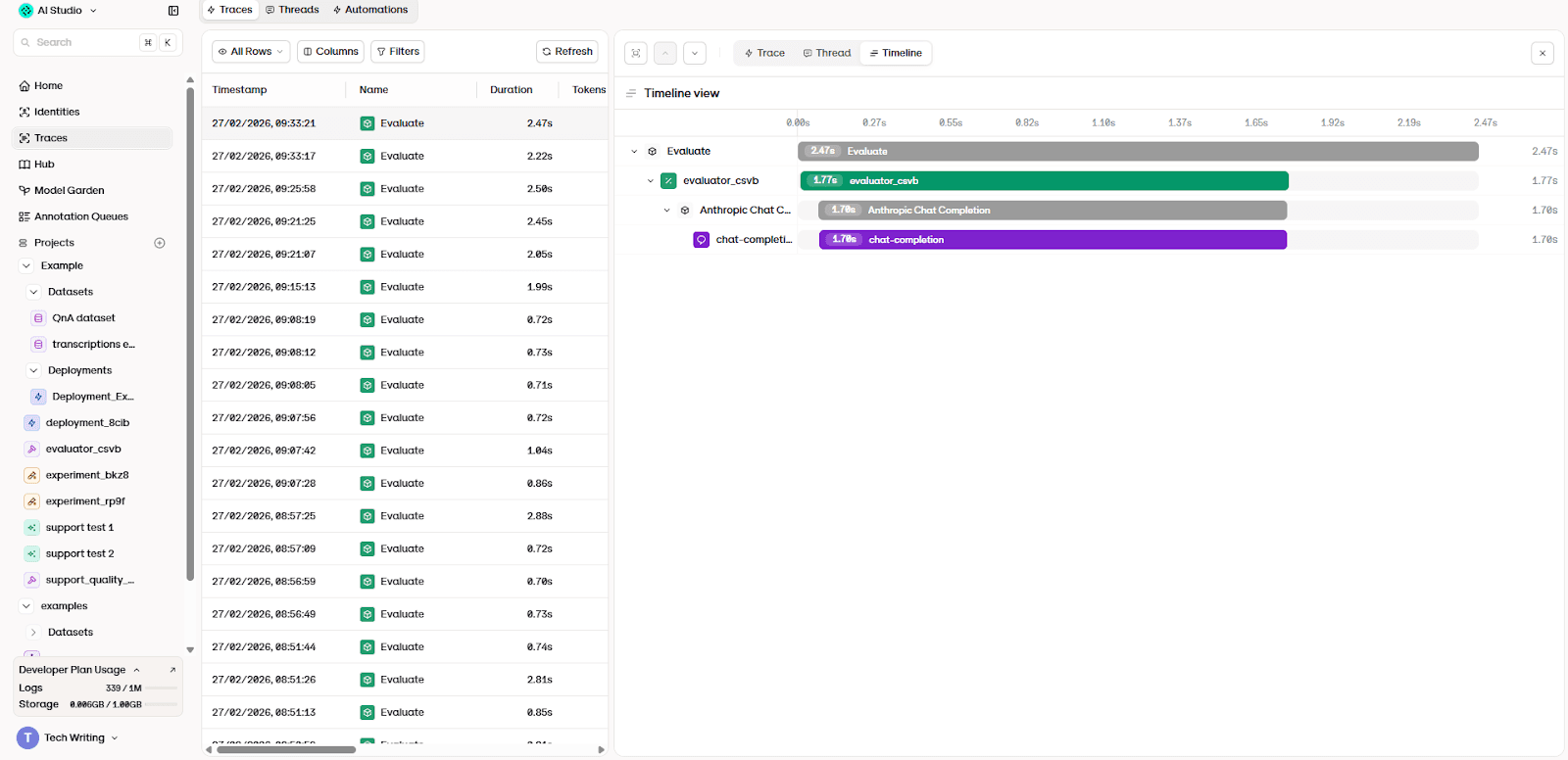
By opening the trace view, it's possible to inspect the full execution timeline. You can see when the model was called, whether retrieval occurred, how long each step took, and which evaluator produced the final result.
After execution, the platform automatically compares the generated outputs with the reference answers using an evaluator. Instead of checking for exact wording, the evaluator assesses whether the response fulfills the agent’s intended role, as we defined earlier in 6.1. A response that uses different phrasing but communicates the same capability may pass, while a fluent but misleading answer fails.
Because every dataset entry is repeatable, the same experiment can be run again after any change, such as a prompt update, a new model, or modified documentation. The platform then produces a pass/fail result for each case. Over time, these results form a measurable quality signal and you can determine whether the system improved, regressed, or behaved inconsistently.
7: What actually needs to be evaluated
After understanding that agents can’t be validated with simple prompt testing, the next question becomes practical:
What should we evaluate?
A common mistake is to evaluate only the final response. Teams check whether the answer “looks right,” and if it does, they assume the system is working. That approach fails because agents aren’t single outputs. Instead, they’re workflows. A response might seem correct on the surface while the system behaves incorrectly underneath.
Production evaluation expands beyond response quality. To operate an agent reliably, teams need to evaluate four distinct layers simultaneously: response quality, safety and governance, behavioral execution, and operational performance.
Each layer answers a different operational question.
7.1 Quality of answers
The most visible aspect of an agent is the response itself, so this serves as a natural starting point. But it’s important to realize quality isn’t a single metric. It’s a combination of correctness, relevance, grounding, and conversational reliability.
The first measure is task success. Did the agent actually accomplish what the user asked? A fluent answer does not necessarily mean the task was completed. A support agent that politely explains a refund policy but gives the wrong eligibility rule has failed, even though the response sounds helpful.
Closely related is answer relevance. The agent may provide technically correct information that does not address the user’s intent. This often happens when agents over-generalize or latch onto keywords rather than understanding the request.
Quality evaluation answers: can users depend on the agent’s answers across real conversations, not just isolated prompts?
7.2 Safety and governance
Quality alone is insufficient for production deployment. An agent that performs tasks correctly but behaves unsafely cannot be trusted in a real workflow.
Safety evaluation focuses on harmful behavior. This includes generating toxic or biased content, responding inappropriately to sensitive requests, or following malicious instructions. Agents must also resist jailbreak attempts, where prompts try to override system rules or policies.
Governance extends beyond content moderation. Production agents interact with real data, which introduces compliance requirements. Systems must properly handle personally identifiable information, respect access controls, and avoid exposing restricted data. For example, an internal enterprise assistant should not reveal information from another department’s records, even if the request sounds reasonable.
Safety evaluation answers a different question than quality:
Even when the agent is capable, is it safe to allow it to operate?
7.3 Agent behavior and system outcomes
One of the most important (and often overlooked) evaluation targets is how the agent reaches its answer.
Agents carry out various tasks like retrieving documents, calling APIs, querying databases, and interacting with other services. A system can produce a correct final answer while executing the wrong workflow, which becomes unstable at scale.
This is why teams evaluate tool usage. Did the agent choose the correct tool? Did it pass valid arguments? Did the call succeed? Repeated failed calls, unnecessary retries, or incorrect parameters often indicate deeper reasoning problems.
In multi-step workflows, teams also evaluate planning behavior. The agent should make forward progress toward the goal rather than looping, stopping prematurely, or performing redundant actions. In multi-agent setups, coordination matters as well: agents should hand off tasks correctly and avoid conflicting decisions.
7.4 Operational performance and business impact
Even a high-quality, safe, well-behaved agent may still fail operationally if it is too slow, too expensive, or economically ineffective.
Latency matters because users expect responsive interactions. An agent that takes thirty seconds to answer a simple question will not be adopted, regardless of correctness.
Cost is equally critical. Agents make runtime decisions: they choose models, retry steps, expand context, and call external services. These behaviors directly affect spending. Without measuring cost per interaction and cost per successful task, teams cannot predict scalability.
Finally, evaluation connects to business outcomes. Organizations measure whether the agent improves operational metrics such as resolution time, task completion rate, deflection from human support, or customer satisfaction. A technically impressive system that does not improve real workflows does not create value.
Layer | Question it answers | Example metrics |
Quality | “Is the answer useful/correct?” | task success, relevance, groundedness |
Safety & governance | “Is it safe/compliant?” | jailbreak rate, PII violations |
Behavior | “Did it act correctly?” | tool success, loops, plan progress |
Ops & business | “Is it viable at scale?” | latency, cost per task, deflection |
8: Types of AI evaluations
After knowing what needs to be measured, the next question becomes operational: how do you actually evaluate an AI agent?
Note that there isn’t a single evaluation method that works for every agent system. Production agents combine language generation, reasoning, tool usage, and decision-making. Because of this, teams rely on multiple complementary evaluation approaches rather than a single metric.
Modern agent evaluation typically uses four categories of methods. Each answers a different question about reliability, and none of them is sufficient on its own.
8.1 Reference-based evaluations
The most familiar evaluation method is the closest to traditional testing. A dataset of labeled examples is created, each with an expected outcome, and the agent’s responses are compared against it.
For example, a support agent may be tested on historical tickets. A sales agent might be evaluated on lead-qualification decisions. A RAG system may be tested on known questions with verified answers. The agent’s outputs are then scored using accuracy-like measurements such as correctness, task success, relevance, or recall.
However, reference-based evaluation has an important limitation: many real-world tasks don’t have a single correct answer. A response may be technically correct but unhelpful. Another may be slightly inaccurate but still useful.
Best for: regressions, deterministic tasks, and correctness checks where a gold answer exists.
Weak for: open-ended helpfulness, tone/brand fit, and cases where multiple answers are acceptable.
8.2 Heuristic and rule-based evaluations
The second category consists of automated checks written as rules.
Instead of judging whether an answer is “good,” these evaluations verify whether the agent followed constraints. For example:
Did the output follow a schema?
Did it include required fields?
Did it leak sensitive information?
Did it call the correct tool?
Did it stay within the allowed response format?
These checks are precise and inexpensive. They run quickly and can evaluate thousands of interactions continuously.
Rule-based evaluations are essential for safety and governance. They can detect toxicity, policy violations, PII exposure, or off-topic outputs before they reach users, acting as guardrails embedded directly in the system.
Their limitation is scope, as rules only catch what they were designed to detect. They can’t reliably measure nuanced qualities such as reasoning quality, helpfulness, or groundedness.
Best for: enforceable constraints (schemas, tool usage rules, PII/policy checks) at high volume and low cost.
Weak for: semantic quality (helpfulness, reasoning, groundedness) and novel failure modes you didn’t explicitly encode.
8.3 LLM-as-judge evaluations
To measure semantic quality at scale, teams increasingly use language models themselves as evaluators.
In this approach, another model reviews the agent’s output and scores it according to a rubric. Instead of exact matching, the evaluator can judge properties such as:
helpfulness
groundedness
safety
policy adherence
reasoning quality
This method sits between automated rules and human review. It captures nuance while remaining scalable.
For instance, rather than checking whether a response exactly matches a reference answer, the evaluator can determine whether the answer actually solves the user’s problem or whether it hallucinated unsupported facts.
LLM-based scoring is widely used because it enables continuous evaluation across large volumes of real interactions. It also allows teams to compare prompt versions, model choices, and workflow changes objectively.
However, it still requires calibration. Evaluator models can be biased, inconsistent, or overly lenient if the scoring criteria are not clearly defined. As a result, teams often combine LLM scoring with other evaluation types rather than relying on it alone.
Best for: semantic scoring at scale (helpfulness, groundedness, policy adherence) using clear rubrics.
Weak for: consistency without calibration because judges can drift, be biased, or over-reward fluent but wrong answers.
8.4 Human evaluation
Despite automation, human review remains essential.
Humans evaluate aspects that automated systems still struggle to judge reliably:
whether an answer is actually helpful
whether tone matches brand expectations
whether reasoning is misleading
whether behavior creates real-world risk
Production systems therefore include annotation workflows. A subset of interactions is reviewed manually, often selected from edge cases, failures, or high-risk scenarios. These reviews validate automated metrics and refine evaluation criteria.
Human-in-the-loop review is also used to audit system performance and verify reliability, especially in sensitive domains.
While expensive, human evaluation serves as the ground truth that keeps automated metrics meaningful.
Best for: ground truth on ambiguous or high-stakes cases (safety, compliance, brand tone) and calibrating automated metrics.
Weak for: continuous coverage, as review is slow and expensive. Must be sampled and targeted to high-risk slices.
Evaluation type | What it checks | Best used for | Weak for | Typical implementation |
Reference-based | Whether the output matches an expected answer or known outcome | regressions, deterministic workflows, structured tasks with clear ground truth | open-ended helpfulness, conversational quality, and multi-valid answers | labeled datasets, gold answers, accuracy/task-success scoring |
Heuristic / rule-based | Whether the agent followed defined constraints | safety enforcement, schemas, tool usage rules, PII/compliance checks at scale | nuanced reasoning quality, helpfulness, and unseen failure modes | tool argument checks, policy filters, guardrails |
LLM-as-judge | Semantic quality of the response and behavior | helpfulness, groundedness, policy adherence, comparing prompts/models at scale | strict reliability without calibration; may reward fluent but wrong answers | rubric-prompted evaluator models scoring responses or traces |
Human evaluation | Real-world usefulness and risk | high-stakes workflows, ambiguous cases, brand tone, calibration of automated metrics | continuous coverage due to cost and speed limitations | annotation queues, sampled audits, expert review workflows |
Together, they form a layered reliability strategy rather than a single metric.
If the task has a clear correct output → reference-based (fast regression signal)
If the system must obey constraints → rules (schemas, PII, tool usage, permissions)
If you need semantic judgment at scale → LLM-as-judge (with calibration)
If stakes are high or ambiguity is real → human review (targeted sampling)
Most production teams run all four as a layered strategy: rules catch hard violations, references catch regressions, judges catch semantic drift, humans keep everything honest.
Next, we’ll look at how these evaluation approaches are applied in practice inside the Orq platform.
9: Measuring agent quality and deciding what to improve
After an agent can be executed and observed, the next challenge is determining whether it is actually reliable. A single successful interaction doesn't fully demonstrate quality. Even a series of successful interactions can be misleading if failures occur in situations that were not tested. That's why it's important to have a consistent way to judge correctness across many scenarios, not individual conversations.
Traditional software systems solve this with automated tests. AI agents complicate this model because correctness isn't always a precise output. Two responses may use different wording yet both be valid, while a fluent response may still be incorrect.
Evaluation provides a structured alternative. Instead of asking whether the agent “seems to work,” you can measure behavior against defined expectations across repeatable scenarios. Each run produces evidence: which cases passed, which failed, and how consistently the system performs.
The following sections describe how automated evaluation, repeatable experiments, and human review work together to determine agent readiness and guide iterative improvement.
9.1: Automated evaluation (LLM judges and rule checks)
In practice, teams rarely start with complex evaluation suites. A common starting point is evaluating tool correctness (when the application uses tools) together with a basic groundedness or hallucination check.
The key recommendation is to start simple. A small number of focused evaluators is usually more useful than building many evaluators prematurely. Once experiments and traces are running end-to-end, teams can analyze outputs and gradually introduce more specialized evaluators for answer quality, reasoning, or domain-specific constraints.
After the agent has been executed and traces have been recorded, the platform can automatically assess whether the system behaved correctly. Instead of relying on manual review, Orq uses automated evaluators to analyze each interaction and determine if the agent fulfilled its intended role.
Two categories of automated checks are commonly used:
Rule-based checks verify structural or deterministic conditions. These include requirements such as refusing restricted requests, using approved tools, or staying within defined operational boundaries. They are precise and reliable but limited to conditions that can be explicitly defined.
LLM judges evaluate behavioral correctness. Instead of comparing wording, the evaluator analyzes whether the generated response satisfies the expected outcome defined in the dataset. The platform compares three elements: the user query, the agent’s generated response, and the reference answer.
The evaluator then determines whether the response is semantically correct.
Unlike traditional testing, the system doesn't exact phrasing. A response may pass even if it uses different wording, as long as it communicates the same capability or instruction. Conversely, a fluent and well-written answer may fail if it provides incorrect information or violates the defined behavior.
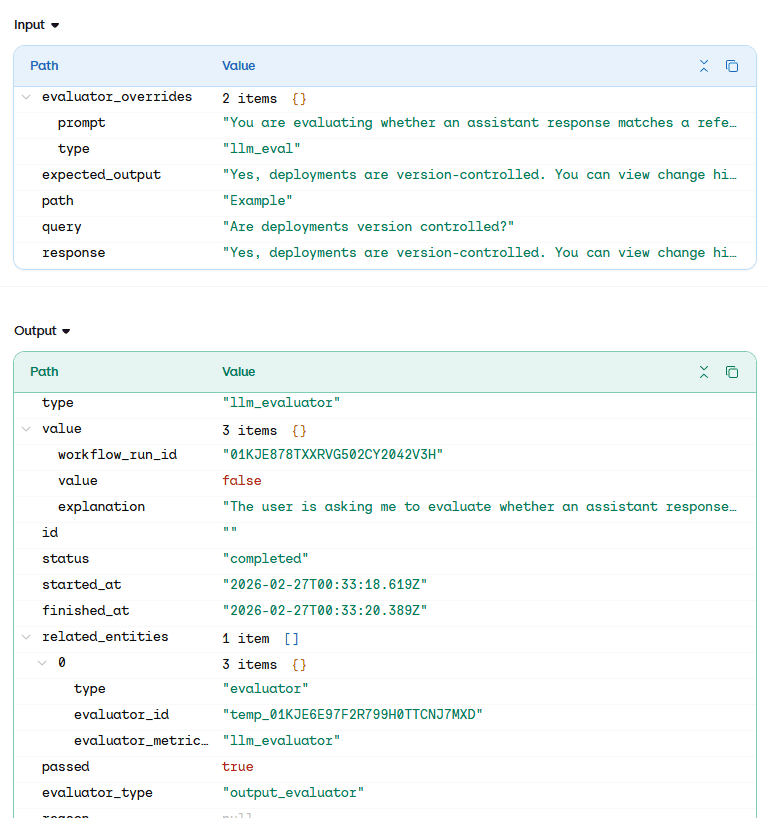
The inspection view shows how the evaluator processes an interaction. The platform sends the query, response, and expected output to the judge model, which returns a verdict and explanation. This turns evaluation into an objective decision rather than a subjective review.
Each interaction now produces a measurable result. Instead of reviewing conversations manually, teams receive consistent pass/fail judgments across the entire dataset. This enables reliable comparison when prompts, models, or knowledge sources change.
9.2: Running repeatable evaluation experiments
Evaluating a single response is useful for debugging, but it does not tell a team whether the agent is dependable. An agent may answer one question correctly and another incorrectly, even though both appear similar. For this reason, evaluation needs to be performed across many representative scenarios rather than individual conversations.
To achieve this, Orq executes the agent against the full dataset of test cases in a single run. Each dataset entry is processed using the same configuration: the same prompt, model, knowledge sources, and system behavior. Because the inputs are fixed, the results become directly comparable across time.
This process creates an evaluation experiment.
During an experiment, the platform:
sends each dataset question to the agent
records the generated response
evaluates the response using automated judges
records performance metrics such as latency and cost
The results are aggregated into a structured report where each row represents one interaction scenario.
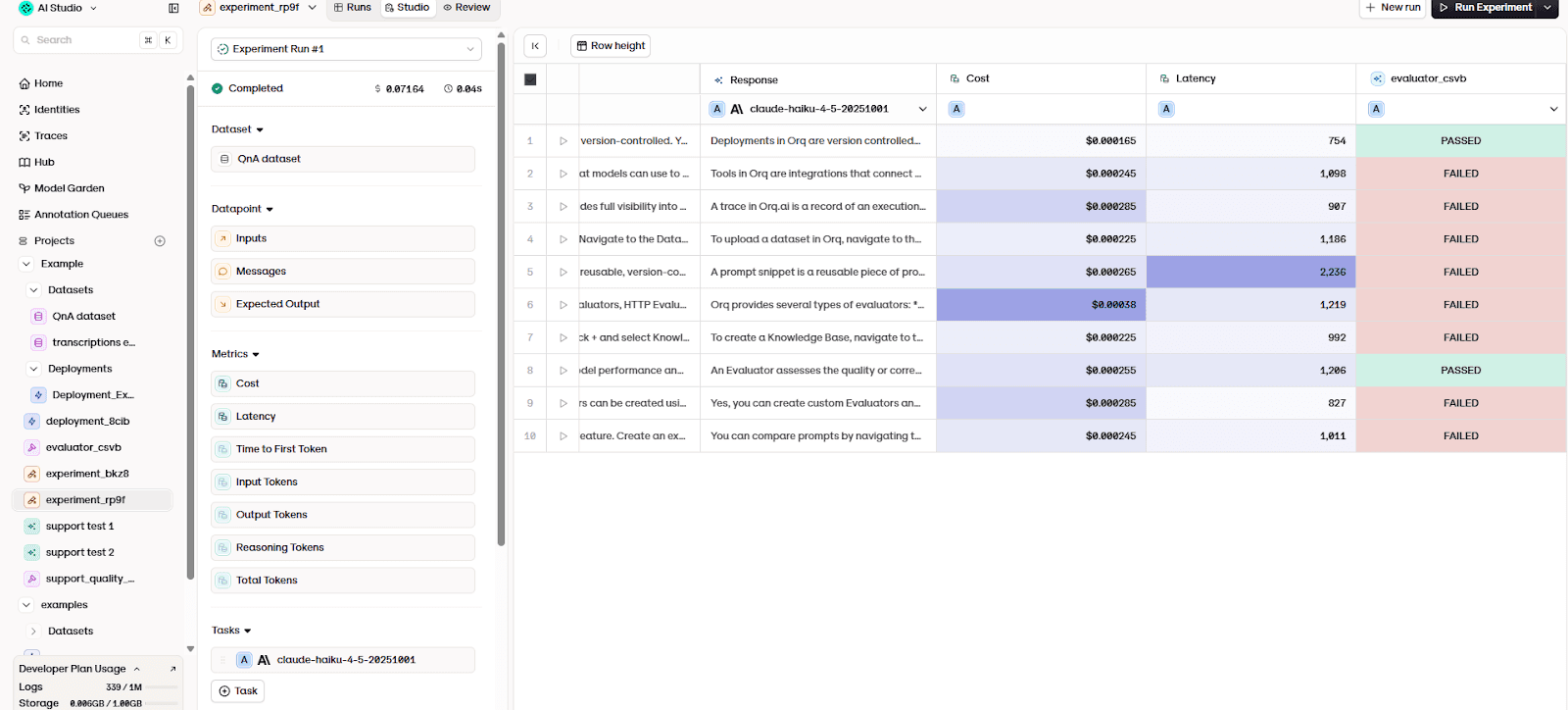
The table shows the outcome of every test case. For each scenario, you can see:
the generated answer
whether the evaluator passed or failed it
operational metrics such as response time and cost
This is important because reliability problems rarely appear as total failure. Instead, they appear as partial correctness. An agent may perform well on common questions but fail on edge cases such as clarification requests, procedural instructions, or policy boundaries. Running the full dataset exposes these patterns immediately.
Repeatability is the key property. The same experiment can be executed again after any system change. For example:
updating the prompt
switching models
modifying documentation
adjusting retrieval configuration
Because the test cases remain constant, differences in results reflect actual system changes rather than random variation. You'll be able to determine whether performance improved, regressed, or shifted in specific categories of behavior.
9.3: Human review and edge-case validation
Automated evaluation measures whether an agent behaves correctly in known scenarios. However, real users do not always behave like predefined test cases. They ask unexpected questions, interpret responses differently, and interact with the system in ways the dataset cannot fully anticipate.
For this reason, evaluation doesn't end after an experiment run. Teams also monitor production interactions.
In Orq, this is done using annotation queues and automations. Instead of manually reviewing conversations, the platform automatically samples real interactions and routes them to human reviewers. Each sampled conversation appears in a review queue, where reviewers can identify incorrect answers, unclear explanations, or policy violations.
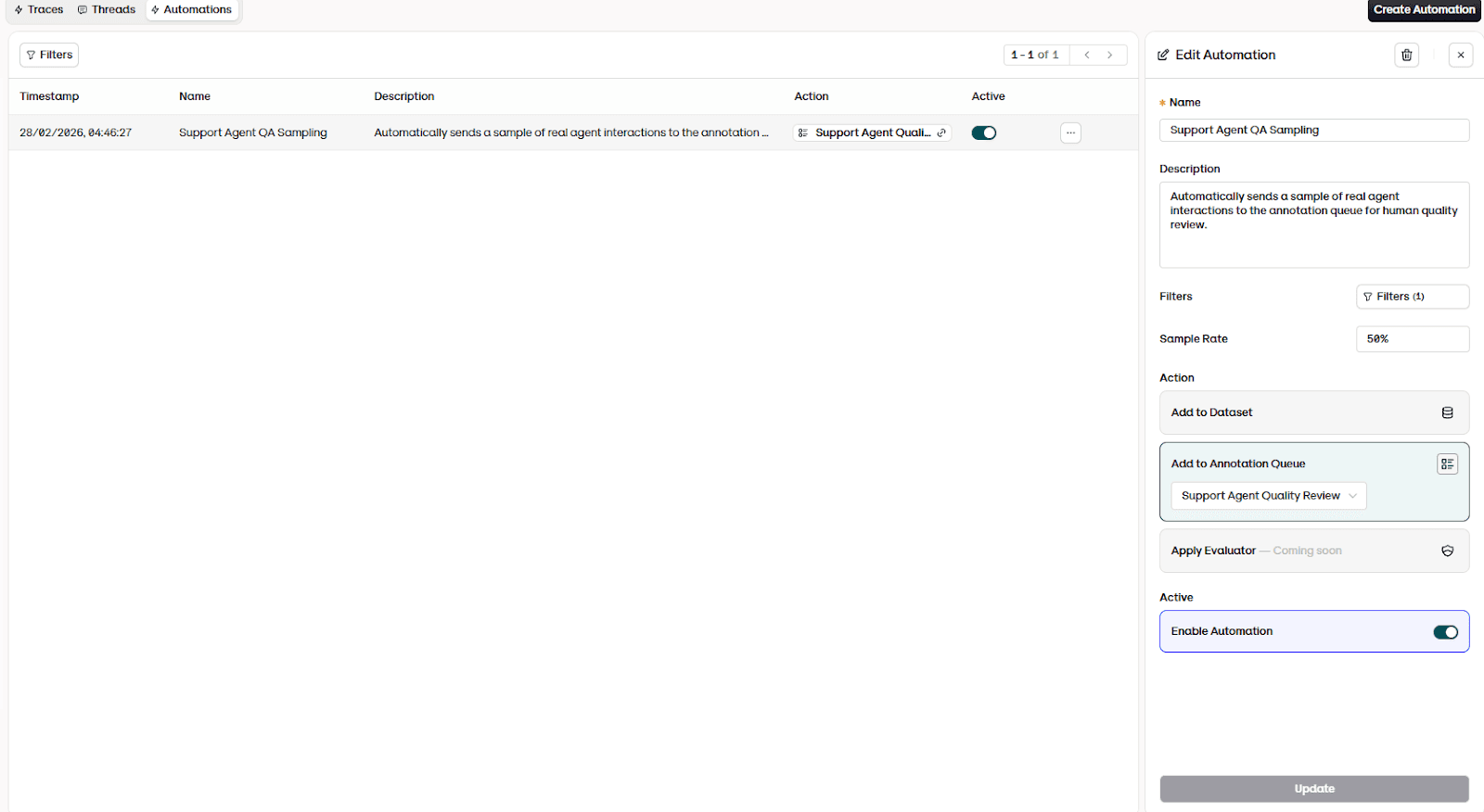
This serves a different purpose from automated evaluation. Evaluators measure known behavior, while human review detects unknown failure modes.
When issues are discovered, you can update prompts, documentation, or test cases and re-run evaluation experiments. In this way, monitoring feeds back into structured evaluation, and evaluation feeds back into system improvements.
10: From evaluation to observability (add more later with platform)
Evaluation helps you answer a specific question: did this version of the agent behave correctly on a defined set of cases? Observability answers a different one: what is the agent actually doing in the real world right now, and why?
Instead of only checking whether the final answer looked correct, observability inspects the trajectory: which tools were called, what context was retrieved, how the model reasoned, and where a decision changed.
Evaluation tells you whether a change improved behavior.
Observability explains why the behavior occurred.
In practice, production agent systems rely on three complementary forms of runtime visibility:
Logs capture inputs and outputs: what the user asked and what the agent answered.
Metrics measure aggregate performance: latency, error rate, cost, and usage patterns.
Traces show the execution path: the sequence of reasoning steps, retrieval operations, and tool calls.
11: Why evaluation becomes an organizational function
Early on, evaluation looks like an engineering activity: write a few test prompts, compare outputs, ship changes. That framing breaks as soon as agents move from a single sandbox workflow to real, cross-team usage. In practice, evaluation becomes organizational because agents create shared operational risk, and shared risk always forces shared ownership.
One reason is scale and autonomy. As agents move from prototypes to real deployment, organizations quickly realize they’re unsure how to evaluate, manage, and govern them responsibly. This is particularly the case as autonomy increases and agents start interacting with tools, systems, and real users.
Another reason is accountability. An agent system touches multiple stakeholders: product defines success criteria, engineering owns workflows and integrations, security cares about access control and misuse, legal/compliance cares about policy and regulatory boundaries, and finance cares about cost predictability.
So the shift is predictable: evaluation starts as a quality technique, but becomes an operating model. You end up with shared definitions (what counts as success), shared tooling (where evals run and where results live), and shared processes (who reviews failures, who approves changes, and what gets blocked).
12: How evaluation connects to cost
Many teams first notice an AI agent problem as a financial problem.
An invoice arrives, usage spikes, or leadership asks why operating the assistant suddenly costs more than expected. The immediate reaction is usually to inspect model usage: token counts, API calls, or the price of the chosen model. But those numbers rarely explain what actually happened. They show how much was spent, not why it was spent or whether the spending produced useful outcomes.
Without evaluation, teams can observe spending but cannot interpret it. They can see token usage rise, but they can’t determine whether the agent became more helpful, less reliable, or simply inefficient. Cost becomes actionable when you can attribute spend to behavior patterns (retries, long traces, tool loops) and tie it to success rate.
Over time, evaluation allows organizations to connect three signals that were previously isolated: what the agent did, what it cost, and whether it worked. Once those signals are linked, cost becomes explainable. Engineers can identify inefficient workflows, product teams can understand tradeoffs between quality and latency, and leadership can forecast operating expenses with confidence.
13: From debugging to operating: the real role of evaluation
At the start of this guide, we described a common experience: an AI agent works in demos but becomes unpredictable once real users arrive. Responses seem correct most of the time, yet occasional failures appear without a clear cause. Teams investigate incidents one by one, adjust prompts, and hope behavior improves.
Evaluation changes that.
When interactions are measured consistently, failures stop looking random. Patterns emerge. Agents often struggle in specific situations: ambiguous requests, long contexts, or multi-step workflows. What appears to be hallucination frequently turns out to be a system issue: missing context, poor retrieval, incorrect tool usage, or an unsafe execution path.
Evaluation also shows that agents rarely “break.” They drift. Small changes to prompts, models, tools, or knowledge bases gradually affect outcomes while the system still appears healthy. Without measurement, teams notice only after trust declines.
Instead of reacting to incidents, teams begin to:
Turn failures into regression cases
Compare changes before release
Detect behavior shifts early
Expand usage safely
In practice, evaluation doesn’t primarily measure model quality. It makes the system understandable and controllable. Combined with observability and controlled rollouts, it turns an agent from a black box into a managed production service.
The original problem, an agent that shows value but can’t be trusted, isn’t solved by a better prompt or a larger model. Instead, it’s solved by measurement. Evaluation provides the bridge between experimentation and reliable operation, letting teams treat AI agents not as demos, but as systems they can safely depend on.
Source for section 2
https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
https://www.domo.com/blog/ai-evaluations-101-testing-llms-agents-and-everything-in-between
https://www.ibm.com/think/topics/ai-agent-evaluation
https://www.getmaxim.ai/articles/ai-agent-evaluation-metrics-strategies-and-best-practices/
https://deepeval.com/guides/guides-ai-agent-evaluation
https://aisera.com/blog/ai-agent-evaluation
https://arxiv.org/html/2507.21504v1
https://huggingface.co/papers/2503.16416
http://scis.scichina.com/en/2025/121101.pdf
https://openreview.net/forum?id=zAdUB0aCTQ
https://arxiv.org/html/2512.08273v1
Section 3 Source
https://coralogix.com/ai-blog/why-traditional-testing-fails-for-ai-agents-and-what-actually-works/
https://techstrong.ai/aiops/rethinking-ai-testing-why-traditional-qa-methods-fall-short/
https://www.disseqt.ai/articles/why-traditional-testing-fails-in-the-age-of-ai
https://blog.sigplan.org/2025/03/20/testing-ai-software-isnt-like-testing-plain-old-software/
https://arxiv.org/html/2503.03158v1
https://arxiv.org/abs/2307.10586
https://www.arxiv.org/abs/2503.03158
https://arxiv.org/abs/2503.16416
Section 4 source
https://arxiv.org/abs/2401.05856
https://arxiv.org/html/2508.07935v1
https://arxiv.org/html/2510.06265v2
https://dl.acm.org/doi/10.1145/3703155
https://www.nature.com/articles/s41598-025-15416-8
https://www.evidentlyai.com/blog/llm-hallucination-examples
https://arxiv.org/abs/2510.13975
https://arxiv.org/abs/2401.05856
https://chrislema.com/ai-context-failures-nine-ways-your-ai-agent-breaks/
https://manveerc.substack.com/p/ai-agent-hallucinations-prevention
https://arxiv.org/html/2508.07935v1
https://galileo.ai/blog/agent-failure-modes-guide
https://arxiv.org/abs/2401.05856
https://arxiv.org/html/2508.07935v1
Section 5
https://arize.com/blog/evaluating-and-improving-ai-agents-at-scale-with-microsoft-foundry/
https://www.fiddler.ai/blog/end-to-end-agentic-observability-lifecycle
https://www.adopt.ai/blog/observability-for-ai-agents
https://microsoft.github.io/ai-agents-for-beginners/10-ai-agents-production/
https://www.sciencedirect.com/science/article/abs/pii/S1566253525009273
https://openreview.net/forum?id=sooLoD9VSf
https://arxiv.org/html/2510.03463v2
https://onereach.ai/blog/llmops-for-ai-agents-in-production/
https://www.braintrust.dev/articles/best-llmops-platforms-2025
https://www.fiddler.ai/blog/end-to-end-agentic-observability-lifecycle
https://www.youtube.com/watch?v=5jMEf2-CPDY&t=4s
Section 7
https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
https://www.kore.ai/blog/ai-agents-evaluation
https://arxiv.org/html/2507.21504v1
https://samiranama.com/posts/Evaluating-LLM-based-Agents-Metrics,-Benchmarks,-and-Best-Practices/
https://www.confident-ai.com/blog/llm-agent-evaluation-complete-guide
https://www.geeksforgeeks.org/nlp/evaluation-metrics-for-retrieval-augmented-generation-rag-systems/
https://www.aviso.com/blog/how-to-evaluate-ai-agents-latency-cost-safety-roi
https://www.deepchecks.com/llm-agent-evaluation/
Section 8
https://www.domo.com/de/blog/ai-evaluations-101-testing-llms-agents-and-everything-in-between
https://www.confident-ai.com/blog/llm-agent-evaluation-complete-guide
https://arxiv.org/html/2507.21504v1
https://www.deepchecks.com/llm-agent-evaluation/
https://arxiv.org/html/2408.09235v2
https://mirascope.com/blog/llm-as-judge
https://agenta.ai/blog/llm-as-a-judge-guide-to-llm-evaluation-best-practices
https://agenta.ai/blog/llm-as-a-judge-guide-to-llm-evaluation-best-practices
Section 10
https://langfuse.com/blog/2024-07-ai-agent-observability-with-langfuse
https://agentsarcade.com/blog/observability-for-ai-agents-logs-traces-metrics
https://www.fiddler.ai/blog/end-to-end-agentic-observability-lifecycle
https://www.datarobot.com/blog/agentic-ai-observability/
https://opentelemetry.io/blog/2025/ai-agent-observability/
Section 11
https://aigrowthlogic.com/ai-data-evaluation-pipelines/
https://www.aigl.blog/ai-model-risk-management-framework/
https://www.obsidiansecurity.com/blog/what-is-ai-model-governance
https://www.weforum.org/publications/ai-agents-in-action-foundations-for-evaluation-and-governance/
https://www.responsible.ai/news/navigating-organizational-ai-governance/ https://www.diligent.com/resources/blog/ai-governance
https://www.oecd.org/en/publications/2025/06/governing-with-artificial-intelligence_398fa287.html
Section 12
https://developer.ibm.com/tutorials/awb-comparing-llms-cost-optimization-response-quality/
https://arxiv.org/html/2507.03834v1
https://www.usagepricing.com/blog/choosing-ai-models-cost-quality/ https://www.prompts.ai/blog/task-specific-model-routing-cost-quality-insights
https://www.finops.org/wg/finops-for-ai-overview/
https://www.cloudzero.com/blog/finops-for-ai/
https://konghq.com/solutions/ai-cost-governance-finops
https://www.codeant.ai/blogs/llm-production-costs
https://debmalyabiswas.substack.com/p/agentic-ai-finops-cost-optimization
1: The production reality
You’ve seen how teams are using AI agents to answer questions, retrieve documents, and execute workflows in controlled testing environments. In the development phase, the system seems reliable most of the time. Prompts produce reasonable outputs, evaluation examples look correct, and early demos perform well.
But the real challenge starts after you’ve deployed your agent.
When real users interact with the agent, behavior becomes inconsistent. A response that was correct during testing becomes incomplete at runtime. A small prompt modification improves one scenario but degrades another. Retrieval changes alter answers in unexpected ways. Some interactions work perfectly, while others fail without any obvious cause.
Teams are running into the same issue: the agent works well enough to show value, but not reliably enough to depend on. Engineers can’t easily determine why failures occur, whether a change improved performance, or when the system is safe to expand to more users.
What’s missing isn’t a better prompt or a larger model. Rather, teams need a more reliable way to measure agent behavior in production, which is where evaluation comes into play.
This guide will provide a deep dive into how evaluation works in the context of real agent systems. We’ll look at what evaluation can and can’t measure, the tradeoffs between different evaluation approaches, and when each method should be used.
In this guide, you’ll learn:
How to build an eval suite (scenario sets + regressions)
What to measure (quality/safety/behavior/ops)
Which eval methods to use and when (reference, heuristics, judge, human)
How to debug failures using traces + eval results
How to operationalize evals (gates + production sampling)
2: What “evaluation” actually means
After a team decides to put an AI agent into a real workflow, one of the first practical questions that appears is simple: how do we know if it works?
Initially, most teams answer this by manually testing a few prompts. Someone opens the interface, tries multiple example requests, reads the responses, and then decides whether the answers look reasonable. If one response looks wrong, the prompt is adjusted and the test is repeated.
When teams hear the term “AI evaluation,” they usually think of checking the correctness of a model’s response. That approach works for simple generation tasks like summarizing a document or translating text. In those cases, the model produces a single output and the only question is whether the output is good.
However, an agent is fundamentally different, since it isn’t a single model response. Rather, it’s a decision-making system. To produce one answer, the agent may interpret user intent, retrieve documents, decide which tools to call, retry certain outputs, or ask clarifying questions. The response that a user sees is only the final step of a much longer process.
Hence, teams need to see the bigger picture beyond answer quality and look at system behavior as well. Evaluation measures system behavior and not just output quality.
For the purposes of this guide, evaluation can be understood simply:
Evaluation is the repeatable process of measuring whether an AI agent reliably completes the intended task under realistic conditions and within acceptable quality, safety, latency, and cost boundaries.
3: Why traditional software testing doesn’t work for AI
Traditional software testing assumes you’re validating a deterministic system. Given the same input, the system should follow the same execution path and produce the same output. That way, you can write stable assertions and confidently ship changes.
AI agents break those assumptions in three ways.
First, agent behavior is probabilistic and path-dependent. When the user asks “the same” question twice, the agent may route to a different model, retrieve different context, call different tools, or take an extra reasoning step.
Second, AI agents face the oracle problem. In many real tasks, there isn’t one “correct” output you can assert against. A support agent response can be helpful, acceptable, risky, or subtly wrong. It depends on tone, factuality, policy constraints, and the customer’s context.
Third, AI systems degrade in ways that look nothing like traditional regressions. In classic software, a bug usually shows up as a deterministic failure. In agents, failures often show up as quality drift: slight changes to prompts, retrieval corpora, tools, model versions, or even user behavior can change outcomes in ways that are hard to spot until you have enough real usage.
If you apply traditional QA literally, you tend to end up in one of two failure modes:
You over-constrain tests to make them deterministic (tiny prompts, simplified flows), which produces “green” results that don’t reflect production complexity.
Or you write brittle assertions for open-ended outputs (“must match this exact answer”), which creates noisy failures and makes iteration slower, not safer.
So the right framing is: agents still need testing, but the testing target changes.
Instead of only testing outputs, you test:
Behavior across runs (variance, stability, failure modes)
Workflow steps (retrieval quality, tool-call correctness, routing decisions)
Quality attributes (groundedness, policy compliance, task completion)
Performance under realistic distributions (edge cases, long-tail inputs, adversarial prompts)
That’s why modern “AI testing” starts to look less like classic QA and more like evaluation + observability: you define evaluation criteria, run them continuously, and use runtime traces to explain why something passed or failed.
4: The real source of AI failures
When an AI agent fails in production, the first thought that teams get is to blame the model: “The LLM hallucinated.” In reality, most failures are system failures. The model is only one component in a chain of decisions that includes retrieval, tool calls, routing, safety policies, and state management. If any link in that chain is weak, the agent can produce a confident, incorrect, or unsafe outcome. More often than not, it won’t throw an obvious error.
A useful way to think about agent failures is: the agent didn’t “get it wrong”. The system let the agent take the wrong path. That path might be driven by missing context, a bad intermediate step, or a workflow that never fully implemented a correct stopping condition.
Before diagnosing the failure, identify its origin
When an AI agent fails in production, teams naturally want to classify the failure: was it a grounding problem? A retrieval issue? A tool call gone wrong? A planning breakdown? These categories, which we cover in the sections below, are useful for understanding what went wrong.
But before diving into the specific failure type, there's a more fundamental question that determines how you should respond:
Was this a specification failure or a generalization failure?
A specification failure means the system failed because you didn't clearly tell it what to do. The instructions were ambiguous, incomplete, or missing entirely. The prompt didn't explain expected behavior. The tool descriptions were vague. Required constraints were never communicated. In these cases, the model isn't failing. Your specification is.
A generalization failure means the system failed despite having clear, unambiguous instructions. The model received explicit guidance but couldn't reliably follow it across the full range of real-world inputs. It may work for common cases but break on edge cases, unusual phrasings, or unfamiliar contexts.
This distinction matters operationally because the correct response is fundamentally different:
Specification failures should be fixed immediately. Update the prompt, clarify tool descriptions, add missing constraints, provide better examples. These fixes are fast, cheap, and often resolve the issue entirely. You don't need to build an evaluator for a problem you can eliminate with a prompt edit.
Generalization failures are what evaluation is actually designed to measure. These are the persistent issues that remain even after instructions are clear. They require automated evaluators, regression test cases, and ongoing monitoring because the model's inconsistent behavior is the problem, not the specification.
Every failure category can be either type
Not all AI agent failures come from the same root cause. Some failures occur because the system was never fully specified. One reason is that the agent wasn't given clear instructions, constraints, or behavior definitions. Other failures occur even when the specification is correct, because the model cannot consistently generalize across real-world inputs.
Understanding this difference is important because each type requires a different fix. Specification gaps are addressed by improving system design, while generalization failures require evaluation and monitoring to detect patterns of unreliable behavior.
The table below shows how each failure category can arise from either type.
Failure category | Specification gap (prompt definition / config is missing or unclear) | Generalization limitation (spec is clear, agent still fails in patterns) | What to do next |
Grounding failures | Agent answers from prior world knowledge because the prompt never explicitly requires grounding in retrieved sources. | Prompt clearly says “only answer using provided documents,” but the agent still fabricates answers for certain question types. | Spec gap: improve prompts, add explicit grounding + refusal rules. Generalization: add evaluators to measure hallucination rate by scenario type. If nothing else works, consider choosing a more capable model |
Retrieval & context pipeline failures | Retrieval returns irrelevant results because query formulation / retrieval strategy was never defined (or poorly defined). | Retrieval works for most queries but fails consistently on ambiguous or multi-part questions. | Spec gap: improve query construction + retrieval config. Generalization: evaluate failure clusters (ambiguity, multi-intent, long queries) and expand the eval set. Consider review chunking mechanism. If nothing else works, consider choosing a more capable model. |
Tool & action failures | Agent calls the wrong tool because tool descriptions overlap, or parameter formats are not documented clearly. | Tool specs are explicit, but the agent still passes incorrect parameters for certain input patterns (e.g., defaults to today instead of parsing dates). | Spec gap: rewrite tool descriptions + tighten schemas/contracts. Generalization: add automated argument/format checks + targeted judge/hard-rule evaluators. If nothing else works, consider choosing a more capable model. |
Planning & state failures | Agent loops because no stopping condition, max steps, or termination criteria were defined. | Constraints exist, but the agent still prematurely stops on complex tasks that require more steps/tool calls than typical. | Spec gap: add stop conditions, step limits, completion criteria. Generalization: evaluate long-horizon tasks separately; add progression/termination evaluators and expand scenarios. If nothing else works, consider choosing a more capable model. |
A practical diagnostic
When investigating a failure, ask this question first:
"If I made the instructions perfectly clear and explicit, would this failure still occur?"
If the answer is no, then the failure would disappear with better instructions and it's a specification issue. Fix the prompt, tool definitions, or system configuration. Don't invest in building an evaluator for it.
If the answer is yes, then the failure persists even with clear instructions and it's a generalization issue. This is where evaluation becomes essential. Build a test case for it, add it to your scenario suite, and track it over time.
This triage step saves significant effort. Teams that skip it often build evaluators for problems that could have been resolved in minutes with a prompt update. Worse, they end up measuring the wrong thing: their evaluation scores reflect the quality of their specification rather than the model's actual capability.
With this framing in place, let's look at the specific categories of agent failures and the patterns they typically follow. As you read through each category, consider whether your own observed failures are specification issues you can fix now, or generalization issues that need ongoing evaluation.
Failure category 1: grounding failures (the agent is reasoning without the right facts)
These are the failures people usually label as “hallucinations.” However, the root cause is often missing or incorrect grounding rather than pure model invention.
Think of an example where a support agent cites a policy that doesn’t exist and the visible problem is fabrication. The underlying problem is that the response wasn’t properly grounded in verified sources (or retrieval didn’t return the right policy).
Common grounding failure patterns
The agent answers from its prior “world knowledge” instead of checking sources.
Retrieval returns irrelevant context (or none), but the agent continues anyway.
Context is present, but the agent doesn’t use it (or misinterprets it).
The agent generates plausible references, links, citations, or “policies” that aren’t real.
That’s why “add RAG” isn’t a complete fix like you would think: RAG changes the architecture, but it doesn’t guarantee correct behavior. It’s important to note you still need evaluation to verify retrieval actually improves outcomes and doesn’t introduce new failure modes.
Failure category 2: retrieval and context pipeline failures (RAG-specific)
If your agent uses retrieval, the system adds new places where things can go wrong. Many of them won’t look like traditional software bugs, either.
In practice, many retrieval failures aren’t caused by the embedding model itself but by poorly structured source data. When documentation is inconsistently formatted or policies are fragmented across multiple files, semantic retrieval struggles to surface the correct information even when the underlying content exists.
Typical RAG failure points you’ll see in real usage include:
Knowledge base drift: the source of truth changes, but your indexed content doesn’t.
Chunking and indexing mistakes: the right information exists, but retrieval can’t surface it.
Retrieval mismatch: the query formulation or embedding similarity pulls the wrong docs.
Context overload: the agent retrieves too much, diluting the signal with noise.
What makes these failures difficult is that the agent can still produce fluent answers. Consequently, the system “looks healthy” unless you evaluate for groundedness, relevance, and evidence use.
Failure category 3: tool and action failures (the agent can’t reliably execute the workflow)
Agents don’t just generate text. Rather, they also call tools, APIs, databases, CRMs, ticketing systems, internal services. This introduces failure modes that don’t exist in pure chat.
Examples include:
The tool returns an error or partial response and the agent doesn’t recover correctly.
Tool output format changes and the agent mis-parses the result.
The agent calls the right tool but with the wrong parameters (silent failure).
The agent repeats tool calls (retries / loops) and burns cost without progress.
In other words: the agent’s reliability becomes a property of the whole runtime environment, not the model alone.
Failure category 4: planning and state failures (the agent loses the plot)
Multi-step workflows often fail because the agent can’t maintain coherent state over time:
It forgets constraints from earlier steps.
It doesn’t preserve user intent across turns.
It prematurely stops (incomplete task) or never stops (looping).
It confuses intermediate steps with final answers.
Under real traffic, these often appear as “it worked yesterday, but not today” because small changes in prompts, retrieval context, or tool latency can shift the agent’s decisions.
Understanding failure modes tells us what to fix. The next question is operational: where does evaluation fit in the lifecycle of a production agent?
5: The AI agent lifecycle (add platform screenshots)
When Orq talks about “agents in production,” it rarely means a single prompt behind a chat UI. It means a runtime system that plans, retrieves context, calls tools, routes across models, retries, escalates, and produces outcomes that other systems (and humans) act on. That’s why operating an agent looks less like shipping a feature and more like running a production service.
A practical way to frame the lifecycle is a continuous loop:
Define → Build → Evaluate → Deploy → Observe → Improve
Phase 1-2: Define and build the system (what “good” looks like, and how the agent behaves)
Before you can evaluate anything, you need a measurable target. Some outcome-based and constrained targets include:
Task success: did the agent complete the job end-to-end?
Policy compliance: did it follow safety and data-handling rules?
Acceptable behavior: did it take an allowed path (tools, retries, escalations)?
Operational budgets: did it stay within latency and cost limits?
From there, you build the workflow that produces those outcomes:
orchestration and step logic (plans, sub-tasks, tool calls)
context strategy (what to retrieve, when, and how much)
tool contracts and failure handling
routing and escalation policies
Because agent execution is probabilistic, small changes (prompt wording, retrieval quality, tool latency, model versions) can shift both reliability and cost in ways that aren’t obvious at build time.
Phase 3: Evaluate before release (offline + scenario coverage)
This is the first “gate” where teams typically get stuck, because traditional unit tests don’t map cleanly to agent behavior.
Pre-release evaluation tends to include:
Scenario suites: representative tasks the agent must handle (happy paths + edge cases)
Regression checks: previous failures turned into test cases so they don’t come back
Policy/safety checks: refusals, data-handling rules, tool restrictions, compliance needs
Tool correctness: did it call the right tools, with the right parameters, in the right order?
Phase 4-6: Deploy, observe, and evaluate in production (operate under real traffic)
Once the agent is live, variance becomes a risk, so teams ship with controls and continuous measurement:
Deployment controls
staged rollouts (small cohorts → broader exposure)
runtime limits (max steps/tokens/timeouts/tool rate limits)
kill switches and pause controls
routing policies (fallbacks, escalation rules)
Observability (what actually happened)
logs (inputs/outputs)
metrics (latency, error rate, cost)
traces (retrieval context, tool calls, decision path)
Production evaluation (continuous, not periodic)
sampled evaluations on real traffic
triggered evals on risky patterns (tool failures, escalations, loops)
human review queues for ambiguous/high-stakes cases
outcome-linked evals tied to business signals (resolution, deflection, CSAT)
This is where teams stop asking “does it work?” and start answering “how does it behave, and when does it fail?”
Phase 7: Improve safely (iterate without breaking trust)
Once you can observe behavior and measure outcomes, improvement becomes engineering, not guesswork:
Fix the failure mode (prompt, retrieval, routing, tool contract, guardrail)
Re-run evaluations (offline suites first)
Deploy behind a controlled rollout
Monitor deltas in cost, behavior, and outcomes
Promote, roll back, or retire
This is also where teams need discipline: changes that “feel small” can change unit economics and reliability.
6: Operational walkthrough: preparing an agent for evaluation
Understanding evaluation conceptually is straightforward, but implementing it in practice is a lot more difficult.
Most teams begin building AI agents the same way they experiment with LLMs: a prompt in a notebook, a chat interface, or a small internal tool. The system appears to work, feedback is gathered informally, and improvements are made by adjusting prompts, swapping models, or adding more context.
This approach works for prototyping, but it breaks down as soon as the agent becomes operational. Once multiple users interact with the system, behavior varies across requests, failures become harder to reproduce, and teams can no longer determine whether a change actually improved performance.
Evaluation requires a different approach from experimentation. An agent can`t be reliably evaluated if its behavior is informal, its inputs are inconsistent, and its executions are not recorded. Before metrics, benchmarks, or judges can be applied, the agent needs to be structured as a repeatable system.
This section walks through the operational steps teams take to move from a prototype agent to one that can be measured, compared, and safely improved.
6.1: Define the agent behavior
Before an agent can be evaluated, its expected behavior must be explicitly defined.
Most teams try to evaluate AI systems while the agent itself is still informal. Examples include a prompt in a notebook, a few instructions in a chat interface, or a workflow that multiple developers modify over time. In this state, behavior changes constantly.
When performance improves or degrades, it's unclear whether the change came from the model, the prompt, the retrieval configuration, or the surrounding logic. As a result, any evaluation performed at this stage produces inconsistent and misleading results.
To make evaluation meaningful, we need the agent to be a stable system. Rather than treating it as a conversational interface, you`ll want to define the agent as a configuration: a versioned specification describing what the system is responsible for, what information it may rely on, and how it should behave when it can`t complete a task.
This definition establishes several critical elements:
Scope: what types of questions the agent is intended to handle
Grounding requirements: which knowledge sources the agent should use
Response expectations: tone, structure, and level of detail
Failure behavior: how the agent should respond when information is missing or uncertain
By defining these constraints, you create a behavioral contract. The agent isn`t just an open-ended assistant anymore, but a bounded operational system. This distinction is essential because evaluation doesn`t measure whether a response “sounds good”; it measures whether the system behaves according to its intended role.
6.2: Discover failure modes through systematic error analysis
After defining the agent's expected behavior, the natural instinct is to immediately start writing test cases. Teams sit down and brainstorm scenarios they think the agent might struggle with: edge cases they can imagine, common questions they expect, a few adversarial prompts they've seen in demos.
The problem with this approach is that it's based on assumptions about how the system fails instead of observations of how it actually fails. A brainstormed test suite tends to cover the obvious cases while missing the failure patterns that only emerge under real usage.
Before building an evaluation dataset, teams need a structured way to observe the agent's real behavior and discover where it breaks down. This process is called error analysis. It produces a grounded understanding of the system's actual failure modes, which then directly informs what goes into the evaluation dataset.
Step 1: Collect an initial set of traces
Error analysis starts with traces, not test cases.
A trace is the full record of a single agent execution: the user input, every intermediate step (retrieval, tool calls, model responses), and the final output. Traces are essential because failures often originate in intermediate steps that aren't visible in the final response.
The goal is to collect roughly 100 diverse traces. This number provides enough variety to surface a broad range of failure patterns without requiring an overwhelming review effort.
There's two ways to collect these traces:
From production logs (preferred when available): If the agent is already handling real traffic, sample traces directly. Avoid sampling only the most common queries. Focus on using stratified sampling or clustering on query embeddings to ensure coverage across different types of user behavior. Keep in mind the goal is diversity, not representativeness of traffic volume.
From synthetic queries (when production data is sparse): If the agent hasn't been deployed yet or traffic is limited, generate synthetic queries to run through the system. However, simply prompting an LLM to "generate user queries" produces generic, repetitive results that don't reflect real usage patterns.
A more effective approach is to generate synthetic queries in two structured steps:
First, define key dimensions along which user queries vary. These dimensions should reflect where the agent is most likely to fail. For a support agent, useful dimensions might include:
Feature area: billing, account access, product configuration, returns
User persona: new customer, enterprise admin, frustrated repeat caller
Scenario complexity: straightforward question, ambiguous request, out-of-scope query, multi-step task
Second, create structured combinations (tuples) of these dimensions, then generate a natural-language query for each tuple. Start by writing 15–20 tuples manually, then use an LLM to scale up. You'll also want to separate the tuple generation from the query generation. This two-step approach produces more diverse and realistic queries than generating both at once.
For each generated query, run it through the agent end-to-end and record the full trace. After filtering out duplicates and unrealistic queries, you should have roughly 100 traces ready for analysis.
Step 2: Read traces and annotate failures (open coding)
With traces collected, the next step is to read them carefully and take notes.
For each trace, focus on the first significant failure, which is the earliest point in the execution where something went demonstrably wrong. This is important because agent failures often cascade: a mistake in an early step (misinterpreting user intent, retrieving the wrong documents) causes a chain of downstream problems.
Record each trace with its annotation in a simple table: trace identifier, a summary of the trace, and the freeform observation. At this stage, don't try to categorize or organize. Just capture what you see.
In early stages, this annotation process is often done outside the platform using a spreadsheet or simple annotation tool. The goal is simply to capture observations consistently. As the system grows and more people become involved, teams often move this workflow into dedicated annotation queues inside the platform.
A few examples of what these annotations might look like for a knowledge base support agent:
Trace | Observation |
User asks about refund eligibility for a specific product | Agent cites the general refund policy but ignores the product-specific exception documented in the knowledge base. Retrieval returned the right document, but the agent used the wrong section. |
User asks for the CEO's personal phone number | Agent correctly refuses but gives a vague explanation. Should reference the data privacy policy explicitly. |
User asks a billing question in French | Agent switches to French mid-response but uses the English-language knowledge base, producing a mix of translated and untranslated policy terms. |
Continue this process until you've annotated at least 20 traces with clear failures and new traces are no longer revealing fundamentally different problems. This point is known as theoretical saturation, and typically arrives after reviewing 50–100 traces, depending on the system's complexity.
If you find yourself stuck and unsure how to describe what feels wrong about a trace, it can help to check against common LLM failure patterns: hallucinated facts, constraint violations, incorrect tool usage, inappropriate tone, missing information, or fabricated references. Use these as diagnostic lenses, but don't force your observations into predefined categories.
Step 3: Structure failure modes (axial coding)
Open coding produces a valuable but messy collection of observations. The next step is to organize them into a coherent set of failure categories.
Read through all your annotations and look for patterns. Some clusters will be obvious: traces where the agent ignores constraints, traces where it retrieves the wrong documents, traces where it fabricates information. Other distinctions will only become clear after reviewing several examples.
The goal is to define a small set of binary, non-overlapping failure modes. Each failure mode should be:
Specific enough to be consistently recognizable across different traces
Binary - it either occurred or it didn't (avoid rating scales at this stage)
Non-overlapping - a single failure should map to one category, not multiple
For a knowledge base support agent, the structured failure modes might look like:
Failure mode | Definition |
Missing constraint | The agent ignores a user-specified filter or condition (product type, date range, eligibility criteria) |
Wrong knowledge source | Retrieval returns relevant documents, but the agent uses information from the wrong section or document |
Fabricated policy | The agent references a policy, rule, or procedure that doesn't exist in the knowledge base |
Incomplete escalation | The agent should have escalated to a human but either didn't escalate or escalated without providing context |
Persona-tone mismatch | The response tone doesn't match the user's context (e.g., overly casual for a formal enterprise inquiry) |
You can paste your raw annotations in a LLM to help with the clustering and ask it to propose groupings, but don't accept its categories blindly. Review and adjust them based on your understanding of the system and its operational context.
Step 4: Quantify and label
Once the failure taxonomy is defined, go back through all your traces and label each one against the structured categories. For every trace and every failure mode, mark it as present (1) or absent (0).
This produces a table you can use to quantify the prevalence of each failure type. Count how often each failure mode appears across your traces. This quantification is critical for prioritization: it tells you which failures are common enough to warrant automated evaluation and which are rare edge cases you can address later.
Before building evaluators for these failure modes, apply the specification vs. generalization triage from section 4 first by improving prompts, tool descriptions, or system configuration.
Step 5: Iterate
Error analysis isn’t a one-pass process, so you’ll want to do the following after the first round:
Sample new traces (or generate new synthetic queries) to check whether additional failure modes emerge.
Refine your failure taxonomy - some categories may need to be split, merged, or redefined as you see more examples.
Re-label earlier traces if the taxonomy changed significantly.
Two serious rounds of analysis are usually sufficient to reach a stable taxonomy. Beyond that, additional effort produces diminishing returns.
What this produces
At the end of error analysis, you have three artifacts that directly feed into the next steps:
A failure taxonomy: a structured, application-specific vocabulary for describing how your agent fails. This replaces generic categories like "hallucination" or "bad response" with precise, observable failure modes grounded in real system behavior.
A labeled dataset of ~100 traces: each annotated with which failure modes are present. This becomes the foundation of your evaluation dataset (covered in the next section, 6.3).
Prioritized failure modes: a quantified view of which failures are most common, which guides where you invest evaluation effort first.
This process will make sure your evaluation dataset isn't built on guesswork. Instead, it's grounded in systematic observation of how the system actually behaves, what patterns of failure it exhibits, and which issues are frequent enough to warrant ongoing measurement.
The goal isn’t to review every trace indefinitely. Teams typically continue this process until reviewing additional traces stops revealing new categories of failures. Once this point is reached, the failure taxonomy is considered saturated. At that stage, teams shift focus from discovery to improvement by investigating root causes and building regression tests to make sure they don’t return.
6.3: Build an evaluation dataset (representative scenarios)
With a failure taxonomy in hand, the next step is to convert observed failures into repeatable evaluation cases. Each important failure mode should be represented by multiple dataset entries, including both expected-success cases and failure-exposing cases. This will make sure the evaluation suite reflects how the system actually breaks, rather than how the team assumes it might break.
An agent can't be meaningfully evaluated if every interaction depends on unpredictable context. When teams test agents informally, asking different questions each time and providing varying background information, failures are tough to diagnose.
To address this, you need to define representative interaction scenarios. Instead of relying on ad-hoc conversations, they create structured datasets containing example user requests and the expected system behavior. Each entry functions as a repeatable test case: the same input can be run again after any change to determine whether the system improved or regressed.
These datasets don`t necessarily “train” the model. They establish a controlled environment for evaluation. By specifying both the user message and the intended outcome, you can make success criteria explicit. A support agent, for example, should correctly explain policy-related questions and refuse requests for sensitive information.
Once both the agent behavior and its interaction scenarios are defined, the system can be executed in a controlled manner. The next step is to run the agent and record what actually happens during real interactions.
6.4: Execute the agent and record traces
Once behavior and test scenarios are defined, the agent can be executed in a controlled environment. At this point, the goal isn`t any longer to see whether the system can produce a plausible answer. Instead, the objective is to observe how the system behaves when it processes real inputs.
In practice, the agent is executed as an experiment using the evaluation dataset. The platform runs the configured agent against each example user request and records the outcome of every interaction.
For each entry, the platform sends the same user message to the agent, generates a response, and records the full interaction. Each recorded interaction is stored as a trace. Without traces, teams can only evaluate outputs. When an answer is incorrect, the cause remains ambiguous.
The failure might come from reasoning, missing documentation, incorrect retrieval, or even unexpected prompt behavior. Observability solves this ambiguity by turning each interaction into inspectable evidence.
By opening the trace view, it's possible to inspect the full execution timeline. You can see when the model was called, whether retrieval occurred, how long each step took, and which evaluator produced the final result.
After execution, the platform automatically compares the generated outputs with the reference answers using an evaluator. Instead of checking for exact wording, the evaluator assesses whether the response fulfills the agent’s intended role, as we defined earlier in 6.1. A response that uses different phrasing but communicates the same capability may pass, while a fluent but misleading answer fails.
Because every dataset entry is repeatable, the same experiment can be run again after any change, such as a prompt update, a new model, or modified documentation. The platform then produces a pass/fail result for each case. Over time, these results form a measurable quality signal and you can determine whether the system improved, regressed, or behaved inconsistently.
7: What actually needs to be evaluated
After understanding that agents can’t be validated with simple prompt testing, the next question becomes practical:
What should we evaluate?
A common mistake is to evaluate only the final response. Teams check whether the answer “looks right,” and if it does, they assume the system is working. That approach fails because agents aren’t single outputs. Instead, they’re workflows. A response might seem correct on the surface while the system behaves incorrectly underneath.
Production evaluation expands beyond response quality. To operate an agent reliably, teams need to evaluate four distinct layers simultaneously: response quality, safety and governance, behavioral execution, and operational performance.
Each layer answers a different operational question.
7.1 Quality of answers
The most visible aspect of an agent is the response itself, so this serves as a natural starting point. But it’s important to realize quality isn’t a single metric. It’s a combination of correctness, relevance, grounding, and conversational reliability.
The first measure is task success. Did the agent actually accomplish what the user asked? A fluent answer does not necessarily mean the task was completed. A support agent that politely explains a refund policy but gives the wrong eligibility rule has failed, even though the response sounds helpful.
Closely related is answer relevance. The agent may provide technically correct information that does not address the user’s intent. This often happens when agents over-generalize or latch onto keywords rather than understanding the request.
Quality evaluation answers: can users depend on the agent’s answers across real conversations, not just isolated prompts?
7.2 Safety and governance
Quality alone is insufficient for production deployment. An agent that performs tasks correctly but behaves unsafely cannot be trusted in a real workflow.
Safety evaluation focuses on harmful behavior. This includes generating toxic or biased content, responding inappropriately to sensitive requests, or following malicious instructions. Agents must also resist jailbreak attempts, where prompts try to override system rules or policies.
Governance extends beyond content moderation. Production agents interact with real data, which introduces compliance requirements. Systems must properly handle personally identifiable information, respect access controls, and avoid exposing restricted data. For example, an internal enterprise assistant should not reveal information from another department’s records, even if the request sounds reasonable.
Safety evaluation answers a different question than quality:
Even when the agent is capable, is it safe to allow it to operate?
7.3 Agent behavior and system outcomes
One of the most important (and often overlooked) evaluation targets is how the agent reaches its answer.
Agents carry out various tasks like retrieving documents, calling APIs, querying databases, and interacting with other services. A system can produce a correct final answer while executing the wrong workflow, which becomes unstable at scale.
This is why teams evaluate tool usage. Did the agent choose the correct tool? Did it pass valid arguments? Did the call succeed? Repeated failed calls, unnecessary retries, or incorrect parameters often indicate deeper reasoning problems.
In multi-step workflows, teams also evaluate planning behavior. The agent should make forward progress toward the goal rather than looping, stopping prematurely, or performing redundant actions. In multi-agent setups, coordination matters as well: agents should hand off tasks correctly and avoid conflicting decisions.
7.4 Operational performance and business impact
Even a high-quality, safe, well-behaved agent may still fail operationally if it is too slow, too expensive, or economically ineffective.
Latency matters because users expect responsive interactions. An agent that takes thirty seconds to answer a simple question will not be adopted, regardless of correctness.
Cost is equally critical. Agents make runtime decisions: they choose models, retry steps, expand context, and call external services. These behaviors directly affect spending. Without measuring cost per interaction and cost per successful task, teams cannot predict scalability.
Finally, evaluation connects to business outcomes. Organizations measure whether the agent improves operational metrics such as resolution time, task completion rate, deflection from human support, or customer satisfaction. A technically impressive system that does not improve real workflows does not create value.
Layer | Question it answers | Example metrics |
Quality | “Is the answer useful/correct?” | task success, relevance, groundedness |
Safety & governance | “Is it safe/compliant?” | jailbreak rate, PII violations |
Behavior | “Did it act correctly?” | tool success, loops, plan progress |
Ops & business | “Is it viable at scale?” | latency, cost per task, deflection |
8: Types of AI evaluations
After knowing what needs to be measured, the next question becomes operational: how do you actually evaluate an AI agent?
Note that there isn’t a single evaluation method that works for every agent system. Production agents combine language generation, reasoning, tool usage, and decision-making. Because of this, teams rely on multiple complementary evaluation approaches rather than a single metric.
Modern agent evaluation typically uses four categories of methods. Each answers a different question about reliability, and none of them is sufficient on its own.
8.1 Reference-based evaluations
The most familiar evaluation method is the closest to traditional testing. A dataset of labeled examples is created, each with an expected outcome, and the agent’s responses are compared against it.
For example, a support agent may be tested on historical tickets. A sales agent might be evaluated on lead-qualification decisions. A RAG system may be tested on known questions with verified answers. The agent’s outputs are then scored using accuracy-like measurements such as correctness, task success, relevance, or recall.
However, reference-based evaluation has an important limitation: many real-world tasks don’t have a single correct answer. A response may be technically correct but unhelpful. Another may be slightly inaccurate but still useful.
Best for: regressions, deterministic tasks, and correctness checks where a gold answer exists.
Weak for: open-ended helpfulness, tone/brand fit, and cases where multiple answers are acceptable.
8.2 Heuristic and rule-based evaluations
The second category consists of automated checks written as rules.
Instead of judging whether an answer is “good,” these evaluations verify whether the agent followed constraints. For example:
Did the output follow a schema?
Did it include required fields?
Did it leak sensitive information?
Did it call the correct tool?
Did it stay within the allowed response format?
These checks are precise and inexpensive. They run quickly and can evaluate thousands of interactions continuously.
Rule-based evaluations are essential for safety and governance. They can detect toxicity, policy violations, PII exposure, or off-topic outputs before they reach users, acting as guardrails embedded directly in the system.
Their limitation is scope, as rules only catch what they were designed to detect. They can’t reliably measure nuanced qualities such as reasoning quality, helpfulness, or groundedness.
Best for: enforceable constraints (schemas, tool usage rules, PII/policy checks) at high volume and low cost.
Weak for: semantic quality (helpfulness, reasoning, groundedness) and novel failure modes you didn’t explicitly encode.
8.3 LLM-as-judge evaluations
To measure semantic quality at scale, teams increasingly use language models themselves as evaluators.
In this approach, another model reviews the agent’s output and scores it according to a rubric. Instead of exact matching, the evaluator can judge properties such as:
helpfulness
groundedness
safety
policy adherence
reasoning quality
This method sits between automated rules and human review. It captures nuance while remaining scalable.
For instance, rather than checking whether a response exactly matches a reference answer, the evaluator can determine whether the answer actually solves the user’s problem or whether it hallucinated unsupported facts.
LLM-based scoring is widely used because it enables continuous evaluation across large volumes of real interactions. It also allows teams to compare prompt versions, model choices, and workflow changes objectively.
However, it still requires calibration. Evaluator models can be biased, inconsistent, or overly lenient if the scoring criteria are not clearly defined. As a result, teams often combine LLM scoring with other evaluation types rather than relying on it alone.
Best for: semantic scoring at scale (helpfulness, groundedness, policy adherence) using clear rubrics.
Weak for: consistency without calibration because judges can drift, be biased, or over-reward fluent but wrong answers.
8.4 Human evaluation
Despite automation, human review remains essential.
Humans evaluate aspects that automated systems still struggle to judge reliably:
whether an answer is actually helpful
whether tone matches brand expectations
whether reasoning is misleading
whether behavior creates real-world risk
Production systems therefore include annotation workflows. A subset of interactions is reviewed manually, often selected from edge cases, failures, or high-risk scenarios. These reviews validate automated metrics and refine evaluation criteria.
Human-in-the-loop review is also used to audit system performance and verify reliability, especially in sensitive domains.
While expensive, human evaluation serves as the ground truth that keeps automated metrics meaningful.
Best for: ground truth on ambiguous or high-stakes cases (safety, compliance, brand tone) and calibrating automated metrics.
Weak for: continuous coverage, as review is slow and expensive. Must be sampled and targeted to high-risk slices.
Evaluation type | What it checks | Best used for | Weak for | Typical implementation |
Reference-based | Whether the output matches an expected answer or known outcome | regressions, deterministic workflows, structured tasks with clear ground truth | open-ended helpfulness, conversational quality, and multi-valid answers | labeled datasets, gold answers, accuracy/task-success scoring |
Heuristic / rule-based | Whether the agent followed defined constraints | safety enforcement, schemas, tool usage rules, PII/compliance checks at scale | nuanced reasoning quality, helpfulness, and unseen failure modes | tool argument checks, policy filters, guardrails |
LLM-as-judge | Semantic quality of the response and behavior | helpfulness, groundedness, policy adherence, comparing prompts/models at scale | strict reliability without calibration; may reward fluent but wrong answers | rubric-prompted evaluator models scoring responses or traces |
Human evaluation | Real-world usefulness and risk | high-stakes workflows, ambiguous cases, brand tone, calibration of automated metrics | continuous coverage due to cost and speed limitations | annotation queues, sampled audits, expert review workflows |
Together, they form a layered reliability strategy rather than a single metric.
If the task has a clear correct output → reference-based (fast regression signal)
If the system must obey constraints → rules (schemas, PII, tool usage, permissions)
If you need semantic judgment at scale → LLM-as-judge (with calibration)
If stakes are high or ambiguity is real → human review (targeted sampling)
Most production teams run all four as a layered strategy: rules catch hard violations, references catch regressions, judges catch semantic drift, humans keep everything honest.
Next, we’ll look at how these evaluation approaches are applied in practice inside the Orq platform.
9: Measuring agent quality and deciding what to improve
After an agent can be executed and observed, the next challenge is determining whether it is actually reliable. A single successful interaction doesn't fully demonstrate quality. Even a series of successful interactions can be misleading if failures occur in situations that were not tested. That's why it's important to have a consistent way to judge correctness across many scenarios, not individual conversations.
Traditional software systems solve this with automated tests. AI agents complicate this model because correctness isn't always a precise output. Two responses may use different wording yet both be valid, while a fluent response may still be incorrect.
Evaluation provides a structured alternative. Instead of asking whether the agent “seems to work,” you can measure behavior against defined expectations across repeatable scenarios. Each run produces evidence: which cases passed, which failed, and how consistently the system performs.
The following sections describe how automated evaluation, repeatable experiments, and human review work together to determine agent readiness and guide iterative improvement.
9.1: Automated evaluation (LLM judges and rule checks)
In practice, teams rarely start with complex evaluation suites. A common starting point is evaluating tool correctness (when the application uses tools) together with a basic groundedness or hallucination check.
The key recommendation is to start simple. A small number of focused evaluators is usually more useful than building many evaluators prematurely. Once experiments and traces are running end-to-end, teams can analyze outputs and gradually introduce more specialized evaluators for answer quality, reasoning, or domain-specific constraints.
After the agent has been executed and traces have been recorded, the platform can automatically assess whether the system behaved correctly. Instead of relying on manual review, Orq uses automated evaluators to analyze each interaction and determine if the agent fulfilled its intended role.
Two categories of automated checks are commonly used:
Rule-based checks verify structural or deterministic conditions. These include requirements such as refusing restricted requests, using approved tools, or staying within defined operational boundaries. They are precise and reliable but limited to conditions that can be explicitly defined.
LLM judges evaluate behavioral correctness. Instead of comparing wording, the evaluator analyzes whether the generated response satisfies the expected outcome defined in the dataset. The platform compares three elements: the user query, the agent’s generated response, and the reference answer.
The evaluator then determines whether the response is semantically correct.
Unlike traditional testing, the system doesn't exact phrasing. A response may pass even if it uses different wording, as long as it communicates the same capability or instruction. Conversely, a fluent and well-written answer may fail if it provides incorrect information or violates the defined behavior.
The inspection view shows how the evaluator processes an interaction. The platform sends the query, response, and expected output to the judge model, which returns a verdict and explanation. This turns evaluation into an objective decision rather than a subjective review.
Each interaction now produces a measurable result. Instead of reviewing conversations manually, teams receive consistent pass/fail judgments across the entire dataset. This enables reliable comparison when prompts, models, or knowledge sources change.
9.2: Running repeatable evaluation experiments
Evaluating a single response is useful for debugging, but it does not tell a team whether the agent is dependable. An agent may answer one question correctly and another incorrectly, even though both appear similar. For this reason, evaluation needs to be performed across many representative scenarios rather than individual conversations.
To achieve this, Orq executes the agent against the full dataset of test cases in a single run. Each dataset entry is processed using the same configuration: the same prompt, model, knowledge sources, and system behavior. Because the inputs are fixed, the results become directly comparable across time.
This process creates an evaluation experiment.
During an experiment, the platform:
sends each dataset question to the agent
records the generated response
evaluates the response using automated judges
records performance metrics such as latency and cost
The results are aggregated into a structured report where each row represents one interaction scenario.
The table shows the outcome of every test case. For each scenario, you can see:
the generated answer
whether the evaluator passed or failed it
operational metrics such as response time and cost
This is important because reliability problems rarely appear as total failure. Instead, they appear as partial correctness. An agent may perform well on common questions but fail on edge cases such as clarification requests, procedural instructions, or policy boundaries. Running the full dataset exposes these patterns immediately.
Repeatability is the key property. The same experiment can be executed again after any system change. For example:
updating the prompt
switching models
modifying documentation
adjusting retrieval configuration
Because the test cases remain constant, differences in results reflect actual system changes rather than random variation. You'll be able to determine whether performance improved, regressed, or shifted in specific categories of behavior.
9.3: Human review and edge-case validation
Automated evaluation measures whether an agent behaves correctly in known scenarios. However, real users do not always behave like predefined test cases. They ask unexpected questions, interpret responses differently, and interact with the system in ways the dataset cannot fully anticipate.
For this reason, evaluation doesn't end after an experiment run. Teams also monitor production interactions.
In Orq, this is done using annotation queues and automations. Instead of manually reviewing conversations, the platform automatically samples real interactions and routes them to human reviewers. Each sampled conversation appears in a review queue, where reviewers can identify incorrect answers, unclear explanations, or policy violations.
This serves a different purpose from automated evaluation. Evaluators measure known behavior, while human review detects unknown failure modes.
When issues are discovered, you can update prompts, documentation, or test cases and re-run evaluation experiments. In this way, monitoring feeds back into structured evaluation, and evaluation feeds back into system improvements.
10: From evaluation to observability (add more later with platform)
Evaluation helps you answer a specific question: did this version of the agent behave correctly on a defined set of cases? Observability answers a different one: what is the agent actually doing in the real world right now, and why?
Instead of only checking whether the final answer looked correct, observability inspects the trajectory: which tools were called, what context was retrieved, how the model reasoned, and where a decision changed.
Evaluation tells you whether a change improved behavior.
Observability explains why the behavior occurred.
In practice, production agent systems rely on three complementary forms of runtime visibility:
Logs capture inputs and outputs: what the user asked and what the agent answered.
Metrics measure aggregate performance: latency, error rate, cost, and usage patterns.
Traces show the execution path: the sequence of reasoning steps, retrieval operations, and tool calls.
11: Why evaluation becomes an organizational function
Early on, evaluation looks like an engineering activity: write a few test prompts, compare outputs, ship changes. That framing breaks as soon as agents move from a single sandbox workflow to real, cross-team usage. In practice, evaluation becomes organizational because agents create shared operational risk, and shared risk always forces shared ownership.
One reason is scale and autonomy. As agents move from prototypes to real deployment, organizations quickly realize they’re unsure how to evaluate, manage, and govern them responsibly. This is particularly the case as autonomy increases and agents start interacting with tools, systems, and real users.
Another reason is accountability. An agent system touches multiple stakeholders: product defines success criteria, engineering owns workflows and integrations, security cares about access control and misuse, legal/compliance cares about policy and regulatory boundaries, and finance cares about cost predictability.
So the shift is predictable: evaluation starts as a quality technique, but becomes an operating model. You end up with shared definitions (what counts as success), shared tooling (where evals run and where results live), and shared processes (who reviews failures, who approves changes, and what gets blocked).
12: How evaluation connects to cost
Many teams first notice an AI agent problem as a financial problem.
An invoice arrives, usage spikes, or leadership asks why operating the assistant suddenly costs more than expected. The immediate reaction is usually to inspect model usage: token counts, API calls, or the price of the chosen model. But those numbers rarely explain what actually happened. They show how much was spent, not why it was spent or whether the spending produced useful outcomes.
Without evaluation, teams can observe spending but cannot interpret it. They can see token usage rise, but they can’t determine whether the agent became more helpful, less reliable, or simply inefficient. Cost becomes actionable when you can attribute spend to behavior patterns (retries, long traces, tool loops) and tie it to success rate.
Over time, evaluation allows organizations to connect three signals that were previously isolated: what the agent did, what it cost, and whether it worked. Once those signals are linked, cost becomes explainable. Engineers can identify inefficient workflows, product teams can understand tradeoffs between quality and latency, and leadership can forecast operating expenses with confidence.
13: From debugging to operating: the real role of evaluation
At the start of this guide, we described a common experience: an AI agent works in demos but becomes unpredictable once real users arrive. Responses seem correct most of the time, yet occasional failures appear without a clear cause. Teams investigate incidents one by one, adjust prompts, and hope behavior improves.
Evaluation changes that.
When interactions are measured consistently, failures stop looking random. Patterns emerge. Agents often struggle in specific situations: ambiguous requests, long contexts, or multi-step workflows. What appears to be hallucination frequently turns out to be a system issue: missing context, poor retrieval, incorrect tool usage, or an unsafe execution path.
Evaluation also shows that agents rarely “break.” They drift. Small changes to prompts, models, tools, or knowledge bases gradually affect outcomes while the system still appears healthy. Without measurement, teams notice only after trust declines.
Instead of reacting to incidents, teams begin to:
Turn failures into regression cases
Compare changes before release
Detect behavior shifts early
Expand usage safely
In practice, evaluation doesn’t primarily measure model quality. It makes the system understandable and controllable. Combined with observability and controlled rollouts, it turns an agent from a black box into a managed production service.
The original problem, an agent that shows value but can’t be trusted, isn’t solved by a better prompt or a larger model. Instead, it’s solved by measurement. Evaluation provides the bridge between experimentation and reliable operation, letting teams treat AI agents not as demos, but as systems they can safely depend on.
Source for section 2
https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
https://www.domo.com/blog/ai-evaluations-101-testing-llms-agents-and-everything-in-between
https://www.ibm.com/think/topics/ai-agent-evaluation
https://www.getmaxim.ai/articles/ai-agent-evaluation-metrics-strategies-and-best-practices/
https://deepeval.com/guides/guides-ai-agent-evaluation
https://aisera.com/blog/ai-agent-evaluation
https://arxiv.org/html/2507.21504v1
https://huggingface.co/papers/2503.16416
http://scis.scichina.com/en/2025/121101.pdf
https://openreview.net/forum?id=zAdUB0aCTQ
https://arxiv.org/html/2512.08273v1
Section 3 Source
https://coralogix.com/ai-blog/why-traditional-testing-fails-for-ai-agents-and-what-actually-works/
https://techstrong.ai/aiops/rethinking-ai-testing-why-traditional-qa-methods-fall-short/
https://www.disseqt.ai/articles/why-traditional-testing-fails-in-the-age-of-ai
https://blog.sigplan.org/2025/03/20/testing-ai-software-isnt-like-testing-plain-old-software/
https://arxiv.org/html/2503.03158v1
https://arxiv.org/abs/2307.10586
https://www.arxiv.org/abs/2503.03158
https://arxiv.org/abs/2503.16416
Section 4 source
https://arxiv.org/abs/2401.05856
https://arxiv.org/html/2508.07935v1
https://arxiv.org/html/2510.06265v2
https://dl.acm.org/doi/10.1145/3703155
https://www.nature.com/articles/s41598-025-15416-8
https://www.evidentlyai.com/blog/llm-hallucination-examples
https://arxiv.org/abs/2510.13975
https://arxiv.org/abs/2401.05856
https://chrislema.com/ai-context-failures-nine-ways-your-ai-agent-breaks/
https://manveerc.substack.com/p/ai-agent-hallucinations-prevention
https://arxiv.org/html/2508.07935v1
https://galileo.ai/blog/agent-failure-modes-guide
https://arxiv.org/abs/2401.05856
https://arxiv.org/html/2508.07935v1
Section 5
https://arize.com/blog/evaluating-and-improving-ai-agents-at-scale-with-microsoft-foundry/
https://www.fiddler.ai/blog/end-to-end-agentic-observability-lifecycle
https://www.adopt.ai/blog/observability-for-ai-agents
https://microsoft.github.io/ai-agents-for-beginners/10-ai-agents-production/
https://www.sciencedirect.com/science/article/abs/pii/S1566253525009273
https://openreview.net/forum?id=sooLoD9VSf
https://arxiv.org/html/2510.03463v2
https://onereach.ai/blog/llmops-for-ai-agents-in-production/
https://www.braintrust.dev/articles/best-llmops-platforms-2025
https://www.fiddler.ai/blog/end-to-end-agentic-observability-lifecycle
https://www.youtube.com/watch?v=5jMEf2-CPDY&t=4s
Section 7
https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
https://www.kore.ai/blog/ai-agents-evaluation
https://arxiv.org/html/2507.21504v1
https://samiranama.com/posts/Evaluating-LLM-based-Agents-Metrics,-Benchmarks,-and-Best-Practices/
https://www.confident-ai.com/blog/llm-agent-evaluation-complete-guide
https://www.geeksforgeeks.org/nlp/evaluation-metrics-for-retrieval-augmented-generation-rag-systems/
https://www.aviso.com/blog/how-to-evaluate-ai-agents-latency-cost-safety-roi
https://www.deepchecks.com/llm-agent-evaluation/
Section 8
https://www.domo.com/de/blog/ai-evaluations-101-testing-llms-agents-and-everything-in-between
https://www.confident-ai.com/blog/llm-agent-evaluation-complete-guide
https://arxiv.org/html/2507.21504v1
https://www.deepchecks.com/llm-agent-evaluation/
https://arxiv.org/html/2408.09235v2
https://mirascope.com/blog/llm-as-judge
https://agenta.ai/blog/llm-as-a-judge-guide-to-llm-evaluation-best-practices
https://agenta.ai/blog/llm-as-a-judge-guide-to-llm-evaluation-best-practices
Section 10
https://langfuse.com/blog/2024-07-ai-agent-observability-with-langfuse
https://agentsarcade.com/blog/observability-for-ai-agents-logs-traces-metrics
https://www.fiddler.ai/blog/end-to-end-agentic-observability-lifecycle
https://www.datarobot.com/blog/agentic-ai-observability/
https://opentelemetry.io/blog/2025/ai-agent-observability/
Section 11
https://aigrowthlogic.com/ai-data-evaluation-pipelines/
https://www.aigl.blog/ai-model-risk-management-framework/
https://www.obsidiansecurity.com/blog/what-is-ai-model-governance
https://www.weforum.org/publications/ai-agents-in-action-foundations-for-evaluation-and-governance/
https://www.responsible.ai/news/navigating-organizational-ai-governance/ https://www.diligent.com/resources/blog/ai-governance
https://www.oecd.org/en/publications/2025/06/governing-with-artificial-intelligence_398fa287.html
Section 12
https://developer.ibm.com/tutorials/awb-comparing-llms-cost-optimization-response-quality/
https://arxiv.org/html/2507.03834v1
https://www.usagepricing.com/blog/choosing-ai-models-cost-quality/ https://www.prompts.ai/blog/task-specific-model-routing-cost-quality-insights
https://www.finops.org/wg/finops-for-ai-overview/
https://www.cloudzero.com/blog/finops-for-ai/
https://konghq.com/solutions/ai-cost-governance-finops
https://www.codeant.ai/blogs/llm-production-costs
https://debmalyabiswas.substack.com/p/agentic-ai-finops-cost-optimization
1: The production reality
You’ve seen how teams are using AI agents to answer questions, retrieve documents, and execute workflows in controlled testing environments. In the development phase, the system seems reliable most of the time. Prompts produce reasonable outputs, evaluation examples look correct, and early demos perform well.
But the real challenge starts after you’ve deployed your agent.
When real users interact with the agent, behavior becomes inconsistent. A response that was correct during testing becomes incomplete at runtime. A small prompt modification improves one scenario but degrades another. Retrieval changes alter answers in unexpected ways. Some interactions work perfectly, while others fail without any obvious cause.
Teams are running into the same issue: the agent works well enough to show value, but not reliably enough to depend on. Engineers can’t easily determine why failures occur, whether a change improved performance, or when the system is safe to expand to more users.
What’s missing isn’t a better prompt or a larger model. Rather, teams need a more reliable way to measure agent behavior in production, which is where evaluation comes into play.
This guide will provide a deep dive into how evaluation works in the context of real agent systems. We’ll look at what evaluation can and can’t measure, the tradeoffs between different evaluation approaches, and when each method should be used.
In this guide, you’ll learn:
How to build an eval suite (scenario sets + regressions)
What to measure (quality/safety/behavior/ops)
Which eval methods to use and when (reference, heuristics, judge, human)
How to debug failures using traces + eval results
How to operationalize evals (gates + production sampling)
2: What “evaluation” actually means
After a team decides to put an AI agent into a real workflow, one of the first practical questions that appears is simple: how do we know if it works?
Initially, most teams answer this by manually testing a few prompts. Someone opens the interface, tries multiple example requests, reads the responses, and then decides whether the answers look reasonable. If one response looks wrong, the prompt is adjusted and the test is repeated.
When teams hear the term “AI evaluation,” they usually think of checking the correctness of a model’s response. That approach works for simple generation tasks like summarizing a document or translating text. In those cases, the model produces a single output and the only question is whether the output is good.
However, an agent is fundamentally different, since it isn’t a single model response. Rather, it’s a decision-making system. To produce one answer, the agent may interpret user intent, retrieve documents, decide which tools to call, retry certain outputs, or ask clarifying questions. The response that a user sees is only the final step of a much longer process.
Hence, teams need to see the bigger picture beyond answer quality and look at system behavior as well. Evaluation measures system behavior and not just output quality.
For the purposes of this guide, evaluation can be understood simply:
Evaluation is the repeatable process of measuring whether an AI agent reliably completes the intended task under realistic conditions and within acceptable quality, safety, latency, and cost boundaries.
3: Why traditional software testing doesn’t work for AI
Traditional software testing assumes you’re validating a deterministic system. Given the same input, the system should follow the same execution path and produce the same output. That way, you can write stable assertions and confidently ship changes.
AI agents break those assumptions in three ways.
First, agent behavior is probabilistic and path-dependent. When the user asks “the same” question twice, the agent may route to a different model, retrieve different context, call different tools, or take an extra reasoning step.
Second, AI agents face the oracle problem. In many real tasks, there isn’t one “correct” output you can assert against. A support agent response can be helpful, acceptable, risky, or subtly wrong. It depends on tone, factuality, policy constraints, and the customer’s context.
Third, AI systems degrade in ways that look nothing like traditional regressions. In classic software, a bug usually shows up as a deterministic failure. In agents, failures often show up as quality drift: slight changes to prompts, retrieval corpora, tools, model versions, or even user behavior can change outcomes in ways that are hard to spot until you have enough real usage.
If you apply traditional QA literally, you tend to end up in one of two failure modes:
You over-constrain tests to make them deterministic (tiny prompts, simplified flows), which produces “green” results that don’t reflect production complexity.
Or you write brittle assertions for open-ended outputs (“must match this exact answer”), which creates noisy failures and makes iteration slower, not safer.
So the right framing is: agents still need testing, but the testing target changes.
Instead of only testing outputs, you test:
Behavior across runs (variance, stability, failure modes)
Workflow steps (retrieval quality, tool-call correctness, routing decisions)
Quality attributes (groundedness, policy compliance, task completion)
Performance under realistic distributions (edge cases, long-tail inputs, adversarial prompts)
That’s why modern “AI testing” starts to look less like classic QA and more like evaluation + observability: you define evaluation criteria, run them continuously, and use runtime traces to explain why something passed or failed.
4: The real source of AI failures
When an AI agent fails in production, the first thought that teams get is to blame the model: “The LLM hallucinated.” In reality, most failures are system failures. The model is only one component in a chain of decisions that includes retrieval, tool calls, routing, safety policies, and state management. If any link in that chain is weak, the agent can produce a confident, incorrect, or unsafe outcome. More often than not, it won’t throw an obvious error.
A useful way to think about agent failures is: the agent didn’t “get it wrong”. The system let the agent take the wrong path. That path might be driven by missing context, a bad intermediate step, or a workflow that never fully implemented a correct stopping condition.
Before diagnosing the failure, identify its origin
When an AI agent fails in production, teams naturally want to classify the failure: was it a grounding problem? A retrieval issue? A tool call gone wrong? A planning breakdown? These categories, which we cover in the sections below, are useful for understanding what went wrong.
But before diving into the specific failure type, there's a more fundamental question that determines how you should respond:
Was this a specification failure or a generalization failure?
A specification failure means the system failed because you didn't clearly tell it what to do. The instructions were ambiguous, incomplete, or missing entirely. The prompt didn't explain expected behavior. The tool descriptions were vague. Required constraints were never communicated. In these cases, the model isn't failing. Your specification is.
A generalization failure means the system failed despite having clear, unambiguous instructions. The model received explicit guidance but couldn't reliably follow it across the full range of real-world inputs. It may work for common cases but break on edge cases, unusual phrasings, or unfamiliar contexts.
This distinction matters operationally because the correct response is fundamentally different:
Specification failures should be fixed immediately. Update the prompt, clarify tool descriptions, add missing constraints, provide better examples. These fixes are fast, cheap, and often resolve the issue entirely. You don't need to build an evaluator for a problem you can eliminate with a prompt edit.
Generalization failures are what evaluation is actually designed to measure. These are the persistent issues that remain even after instructions are clear. They require automated evaluators, regression test cases, and ongoing monitoring because the model's inconsistent behavior is the problem, not the specification.
Every failure category can be either type
Not all AI agent failures come from the same root cause. Some failures occur because the system was never fully specified. One reason is that the agent wasn't given clear instructions, constraints, or behavior definitions. Other failures occur even when the specification is correct, because the model cannot consistently generalize across real-world inputs.
Understanding this difference is important because each type requires a different fix. Specification gaps are addressed by improving system design, while generalization failures require evaluation and monitoring to detect patterns of unreliable behavior.
The table below shows how each failure category can arise from either type.
Failure category | Specification gap (prompt definition / config is missing or unclear) | Generalization limitation (spec is clear, agent still fails in patterns) | What to do next |
Grounding failures | Agent answers from prior world knowledge because the prompt never explicitly requires grounding in retrieved sources. | Prompt clearly says “only answer using provided documents,” but the agent still fabricates answers for certain question types. | Spec gap: improve prompts, add explicit grounding + refusal rules. Generalization: add evaluators to measure hallucination rate by scenario type. If nothing else works, consider choosing a more capable model |
Retrieval & context pipeline failures | Retrieval returns irrelevant results because query formulation / retrieval strategy was never defined (or poorly defined). | Retrieval works for most queries but fails consistently on ambiguous or multi-part questions. | Spec gap: improve query construction + retrieval config. Generalization: evaluate failure clusters (ambiguity, multi-intent, long queries) and expand the eval set. Consider review chunking mechanism. If nothing else works, consider choosing a more capable model. |
Tool & action failures | Agent calls the wrong tool because tool descriptions overlap, or parameter formats are not documented clearly. | Tool specs are explicit, but the agent still passes incorrect parameters for certain input patterns (e.g., defaults to today instead of parsing dates). | Spec gap: rewrite tool descriptions + tighten schemas/contracts. Generalization: add automated argument/format checks + targeted judge/hard-rule evaluators. If nothing else works, consider choosing a more capable model. |
Planning & state failures | Agent loops because no stopping condition, max steps, or termination criteria were defined. | Constraints exist, but the agent still prematurely stops on complex tasks that require more steps/tool calls than typical. | Spec gap: add stop conditions, step limits, completion criteria. Generalization: evaluate long-horizon tasks separately; add progression/termination evaluators and expand scenarios. If nothing else works, consider choosing a more capable model. |
A practical diagnostic
When investigating a failure, ask this question first:
"If I made the instructions perfectly clear and explicit, would this failure still occur?"
If the answer is no, then the failure would disappear with better instructions and it's a specification issue. Fix the prompt, tool definitions, or system configuration. Don't invest in building an evaluator for it.
If the answer is yes, then the failure persists even with clear instructions and it's a generalization issue. This is where evaluation becomes essential. Build a test case for it, add it to your scenario suite, and track it over time.
This triage step saves significant effort. Teams that skip it often build evaluators for problems that could have been resolved in minutes with a prompt update. Worse, they end up measuring the wrong thing: their evaluation scores reflect the quality of their specification rather than the model's actual capability.
With this framing in place, let's look at the specific categories of agent failures and the patterns they typically follow. As you read through each category, consider whether your own observed failures are specification issues you can fix now, or generalization issues that need ongoing evaluation.
Failure category 1: grounding failures (the agent is reasoning without the right facts)
These are the failures people usually label as “hallucinations.” However, the root cause is often missing or incorrect grounding rather than pure model invention.
Think of an example where a support agent cites a policy that doesn’t exist and the visible problem is fabrication. The underlying problem is that the response wasn’t properly grounded in verified sources (or retrieval didn’t return the right policy).
Common grounding failure patterns
The agent answers from its prior “world knowledge” instead of checking sources.
Retrieval returns irrelevant context (or none), but the agent continues anyway.
Context is present, but the agent doesn’t use it (or misinterprets it).
The agent generates plausible references, links, citations, or “policies” that aren’t real.
That’s why “add RAG” isn’t a complete fix like you would think: RAG changes the architecture, but it doesn’t guarantee correct behavior. It’s important to note you still need evaluation to verify retrieval actually improves outcomes and doesn’t introduce new failure modes.
Failure category 2: retrieval and context pipeline failures (RAG-specific)
If your agent uses retrieval, the system adds new places where things can go wrong. Many of them won’t look like traditional software bugs, either.
In practice, many retrieval failures aren’t caused by the embedding model itself but by poorly structured source data. When documentation is inconsistently formatted or policies are fragmented across multiple files, semantic retrieval struggles to surface the correct information even when the underlying content exists.
Typical RAG failure points you’ll see in real usage include:
Knowledge base drift: the source of truth changes, but your indexed content doesn’t.
Chunking and indexing mistakes: the right information exists, but retrieval can’t surface it.
Retrieval mismatch: the query formulation or embedding similarity pulls the wrong docs.
Context overload: the agent retrieves too much, diluting the signal with noise.
What makes these failures difficult is that the agent can still produce fluent answers. Consequently, the system “looks healthy” unless you evaluate for groundedness, relevance, and evidence use.
Failure category 3: tool and action failures (the agent can’t reliably execute the workflow)
Agents don’t just generate text. Rather, they also call tools, APIs, databases, CRMs, ticketing systems, internal services. This introduces failure modes that don’t exist in pure chat.
Examples include:
The tool returns an error or partial response and the agent doesn’t recover correctly.
Tool output format changes and the agent mis-parses the result.
The agent calls the right tool but with the wrong parameters (silent failure).
The agent repeats tool calls (retries / loops) and burns cost without progress.
In other words: the agent’s reliability becomes a property of the whole runtime environment, not the model alone.
Failure category 4: planning and state failures (the agent loses the plot)
Multi-step workflows often fail because the agent can’t maintain coherent state over time:
It forgets constraints from earlier steps.
It doesn’t preserve user intent across turns.
It prematurely stops (incomplete task) or never stops (looping).
It confuses intermediate steps with final answers.
Under real traffic, these often appear as “it worked yesterday, but not today” because small changes in prompts, retrieval context, or tool latency can shift the agent’s decisions.
Understanding failure modes tells us what to fix. The next question is operational: where does evaluation fit in the lifecycle of a production agent?
5: The AI agent lifecycle (add platform screenshots)
When Orq talks about “agents in production,” it rarely means a single prompt behind a chat UI. It means a runtime system that plans, retrieves context, calls tools, routes across models, retries, escalates, and produces outcomes that other systems (and humans) act on. That’s why operating an agent looks less like shipping a feature and more like running a production service.
A practical way to frame the lifecycle is a continuous loop:
Define → Build → Evaluate → Deploy → Observe → Improve
Phase 1-2: Define and build the system (what “good” looks like, and how the agent behaves)
Before you can evaluate anything, you need a measurable target. Some outcome-based and constrained targets include:
Task success: did the agent complete the job end-to-end?
Policy compliance: did it follow safety and data-handling rules?
Acceptable behavior: did it take an allowed path (tools, retries, escalations)?
Operational budgets: did it stay within latency and cost limits?
From there, you build the workflow that produces those outcomes:
orchestration and step logic (plans, sub-tasks, tool calls)
context strategy (what to retrieve, when, and how much)
tool contracts and failure handling
routing and escalation policies
Because agent execution is probabilistic, small changes (prompt wording, retrieval quality, tool latency, model versions) can shift both reliability and cost in ways that aren’t obvious at build time.
Phase 3: Evaluate before release (offline + scenario coverage)
This is the first “gate” where teams typically get stuck, because traditional unit tests don’t map cleanly to agent behavior.
Pre-release evaluation tends to include:
Scenario suites: representative tasks the agent must handle (happy paths + edge cases)
Regression checks: previous failures turned into test cases so they don’t come back
Policy/safety checks: refusals, data-handling rules, tool restrictions, compliance needs
Tool correctness: did it call the right tools, with the right parameters, in the right order?
Phase 4-6: Deploy, observe, and evaluate in production (operate under real traffic)
Once the agent is live, variance becomes a risk, so teams ship with controls and continuous measurement:
Deployment controls
staged rollouts (small cohorts → broader exposure)
runtime limits (max steps/tokens/timeouts/tool rate limits)
kill switches and pause controls
routing policies (fallbacks, escalation rules)
Observability (what actually happened)
logs (inputs/outputs)
metrics (latency, error rate, cost)
traces (retrieval context, tool calls, decision path)
Production evaluation (continuous, not periodic)
sampled evaluations on real traffic
triggered evals on risky patterns (tool failures, escalations, loops)
human review queues for ambiguous/high-stakes cases
outcome-linked evals tied to business signals (resolution, deflection, CSAT)
This is where teams stop asking “does it work?” and start answering “how does it behave, and when does it fail?”
Phase 7: Improve safely (iterate without breaking trust)
Once you can observe behavior and measure outcomes, improvement becomes engineering, not guesswork:
Fix the failure mode (prompt, retrieval, routing, tool contract, guardrail)
Re-run evaluations (offline suites first)
Deploy behind a controlled rollout
Monitor deltas in cost, behavior, and outcomes
Promote, roll back, or retire
This is also where teams need discipline: changes that “feel small” can change unit economics and reliability.
6: Operational walkthrough: preparing an agent for evaluation
Understanding evaluation conceptually is straightforward, but implementing it in practice is a lot more difficult.
Most teams begin building AI agents the same way they experiment with LLMs: a prompt in a notebook, a chat interface, or a small internal tool. The system appears to work, feedback is gathered informally, and improvements are made by adjusting prompts, swapping models, or adding more context.
This approach works for prototyping, but it breaks down as soon as the agent becomes operational. Once multiple users interact with the system, behavior varies across requests, failures become harder to reproduce, and teams can no longer determine whether a change actually improved performance.
Evaluation requires a different approach from experimentation. An agent can`t be reliably evaluated if its behavior is informal, its inputs are inconsistent, and its executions are not recorded. Before metrics, benchmarks, or judges can be applied, the agent needs to be structured as a repeatable system.
This section walks through the operational steps teams take to move from a prototype agent to one that can be measured, compared, and safely improved.
6.1: Define the agent behavior
Before an agent can be evaluated, its expected behavior must be explicitly defined.
Most teams try to evaluate AI systems while the agent itself is still informal. Examples include a prompt in a notebook, a few instructions in a chat interface, or a workflow that multiple developers modify over time. In this state, behavior changes constantly.
When performance improves or degrades, it's unclear whether the change came from the model, the prompt, the retrieval configuration, or the surrounding logic. As a result, any evaluation performed at this stage produces inconsistent and misleading results.
To make evaluation meaningful, we need the agent to be a stable system. Rather than treating it as a conversational interface, you`ll want to define the agent as a configuration: a versioned specification describing what the system is responsible for, what information it may rely on, and how it should behave when it can`t complete a task.
This definition establishes several critical elements:
Scope: what types of questions the agent is intended to handle
Grounding requirements: which knowledge sources the agent should use
Response expectations: tone, structure, and level of detail
Failure behavior: how the agent should respond when information is missing or uncertain
By defining these constraints, you create a behavioral contract. The agent isn`t just an open-ended assistant anymore, but a bounded operational system. This distinction is essential because evaluation doesn`t measure whether a response “sounds good”; it measures whether the system behaves according to its intended role.
6.2: Discover failure modes through systematic error analysis
After defining the agent's expected behavior, the natural instinct is to immediately start writing test cases. Teams sit down and brainstorm scenarios they think the agent might struggle with: edge cases they can imagine, common questions they expect, a few adversarial prompts they've seen in demos.
The problem with this approach is that it's based on assumptions about how the system fails instead of observations of how it actually fails. A brainstormed test suite tends to cover the obvious cases while missing the failure patterns that only emerge under real usage.
Before building an evaluation dataset, teams need a structured way to observe the agent's real behavior and discover where it breaks down. This process is called error analysis. It produces a grounded understanding of the system's actual failure modes, which then directly informs what goes into the evaluation dataset.
Step 1: Collect an initial set of traces
Error analysis starts with traces, not test cases.
A trace is the full record of a single agent execution: the user input, every intermediate step (retrieval, tool calls, model responses), and the final output. Traces are essential because failures often originate in intermediate steps that aren't visible in the final response.
The goal is to collect roughly 100 diverse traces. This number provides enough variety to surface a broad range of failure patterns without requiring an overwhelming review effort.
There's two ways to collect these traces:
From production logs (preferred when available): If the agent is already handling real traffic, sample traces directly. Avoid sampling only the most common queries. Focus on using stratified sampling or clustering on query embeddings to ensure coverage across different types of user behavior. Keep in mind the goal is diversity, not representativeness of traffic volume.
From synthetic queries (when production data is sparse): If the agent hasn't been deployed yet or traffic is limited, generate synthetic queries to run through the system. However, simply prompting an LLM to "generate user queries" produces generic, repetitive results that don't reflect real usage patterns.
A more effective approach is to generate synthetic queries in two structured steps:
First, define key dimensions along which user queries vary. These dimensions should reflect where the agent is most likely to fail. For a support agent, useful dimensions might include:
Feature area: billing, account access, product configuration, returns
User persona: new customer, enterprise admin, frustrated repeat caller
Scenario complexity: straightforward question, ambiguous request, out-of-scope query, multi-step task
Second, create structured combinations (tuples) of these dimensions, then generate a natural-language query for each tuple. Start by writing 15–20 tuples manually, then use an LLM to scale up. You'll also want to separate the tuple generation from the query generation. This two-step approach produces more diverse and realistic queries than generating both at once.
For each generated query, run it through the agent end-to-end and record the full trace. After filtering out duplicates and unrealistic queries, you should have roughly 100 traces ready for analysis.
Step 2: Read traces and annotate failures (open coding)
With traces collected, the next step is to read them carefully and take notes.
For each trace, focus on the first significant failure, which is the earliest point in the execution where something went demonstrably wrong. This is important because agent failures often cascade: a mistake in an early step (misinterpreting user intent, retrieving the wrong documents) causes a chain of downstream problems.
Record each trace with its annotation in a simple table: trace identifier, a summary of the trace, and the freeform observation. At this stage, don't try to categorize or organize. Just capture what you see.
In early stages, this annotation process is often done outside the platform using a spreadsheet or simple annotation tool. The goal is simply to capture observations consistently. As the system grows and more people become involved, teams often move this workflow into dedicated annotation queues inside the platform.
A few examples of what these annotations might look like for a knowledge base support agent:
Trace | Observation |
User asks about refund eligibility for a specific product | Agent cites the general refund policy but ignores the product-specific exception documented in the knowledge base. Retrieval returned the right document, but the agent used the wrong section. |
User asks for the CEO's personal phone number | Agent correctly refuses but gives a vague explanation. Should reference the data privacy policy explicitly. |
User asks a billing question in French | Agent switches to French mid-response but uses the English-language knowledge base, producing a mix of translated and untranslated policy terms. |
Continue this process until you've annotated at least 20 traces with clear failures and new traces are no longer revealing fundamentally different problems. This point is known as theoretical saturation, and typically arrives after reviewing 50–100 traces, depending on the system's complexity.
If you find yourself stuck and unsure how to describe what feels wrong about a trace, it can help to check against common LLM failure patterns: hallucinated facts, constraint violations, incorrect tool usage, inappropriate tone, missing information, or fabricated references. Use these as diagnostic lenses, but don't force your observations into predefined categories.
Step 3: Structure failure modes (axial coding)
Open coding produces a valuable but messy collection of observations. The next step is to organize them into a coherent set of failure categories.
Read through all your annotations and look for patterns. Some clusters will be obvious: traces where the agent ignores constraints, traces where it retrieves the wrong documents, traces where it fabricates information. Other distinctions will only become clear after reviewing several examples.
The goal is to define a small set of binary, non-overlapping failure modes. Each failure mode should be:
Specific enough to be consistently recognizable across different traces
Binary - it either occurred or it didn't (avoid rating scales at this stage)
Non-overlapping - a single failure should map to one category, not multiple
For a knowledge base support agent, the structured failure modes might look like:
Failure mode | Definition |
Missing constraint | The agent ignores a user-specified filter or condition (product type, date range, eligibility criteria) |
Wrong knowledge source | Retrieval returns relevant documents, but the agent uses information from the wrong section or document |
Fabricated policy | The agent references a policy, rule, or procedure that doesn't exist in the knowledge base |
Incomplete escalation | The agent should have escalated to a human but either didn't escalate or escalated without providing context |
Persona-tone mismatch | The response tone doesn't match the user's context (e.g., overly casual for a formal enterprise inquiry) |
You can paste your raw annotations in a LLM to help with the clustering and ask it to propose groupings, but don't accept its categories blindly. Review and adjust them based on your understanding of the system and its operational context.
Step 4: Quantify and label
Once the failure taxonomy is defined, go back through all your traces and label each one against the structured categories. For every trace and every failure mode, mark it as present (1) or absent (0).
This produces a table you can use to quantify the prevalence of each failure type. Count how often each failure mode appears across your traces. This quantification is critical for prioritization: it tells you which failures are common enough to warrant automated evaluation and which are rare edge cases you can address later.
Before building evaluators for these failure modes, apply the specification vs. generalization triage from section 4 first by improving prompts, tool descriptions, or system configuration.
Step 5: Iterate
Error analysis isn’t a one-pass process, so you’ll want to do the following after the first round:
Sample new traces (or generate new synthetic queries) to check whether additional failure modes emerge.
Refine your failure taxonomy - some categories may need to be split, merged, or redefined as you see more examples.
Re-label earlier traces if the taxonomy changed significantly.
Two serious rounds of analysis are usually sufficient to reach a stable taxonomy. Beyond that, additional effort produces diminishing returns.
What this produces
At the end of error analysis, you have three artifacts that directly feed into the next steps:
A failure taxonomy: a structured, application-specific vocabulary for describing how your agent fails. This replaces generic categories like "hallucination" or "bad response" with precise, observable failure modes grounded in real system behavior.
A labeled dataset of ~100 traces: each annotated with which failure modes are present. This becomes the foundation of your evaluation dataset (covered in the next section, 6.3).
Prioritized failure modes: a quantified view of which failures are most common, which guides where you invest evaluation effort first.
This process will make sure your evaluation dataset isn't built on guesswork. Instead, it's grounded in systematic observation of how the system actually behaves, what patterns of failure it exhibits, and which issues are frequent enough to warrant ongoing measurement.
The goal isn’t to review every trace indefinitely. Teams typically continue this process until reviewing additional traces stops revealing new categories of failures. Once this point is reached, the failure taxonomy is considered saturated. At that stage, teams shift focus from discovery to improvement by investigating root causes and building regression tests to make sure they don’t return.
6.3: Build an evaluation dataset (representative scenarios)
With a failure taxonomy in hand, the next step is to convert observed failures into repeatable evaluation cases. Each important failure mode should be represented by multiple dataset entries, including both expected-success cases and failure-exposing cases. This will make sure the evaluation suite reflects how the system actually breaks, rather than how the team assumes it might break.
An agent can't be meaningfully evaluated if every interaction depends on unpredictable context. When teams test agents informally, asking different questions each time and providing varying background information, failures are tough to diagnose.
To address this, you need to define representative interaction scenarios. Instead of relying on ad-hoc conversations, they create structured datasets containing example user requests and the expected system behavior. Each entry functions as a repeatable test case: the same input can be run again after any change to determine whether the system improved or regressed.
These datasets don`t necessarily “train” the model. They establish a controlled environment for evaluation. By specifying both the user message and the intended outcome, you can make success criteria explicit. A support agent, for example, should correctly explain policy-related questions and refuse requests for sensitive information.
Once both the agent behavior and its interaction scenarios are defined, the system can be executed in a controlled manner. The next step is to run the agent and record what actually happens during real interactions.
6.4: Execute the agent and record traces
Once behavior and test scenarios are defined, the agent can be executed in a controlled environment. At this point, the goal isn`t any longer to see whether the system can produce a plausible answer. Instead, the objective is to observe how the system behaves when it processes real inputs.
In practice, the agent is executed as an experiment using the evaluation dataset. The platform runs the configured agent against each example user request and records the outcome of every interaction.
For each entry, the platform sends the same user message to the agent, generates a response, and records the full interaction. Each recorded interaction is stored as a trace. Without traces, teams can only evaluate outputs. When an answer is incorrect, the cause remains ambiguous.
The failure might come from reasoning, missing documentation, incorrect retrieval, or even unexpected prompt behavior. Observability solves this ambiguity by turning each interaction into inspectable evidence.
By opening the trace view, it's possible to inspect the full execution timeline. You can see when the model was called, whether retrieval occurred, how long each step took, and which evaluator produced the final result.
After execution, the platform automatically compares the generated outputs with the reference answers using an evaluator. Instead of checking for exact wording, the evaluator assesses whether the response fulfills the agent’s intended role, as we defined earlier in 6.1. A response that uses different phrasing but communicates the same capability may pass, while a fluent but misleading answer fails.
Because every dataset entry is repeatable, the same experiment can be run again after any change, such as a prompt update, a new model, or modified documentation. The platform then produces a pass/fail result for each case. Over time, these results form a measurable quality signal and you can determine whether the system improved, regressed, or behaved inconsistently.
7: What actually needs to be evaluated
After understanding that agents can’t be validated with simple prompt testing, the next question becomes practical:
What should we evaluate?
A common mistake is to evaluate only the final response. Teams check whether the answer “looks right,” and if it does, they assume the system is working. That approach fails because agents aren’t single outputs. Instead, they’re workflows. A response might seem correct on the surface while the system behaves incorrectly underneath.
Production evaluation expands beyond response quality. To operate an agent reliably, teams need to evaluate four distinct layers simultaneously: response quality, safety and governance, behavioral execution, and operational performance.
Each layer answers a different operational question.
7.1 Quality of answers
The most visible aspect of an agent is the response itself, so this serves as a natural starting point. But it’s important to realize quality isn’t a single metric. It’s a combination of correctness, relevance, grounding, and conversational reliability.
The first measure is task success. Did the agent actually accomplish what the user asked? A fluent answer does not necessarily mean the task was completed. A support agent that politely explains a refund policy but gives the wrong eligibility rule has failed, even though the response sounds helpful.
Closely related is answer relevance. The agent may provide technically correct information that does not address the user’s intent. This often happens when agents over-generalize or latch onto keywords rather than understanding the request.
Quality evaluation answers: can users depend on the agent’s answers across real conversations, not just isolated prompts?
7.2 Safety and governance
Quality alone is insufficient for production deployment. An agent that performs tasks correctly but behaves unsafely cannot be trusted in a real workflow.
Safety evaluation focuses on harmful behavior. This includes generating toxic or biased content, responding inappropriately to sensitive requests, or following malicious instructions. Agents must also resist jailbreak attempts, where prompts try to override system rules or policies.
Governance extends beyond content moderation. Production agents interact with real data, which introduces compliance requirements. Systems must properly handle personally identifiable information, respect access controls, and avoid exposing restricted data. For example, an internal enterprise assistant should not reveal information from another department’s records, even if the request sounds reasonable.
Safety evaluation answers a different question than quality:
Even when the agent is capable, is it safe to allow it to operate?
7.3 Agent behavior and system outcomes
One of the most important (and often overlooked) evaluation targets is how the agent reaches its answer.
Agents carry out various tasks like retrieving documents, calling APIs, querying databases, and interacting with other services. A system can produce a correct final answer while executing the wrong workflow, which becomes unstable at scale.
This is why teams evaluate tool usage. Did the agent choose the correct tool? Did it pass valid arguments? Did the call succeed? Repeated failed calls, unnecessary retries, or incorrect parameters often indicate deeper reasoning problems.
In multi-step workflows, teams also evaluate planning behavior. The agent should make forward progress toward the goal rather than looping, stopping prematurely, or performing redundant actions. In multi-agent setups, coordination matters as well: agents should hand off tasks correctly and avoid conflicting decisions.
7.4 Operational performance and business impact
Even a high-quality, safe, well-behaved agent may still fail operationally if it is too slow, too expensive, or economically ineffective.
Latency matters because users expect responsive interactions. An agent that takes thirty seconds to answer a simple question will not be adopted, regardless of correctness.
Cost is equally critical. Agents make runtime decisions: they choose models, retry steps, expand context, and call external services. These behaviors directly affect spending. Without measuring cost per interaction and cost per successful task, teams cannot predict scalability.
Finally, evaluation connects to business outcomes. Organizations measure whether the agent improves operational metrics such as resolution time, task completion rate, deflection from human support, or customer satisfaction. A technically impressive system that does not improve real workflows does not create value.
Layer | Question it answers | Example metrics |
Quality | “Is the answer useful/correct?” | task success, relevance, groundedness |
Safety & governance | “Is it safe/compliant?” | jailbreak rate, PII violations |
Behavior | “Did it act correctly?” | tool success, loops, plan progress |
Ops & business | “Is it viable at scale?” | latency, cost per task, deflection |
8: Types of AI evaluations
After knowing what needs to be measured, the next question becomes operational: how do you actually evaluate an AI agent?
Note that there isn’t a single evaluation method that works for every agent system. Production agents combine language generation, reasoning, tool usage, and decision-making. Because of this, teams rely on multiple complementary evaluation approaches rather than a single metric.
Modern agent evaluation typically uses four categories of methods. Each answers a different question about reliability, and none of them is sufficient on its own.
8.1 Reference-based evaluations
The most familiar evaluation method is the closest to traditional testing. A dataset of labeled examples is created, each with an expected outcome, and the agent’s responses are compared against it.
For example, a support agent may be tested on historical tickets. A sales agent might be evaluated on lead-qualification decisions. A RAG system may be tested on known questions with verified answers. The agent’s outputs are then scored using accuracy-like measurements such as correctness, task success, relevance, or recall.
However, reference-based evaluation has an important limitation: many real-world tasks don’t have a single correct answer. A response may be technically correct but unhelpful. Another may be slightly inaccurate but still useful.
Best for: regressions, deterministic tasks, and correctness checks where a gold answer exists.
Weak for: open-ended helpfulness, tone/brand fit, and cases where multiple answers are acceptable.
8.2 Heuristic and rule-based evaluations
The second category consists of automated checks written as rules.
Instead of judging whether an answer is “good,” these evaluations verify whether the agent followed constraints. For example:
Did the output follow a schema?
Did it include required fields?
Did it leak sensitive information?
Did it call the correct tool?
Did it stay within the allowed response format?
These checks are precise and inexpensive. They run quickly and can evaluate thousands of interactions continuously.
Rule-based evaluations are essential for safety and governance. They can detect toxicity, policy violations, PII exposure, or off-topic outputs before they reach users, acting as guardrails embedded directly in the system.
Their limitation is scope, as rules only catch what they were designed to detect. They can’t reliably measure nuanced qualities such as reasoning quality, helpfulness, or groundedness.
Best for: enforceable constraints (schemas, tool usage rules, PII/policy checks) at high volume and low cost.
Weak for: semantic quality (helpfulness, reasoning, groundedness) and novel failure modes you didn’t explicitly encode.
8.3 LLM-as-judge evaluations
To measure semantic quality at scale, teams increasingly use language models themselves as evaluators.
In this approach, another model reviews the agent’s output and scores it according to a rubric. Instead of exact matching, the evaluator can judge properties such as:
helpfulness
groundedness
safety
policy adherence
reasoning quality
This method sits between automated rules and human review. It captures nuance while remaining scalable.
For instance, rather than checking whether a response exactly matches a reference answer, the evaluator can determine whether the answer actually solves the user’s problem or whether it hallucinated unsupported facts.
LLM-based scoring is widely used because it enables continuous evaluation across large volumes of real interactions. It also allows teams to compare prompt versions, model choices, and workflow changes objectively.
However, it still requires calibration. Evaluator models can be biased, inconsistent, or overly lenient if the scoring criteria are not clearly defined. As a result, teams often combine LLM scoring with other evaluation types rather than relying on it alone.
Best for: semantic scoring at scale (helpfulness, groundedness, policy adherence) using clear rubrics.
Weak for: consistency without calibration because judges can drift, be biased, or over-reward fluent but wrong answers.
8.4 Human evaluation
Despite automation, human review remains essential.
Humans evaluate aspects that automated systems still struggle to judge reliably:
whether an answer is actually helpful
whether tone matches brand expectations
whether reasoning is misleading
whether behavior creates real-world risk
Production systems therefore include annotation workflows. A subset of interactions is reviewed manually, often selected from edge cases, failures, or high-risk scenarios. These reviews validate automated metrics and refine evaluation criteria.
Human-in-the-loop review is also used to audit system performance and verify reliability, especially in sensitive domains.
While expensive, human evaluation serves as the ground truth that keeps automated metrics meaningful.
Best for: ground truth on ambiguous or high-stakes cases (safety, compliance, brand tone) and calibrating automated metrics.
Weak for: continuous coverage, as review is slow and expensive. Must be sampled and targeted to high-risk slices.
Evaluation type | What it checks | Best used for | Weak for | Typical implementation |
Reference-based | Whether the output matches an expected answer or known outcome | regressions, deterministic workflows, structured tasks with clear ground truth | open-ended helpfulness, conversational quality, and multi-valid answers | labeled datasets, gold answers, accuracy/task-success scoring |
Heuristic / rule-based | Whether the agent followed defined constraints | safety enforcement, schemas, tool usage rules, PII/compliance checks at scale | nuanced reasoning quality, helpfulness, and unseen failure modes | tool argument checks, policy filters, guardrails |
LLM-as-judge | Semantic quality of the response and behavior | helpfulness, groundedness, policy adherence, comparing prompts/models at scale | strict reliability without calibration; may reward fluent but wrong answers | rubric-prompted evaluator models scoring responses or traces |
Human evaluation | Real-world usefulness and risk | high-stakes workflows, ambiguous cases, brand tone, calibration of automated metrics | continuous coverage due to cost and speed limitations | annotation queues, sampled audits, expert review workflows |
Together, they form a layered reliability strategy rather than a single metric.
If the task has a clear correct output → reference-based (fast regression signal)
If the system must obey constraints → rules (schemas, PII, tool usage, permissions)
If you need semantic judgment at scale → LLM-as-judge (with calibration)
If stakes are high or ambiguity is real → human review (targeted sampling)
Most production teams run all four as a layered strategy: rules catch hard violations, references catch regressions, judges catch semantic drift, humans keep everything honest.
Next, we’ll look at how these evaluation approaches are applied in practice inside the Orq platform.
9: Measuring agent quality and deciding what to improve
After an agent can be executed and observed, the next challenge is determining whether it is actually reliable. A single successful interaction doesn't fully demonstrate quality. Even a series of successful interactions can be misleading if failures occur in situations that were not tested. That's why it's important to have a consistent way to judge correctness across many scenarios, not individual conversations.
Traditional software systems solve this with automated tests. AI agents complicate this model because correctness isn't always a precise output. Two responses may use different wording yet both be valid, while a fluent response may still be incorrect.
Evaluation provides a structured alternative. Instead of asking whether the agent “seems to work,” you can measure behavior against defined expectations across repeatable scenarios. Each run produces evidence: which cases passed, which failed, and how consistently the system performs.
The following sections describe how automated evaluation, repeatable experiments, and human review work together to determine agent readiness and guide iterative improvement.
9.1: Automated evaluation (LLM judges and rule checks)
In practice, teams rarely start with complex evaluation suites. A common starting point is evaluating tool correctness (when the application uses tools) together with a basic groundedness or hallucination check.
The key recommendation is to start simple. A small number of focused evaluators is usually more useful than building many evaluators prematurely. Once experiments and traces are running end-to-end, teams can analyze outputs and gradually introduce more specialized evaluators for answer quality, reasoning, or domain-specific constraints.
After the agent has been executed and traces have been recorded, the platform can automatically assess whether the system behaved correctly. Instead of relying on manual review, Orq uses automated evaluators to analyze each interaction and determine if the agent fulfilled its intended role.
Two categories of automated checks are commonly used:
Rule-based checks verify structural or deterministic conditions. These include requirements such as refusing restricted requests, using approved tools, or staying within defined operational boundaries. They are precise and reliable but limited to conditions that can be explicitly defined.
LLM judges evaluate behavioral correctness. Instead of comparing wording, the evaluator analyzes whether the generated response satisfies the expected outcome defined in the dataset. The platform compares three elements: the user query, the agent’s generated response, and the reference answer.
The evaluator then determines whether the response is semantically correct.
Unlike traditional testing, the system doesn't exact phrasing. A response may pass even if it uses different wording, as long as it communicates the same capability or instruction. Conversely, a fluent and well-written answer may fail if it provides incorrect information or violates the defined behavior.
The inspection view shows how the evaluator processes an interaction. The platform sends the query, response, and expected output to the judge model, which returns a verdict and explanation. This turns evaluation into an objective decision rather than a subjective review.
Each interaction now produces a measurable result. Instead of reviewing conversations manually, teams receive consistent pass/fail judgments across the entire dataset. This enables reliable comparison when prompts, models, or knowledge sources change.
9.2: Running repeatable evaluation experiments
Evaluating a single response is useful for debugging, but it does not tell a team whether the agent is dependable. An agent may answer one question correctly and another incorrectly, even though both appear similar. For this reason, evaluation needs to be performed across many representative scenarios rather than individual conversations.
To achieve this, Orq executes the agent against the full dataset of test cases in a single run. Each dataset entry is processed using the same configuration: the same prompt, model, knowledge sources, and system behavior. Because the inputs are fixed, the results become directly comparable across time.
This process creates an evaluation experiment.
During an experiment, the platform:
sends each dataset question to the agent
records the generated response
evaluates the response using automated judges
records performance metrics such as latency and cost
The results are aggregated into a structured report where each row represents one interaction scenario.
The table shows the outcome of every test case. For each scenario, you can see:
the generated answer
whether the evaluator passed or failed it
operational metrics such as response time and cost
This is important because reliability problems rarely appear as total failure. Instead, they appear as partial correctness. An agent may perform well on common questions but fail on edge cases such as clarification requests, procedural instructions, or policy boundaries. Running the full dataset exposes these patterns immediately.
Repeatability is the key property. The same experiment can be executed again after any system change. For example:
updating the prompt
switching models
modifying documentation
adjusting retrieval configuration
Because the test cases remain constant, differences in results reflect actual system changes rather than random variation. You'll be able to determine whether performance improved, regressed, or shifted in specific categories of behavior.
9.3: Human review and edge-case validation
Automated evaluation measures whether an agent behaves correctly in known scenarios. However, real users do not always behave like predefined test cases. They ask unexpected questions, interpret responses differently, and interact with the system in ways the dataset cannot fully anticipate.
For this reason, evaluation doesn't end after an experiment run. Teams also monitor production interactions.
In Orq, this is done using annotation queues and automations. Instead of manually reviewing conversations, the platform automatically samples real interactions and routes them to human reviewers. Each sampled conversation appears in a review queue, where reviewers can identify incorrect answers, unclear explanations, or policy violations.
This serves a different purpose from automated evaluation. Evaluators measure known behavior, while human review detects unknown failure modes.
When issues are discovered, you can update prompts, documentation, or test cases and re-run evaluation experiments. In this way, monitoring feeds back into structured evaluation, and evaluation feeds back into system improvements.
10: From evaluation to observability (add more later with platform)
Evaluation helps you answer a specific question: did this version of the agent behave correctly on a defined set of cases? Observability answers a different one: what is the agent actually doing in the real world right now, and why?
Instead of only checking whether the final answer looked correct, observability inspects the trajectory: which tools were called, what context was retrieved, how the model reasoned, and where a decision changed.
Evaluation tells you whether a change improved behavior.
Observability explains why the behavior occurred.
In practice, production agent systems rely on three complementary forms of runtime visibility:
Logs capture inputs and outputs: what the user asked and what the agent answered.
Metrics measure aggregate performance: latency, error rate, cost, and usage patterns.
Traces show the execution path: the sequence of reasoning steps, retrieval operations, and tool calls.
11: Why evaluation becomes an organizational function
Early on, evaluation looks like an engineering activity: write a few test prompts, compare outputs, ship changes. That framing breaks as soon as agents move from a single sandbox workflow to real, cross-team usage. In practice, evaluation becomes organizational because agents create shared operational risk, and shared risk always forces shared ownership.
One reason is scale and autonomy. As agents move from prototypes to real deployment, organizations quickly realize they’re unsure how to evaluate, manage, and govern them responsibly. This is particularly the case as autonomy increases and agents start interacting with tools, systems, and real users.
Another reason is accountability. An agent system touches multiple stakeholders: product defines success criteria, engineering owns workflows and integrations, security cares about access control and misuse, legal/compliance cares about policy and regulatory boundaries, and finance cares about cost predictability.
So the shift is predictable: evaluation starts as a quality technique, but becomes an operating model. You end up with shared definitions (what counts as success), shared tooling (where evals run and where results live), and shared processes (who reviews failures, who approves changes, and what gets blocked).
12: How evaluation connects to cost
Many teams first notice an AI agent problem as a financial problem.
An invoice arrives, usage spikes, or leadership asks why operating the assistant suddenly costs more than expected. The immediate reaction is usually to inspect model usage: token counts, API calls, or the price of the chosen model. But those numbers rarely explain what actually happened. They show how much was spent, not why it was spent or whether the spending produced useful outcomes.
Without evaluation, teams can observe spending but cannot interpret it. They can see token usage rise, but they can’t determine whether the agent became more helpful, less reliable, or simply inefficient. Cost becomes actionable when you can attribute spend to behavior patterns (retries, long traces, tool loops) and tie it to success rate.
Over time, evaluation allows organizations to connect three signals that were previously isolated: what the agent did, what it cost, and whether it worked. Once those signals are linked, cost becomes explainable. Engineers can identify inefficient workflows, product teams can understand tradeoffs between quality and latency, and leadership can forecast operating expenses with confidence.
13: From debugging to operating: the real role of evaluation
At the start of this guide, we described a common experience: an AI agent works in demos but becomes unpredictable once real users arrive. Responses seem correct most of the time, yet occasional failures appear without a clear cause. Teams investigate incidents one by one, adjust prompts, and hope behavior improves.
Evaluation changes that.
When interactions are measured consistently, failures stop looking random. Patterns emerge. Agents often struggle in specific situations: ambiguous requests, long contexts, or multi-step workflows. What appears to be hallucination frequently turns out to be a system issue: missing context, poor retrieval, incorrect tool usage, or an unsafe execution path.
Evaluation also shows that agents rarely “break.” They drift. Small changes to prompts, models, tools, or knowledge bases gradually affect outcomes while the system still appears healthy. Without measurement, teams notice only after trust declines.
Instead of reacting to incidents, teams begin to:
Turn failures into regression cases
Compare changes before release
Detect behavior shifts early
Expand usage safely
In practice, evaluation doesn’t primarily measure model quality. It makes the system understandable and controllable. Combined with observability and controlled rollouts, it turns an agent from a black box into a managed production service.
The original problem, an agent that shows value but can’t be trusted, isn’t solved by a better prompt or a larger model. Instead, it’s solved by measurement. Evaluation provides the bridge between experimentation and reliable operation, letting teams treat AI agents not as demos, but as systems they can safely depend on.
Source for section 2
https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
https://www.domo.com/blog/ai-evaluations-101-testing-llms-agents-and-everything-in-between
https://www.ibm.com/think/topics/ai-agent-evaluation
https://www.getmaxim.ai/articles/ai-agent-evaluation-metrics-strategies-and-best-practices/
https://deepeval.com/guides/guides-ai-agent-evaluation
https://aisera.com/blog/ai-agent-evaluation
https://arxiv.org/html/2507.21504v1
https://huggingface.co/papers/2503.16416
http://scis.scichina.com/en/2025/121101.pdf
https://openreview.net/forum?id=zAdUB0aCTQ
https://arxiv.org/html/2512.08273v1
Section 3 Source
https://coralogix.com/ai-blog/why-traditional-testing-fails-for-ai-agents-and-what-actually-works/
https://techstrong.ai/aiops/rethinking-ai-testing-why-traditional-qa-methods-fall-short/
https://www.disseqt.ai/articles/why-traditional-testing-fails-in-the-age-of-ai
https://blog.sigplan.org/2025/03/20/testing-ai-software-isnt-like-testing-plain-old-software/
https://arxiv.org/html/2503.03158v1
https://arxiv.org/abs/2307.10586
https://www.arxiv.org/abs/2503.03158
https://arxiv.org/abs/2503.16416
Section 4 source
https://arxiv.org/abs/2401.05856
https://arxiv.org/html/2508.07935v1
https://arxiv.org/html/2510.06265v2
https://dl.acm.org/doi/10.1145/3703155
https://www.nature.com/articles/s41598-025-15416-8
https://www.evidentlyai.com/blog/llm-hallucination-examples
https://arxiv.org/abs/2510.13975
https://arxiv.org/abs/2401.05856
https://chrislema.com/ai-context-failures-nine-ways-your-ai-agent-breaks/
https://manveerc.substack.com/p/ai-agent-hallucinations-prevention
https://arxiv.org/html/2508.07935v1
https://galileo.ai/blog/agent-failure-modes-guide
https://arxiv.org/abs/2401.05856
https://arxiv.org/html/2508.07935v1
Section 5
https://arize.com/blog/evaluating-and-improving-ai-agents-at-scale-with-microsoft-foundry/
https://www.fiddler.ai/blog/end-to-end-agentic-observability-lifecycle
https://www.adopt.ai/blog/observability-for-ai-agents
https://microsoft.github.io/ai-agents-for-beginners/10-ai-agents-production/
https://www.sciencedirect.com/science/article/abs/pii/S1566253525009273
https://openreview.net/forum?id=sooLoD9VSf
https://arxiv.org/html/2510.03463v2
https://onereach.ai/blog/llmops-for-ai-agents-in-production/
https://www.braintrust.dev/articles/best-llmops-platforms-2025
https://www.fiddler.ai/blog/end-to-end-agentic-observability-lifecycle
https://www.youtube.com/watch?v=5jMEf2-CPDY&t=4s
Section 7
https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
https://www.kore.ai/blog/ai-agents-evaluation
https://arxiv.org/html/2507.21504v1
https://samiranama.com/posts/Evaluating-LLM-based-Agents-Metrics,-Benchmarks,-and-Best-Practices/
https://www.confident-ai.com/blog/llm-agent-evaluation-complete-guide
https://www.geeksforgeeks.org/nlp/evaluation-metrics-for-retrieval-augmented-generation-rag-systems/
https://www.aviso.com/blog/how-to-evaluate-ai-agents-latency-cost-safety-roi
https://www.deepchecks.com/llm-agent-evaluation/
Section 8
https://www.domo.com/de/blog/ai-evaluations-101-testing-llms-agents-and-everything-in-between
https://www.confident-ai.com/blog/llm-agent-evaluation-complete-guide
https://arxiv.org/html/2507.21504v1
https://www.deepchecks.com/llm-agent-evaluation/
https://arxiv.org/html/2408.09235v2
https://mirascope.com/blog/llm-as-judge
https://agenta.ai/blog/llm-as-a-judge-guide-to-llm-evaluation-best-practices
https://agenta.ai/blog/llm-as-a-judge-guide-to-llm-evaluation-best-practices
Section 10
https://langfuse.com/blog/2024-07-ai-agent-observability-with-langfuse
https://agentsarcade.com/blog/observability-for-ai-agents-logs-traces-metrics
https://www.fiddler.ai/blog/end-to-end-agentic-observability-lifecycle
https://www.datarobot.com/blog/agentic-ai-observability/
https://opentelemetry.io/blog/2025/ai-agent-observability/
Section 11
https://aigrowthlogic.com/ai-data-evaluation-pipelines/
https://www.aigl.blog/ai-model-risk-management-framework/
https://www.obsidiansecurity.com/blog/what-is-ai-model-governance
https://www.weforum.org/publications/ai-agents-in-action-foundations-for-evaluation-and-governance/
https://www.responsible.ai/news/navigating-organizational-ai-governance/ https://www.diligent.com/resources/blog/ai-governance
https://www.oecd.org/en/publications/2025/06/governing-with-artificial-intelligence_398fa287.html
Section 12
https://developer.ibm.com/tutorials/awb-comparing-llms-cost-optimization-response-quality/
https://arxiv.org/html/2507.03834v1
https://www.usagepricing.com/blog/choosing-ai-models-cost-quality/ https://www.prompts.ai/blog/task-specific-model-routing-cost-quality-insights
https://www.finops.org/wg/finops-for-ai-overview/
https://www.cloudzero.com/blog/finops-for-ai/
https://konghq.com/solutions/ai-cost-governance-finops
https://www.codeant.ai/blogs/llm-production-costs
https://debmalyabiswas.substack.com/p/agentic-ai-finops-cost-optimization
1: The production reality
You’ve seen how teams are using AI agents to answer questions, retrieve documents, and execute workflows in controlled testing environments. In the development phase, the system seems reliable most of the time. Prompts produce reasonable outputs, evaluation examples look correct, and early demos perform well.
But the real challenge starts after you’ve deployed your agent.
When real users interact with the agent, behavior becomes inconsistent. A response that was correct during testing becomes incomplete at runtime. A small prompt modification improves one scenario but degrades another. Retrieval changes alter answers in unexpected ways. Some interactions work perfectly, while others fail without any obvious cause.
Teams are running into the same issue: the agent works well enough to show value, but not reliably enough to depend on. Engineers can’t easily determine why failures occur, whether a change improved performance, or when the system is safe to expand to more users.
What’s missing isn’t a better prompt or a larger model. Rather, teams need a more reliable way to measure agent behavior in production, which is where evaluation comes into play.
This guide will provide a deep dive into how evaluation works in the context of real agent systems. We’ll look at what evaluation can and can’t measure, the tradeoffs between different evaluation approaches, and when each method should be used.
In this guide, you’ll learn:
How to build an eval suite (scenario sets + regressions)
What to measure (quality/safety/behavior/ops)
Which eval methods to use and when (reference, heuristics, judge, human)
How to debug failures using traces + eval results
How to operationalize evals (gates + production sampling)
2: What “evaluation” actually means
After a team decides to put an AI agent into a real workflow, one of the first practical questions that appears is simple: how do we know if it works?
Initially, most teams answer this by manually testing a few prompts. Someone opens the interface, tries multiple example requests, reads the responses, and then decides whether the answers look reasonable. If one response looks wrong, the prompt is adjusted and the test is repeated.
When teams hear the term “AI evaluation,” they usually think of checking the correctness of a model’s response. That approach works for simple generation tasks like summarizing a document or translating text. In those cases, the model produces a single output and the only question is whether the output is good.
However, an agent is fundamentally different, since it isn’t a single model response. Rather, it’s a decision-making system. To produce one answer, the agent may interpret user intent, retrieve documents, decide which tools to call, retry certain outputs, or ask clarifying questions. The response that a user sees is only the final step of a much longer process.
Hence, teams need to see the bigger picture beyond answer quality and look at system behavior as well. Evaluation measures system behavior and not just output quality.
For the purposes of this guide, evaluation can be understood simply:
Evaluation is the repeatable process of measuring whether an AI agent reliably completes the intended task under realistic conditions and within acceptable quality, safety, latency, and cost boundaries.
3: Why traditional software testing doesn’t work for AI
Traditional software testing assumes you’re validating a deterministic system. Given the same input, the system should follow the same execution path and produce the same output. That way, you can write stable assertions and confidently ship changes.
AI agents break those assumptions in three ways.
First, agent behavior is probabilistic and path-dependent. When the user asks “the same” question twice, the agent may route to a different model, retrieve different context, call different tools, or take an extra reasoning step.
Second, AI agents face the oracle problem. In many real tasks, there isn’t one “correct” output you can assert against. A support agent response can be helpful, acceptable, risky, or subtly wrong. It depends on tone, factuality, policy constraints, and the customer’s context.
Third, AI systems degrade in ways that look nothing like traditional regressions. In classic software, a bug usually shows up as a deterministic failure. In agents, failures often show up as quality drift: slight changes to prompts, retrieval corpora, tools, model versions, or even user behavior can change outcomes in ways that are hard to spot until you have enough real usage.
If you apply traditional QA literally, you tend to end up in one of two failure modes:
You over-constrain tests to make them deterministic (tiny prompts, simplified flows), which produces “green” results that don’t reflect production complexity.
Or you write brittle assertions for open-ended outputs (“must match this exact answer”), which creates noisy failures and makes iteration slower, not safer.
So the right framing is: agents still need testing, but the testing target changes.
Instead of only testing outputs, you test:
Behavior across runs (variance, stability, failure modes)
Workflow steps (retrieval quality, tool-call correctness, routing decisions)
Quality attributes (groundedness, policy compliance, task completion)
Performance under realistic distributions (edge cases, long-tail inputs, adversarial prompts)
That’s why modern “AI testing” starts to look less like classic QA and more like evaluation + observability: you define evaluation criteria, run them continuously, and use runtime traces to explain why something passed or failed.
4: The real source of AI failures
When an AI agent fails in production, the first thought that teams get is to blame the model: “The LLM hallucinated.” In reality, most failures are system failures. The model is only one component in a chain of decisions that includes retrieval, tool calls, routing, safety policies, and state management. If any link in that chain is weak, the agent can produce a confident, incorrect, or unsafe outcome. More often than not, it won’t throw an obvious error.
A useful way to think about agent failures is: the agent didn’t “get it wrong”. The system let the agent take the wrong path. That path might be driven by missing context, a bad intermediate step, or a workflow that never fully implemented a correct stopping condition.
Before diagnosing the failure, identify its origin
When an AI agent fails in production, teams naturally want to classify the failure: was it a grounding problem? A retrieval issue? A tool call gone wrong? A planning breakdown? These categories, which we cover in the sections below, are useful for understanding what went wrong.
But before diving into the specific failure type, there's a more fundamental question that determines how you should respond:
Was this a specification failure or a generalization failure?
A specification failure means the system failed because you didn't clearly tell it what to do. The instructions were ambiguous, incomplete, or missing entirely. The prompt didn't explain expected behavior. The tool descriptions were vague. Required constraints were never communicated. In these cases, the model isn't failing. Your specification is.
A generalization failure means the system failed despite having clear, unambiguous instructions. The model received explicit guidance but couldn't reliably follow it across the full range of real-world inputs. It may work for common cases but break on edge cases, unusual phrasings, or unfamiliar contexts.
This distinction matters operationally because the correct response is fundamentally different:
Specification failures should be fixed immediately. Update the prompt, clarify tool descriptions, add missing constraints, provide better examples. These fixes are fast, cheap, and often resolve the issue entirely. You don't need to build an evaluator for a problem you can eliminate with a prompt edit.
Generalization failures are what evaluation is actually designed to measure. These are the persistent issues that remain even after instructions are clear. They require automated evaluators, regression test cases, and ongoing monitoring because the model's inconsistent behavior is the problem, not the specification.
Every failure category can be either type
Not all AI agent failures come from the same root cause. Some failures occur because the system was never fully specified. One reason is that the agent wasn't given clear instructions, constraints, or behavior definitions. Other failures occur even when the specification is correct, because the model cannot consistently generalize across real-world inputs.
Understanding this difference is important because each type requires a different fix. Specification gaps are addressed by improving system design, while generalization failures require evaluation and monitoring to detect patterns of unreliable behavior.
The table below shows how each failure category can arise from either type.
Failure category | Specification gap (prompt definition / config is missing or unclear) | Generalization limitation (spec is clear, agent still fails in patterns) | What to do next |
Grounding failures | Agent answers from prior world knowledge because the prompt never explicitly requires grounding in retrieved sources. | Prompt clearly says “only answer using provided documents,” but the agent still fabricates answers for certain question types. | Spec gap: improve prompts, add explicit grounding + refusal rules. Generalization: add evaluators to measure hallucination rate by scenario type. If nothing else works, consider choosing a more capable model |
Retrieval & context pipeline failures | Retrieval returns irrelevant results because query formulation / retrieval strategy was never defined (or poorly defined). | Retrieval works for most queries but fails consistently on ambiguous or multi-part questions. | Spec gap: improve query construction + retrieval config. Generalization: evaluate failure clusters (ambiguity, multi-intent, long queries) and expand the eval set. Consider review chunking mechanism. If nothing else works, consider choosing a more capable model. |
Tool & action failures | Agent calls the wrong tool because tool descriptions overlap, or parameter formats are not documented clearly. | Tool specs are explicit, but the agent still passes incorrect parameters for certain input patterns (e.g., defaults to today instead of parsing dates). | Spec gap: rewrite tool descriptions + tighten schemas/contracts. Generalization: add automated argument/format checks + targeted judge/hard-rule evaluators. If nothing else works, consider choosing a more capable model. |
Planning & state failures | Agent loops because no stopping condition, max steps, or termination criteria were defined. | Constraints exist, but the agent still prematurely stops on complex tasks that require more steps/tool calls than typical. | Spec gap: add stop conditions, step limits, completion criteria. Generalization: evaluate long-horizon tasks separately; add progression/termination evaluators and expand scenarios. If nothing else works, consider choosing a more capable model. |
A practical diagnostic
When investigating a failure, ask this question first:
"If I made the instructions perfectly clear and explicit, would this failure still occur?"
If the answer is no, then the failure would disappear with better instructions and it's a specification issue. Fix the prompt, tool definitions, or system configuration. Don't invest in building an evaluator for it.
If the answer is yes, then the failure persists even with clear instructions and it's a generalization issue. This is where evaluation becomes essential. Build a test case for it, add it to your scenario suite, and track it over time.
This triage step saves significant effort. Teams that skip it often build evaluators for problems that could have been resolved in minutes with a prompt update. Worse, they end up measuring the wrong thing: their evaluation scores reflect the quality of their specification rather than the model's actual capability.
With this framing in place, let's look at the specific categories of agent failures and the patterns they typically follow. As you read through each category, consider whether your own observed failures are specification issues you can fix now, or generalization issues that need ongoing evaluation.
Failure category 1: grounding failures (the agent is reasoning without the right facts)
These are the failures people usually label as “hallucinations.” However, the root cause is often missing or incorrect grounding rather than pure model invention.
Think of an example where a support agent cites a policy that doesn’t exist and the visible problem is fabrication. The underlying problem is that the response wasn’t properly grounded in verified sources (or retrieval didn’t return the right policy).
Common grounding failure patterns
The agent answers from its prior “world knowledge” instead of checking sources.
Retrieval returns irrelevant context (or none), but the agent continues anyway.
Context is present, but the agent doesn’t use it (or misinterprets it).
The agent generates plausible references, links, citations, or “policies” that aren’t real.
That’s why “add RAG” isn’t a complete fix like you would think: RAG changes the architecture, but it doesn’t guarantee correct behavior. It’s important to note you still need evaluation to verify retrieval actually improves outcomes and doesn’t introduce new failure modes.
Failure category 2: retrieval and context pipeline failures (RAG-specific)
If your agent uses retrieval, the system adds new places where things can go wrong. Many of them won’t look like traditional software bugs, either.
In practice, many retrieval failures aren’t caused by the embedding model itself but by poorly structured source data. When documentation is inconsistently formatted or policies are fragmented across multiple files, semantic retrieval struggles to surface the correct information even when the underlying content exists.
Typical RAG failure points you’ll see in real usage include:
Knowledge base drift: the source of truth changes, but your indexed content doesn’t.
Chunking and indexing mistakes: the right information exists, but retrieval can’t surface it.
Retrieval mismatch: the query formulation or embedding similarity pulls the wrong docs.
Context overload: the agent retrieves too much, diluting the signal with noise.
What makes these failures difficult is that the agent can still produce fluent answers. Consequently, the system “looks healthy” unless you evaluate for groundedness, relevance, and evidence use.
Failure category 3: tool and action failures (the agent can’t reliably execute the workflow)
Agents don’t just generate text. Rather, they also call tools, APIs, databases, CRMs, ticketing systems, internal services. This introduces failure modes that don’t exist in pure chat.
Examples include:
The tool returns an error or partial response and the agent doesn’t recover correctly.
Tool output format changes and the agent mis-parses the result.
The agent calls the right tool but with the wrong parameters (silent failure).
The agent repeats tool calls (retries / loops) and burns cost without progress.
In other words: the agent’s reliability becomes a property of the whole runtime environment, not the model alone.
Failure category 4: planning and state failures (the agent loses the plot)
Multi-step workflows often fail because the agent can’t maintain coherent state over time:
It forgets constraints from earlier steps.
It doesn’t preserve user intent across turns.
It prematurely stops (incomplete task) or never stops (looping).
It confuses intermediate steps with final answers.
Under real traffic, these often appear as “it worked yesterday, but not today” because small changes in prompts, retrieval context, or tool latency can shift the agent’s decisions.
Understanding failure modes tells us what to fix. The next question is operational: where does evaluation fit in the lifecycle of a production agent?
5: The AI agent lifecycle (add platform screenshots)
When Orq talks about “agents in production,” it rarely means a single prompt behind a chat UI. It means a runtime system that plans, retrieves context, calls tools, routes across models, retries, escalates, and produces outcomes that other systems (and humans) act on. That’s why operating an agent looks less like shipping a feature and more like running a production service.
A practical way to frame the lifecycle is a continuous loop:
Define → Build → Evaluate → Deploy → Observe → Improve
Phase 1-2: Define and build the system (what “good” looks like, and how the agent behaves)
Before you can evaluate anything, you need a measurable target. Some outcome-based and constrained targets include:
Task success: did the agent complete the job end-to-end?
Policy compliance: did it follow safety and data-handling rules?
Acceptable behavior: did it take an allowed path (tools, retries, escalations)?
Operational budgets: did it stay within latency and cost limits?
From there, you build the workflow that produces those outcomes:
orchestration and step logic (plans, sub-tasks, tool calls)
context strategy (what to retrieve, when, and how much)
tool contracts and failure handling
routing and escalation policies
Because agent execution is probabilistic, small changes (prompt wording, retrieval quality, tool latency, model versions) can shift both reliability and cost in ways that aren’t obvious at build time.
Phase 3: Evaluate before release (offline + scenario coverage)
This is the first “gate” where teams typically get stuck, because traditional unit tests don’t map cleanly to agent behavior.
Pre-release evaluation tends to include:
Scenario suites: representative tasks the agent must handle (happy paths + edge cases)
Regression checks: previous failures turned into test cases so they don’t come back
Policy/safety checks: refusals, data-handling rules, tool restrictions, compliance needs
Tool correctness: did it call the right tools, with the right parameters, in the right order?
Phase 4-6: Deploy, observe, and evaluate in production (operate under real traffic)
Once the agent is live, variance becomes a risk, so teams ship with controls and continuous measurement:
Deployment controls
staged rollouts (small cohorts → broader exposure)
runtime limits (max steps/tokens/timeouts/tool rate limits)
kill switches and pause controls
routing policies (fallbacks, escalation rules)
Observability (what actually happened)
logs (inputs/outputs)
metrics (latency, error rate, cost)
traces (retrieval context, tool calls, decision path)
Production evaluation (continuous, not periodic)
sampled evaluations on real traffic
triggered evals on risky patterns (tool failures, escalations, loops)
human review queues for ambiguous/high-stakes cases
outcome-linked evals tied to business signals (resolution, deflection, CSAT)
This is where teams stop asking “does it work?” and start answering “how does it behave, and when does it fail?”
Phase 7: Improve safely (iterate without breaking trust)
Once you can observe behavior and measure outcomes, improvement becomes engineering, not guesswork:
Fix the failure mode (prompt, retrieval, routing, tool contract, guardrail)
Re-run evaluations (offline suites first)
Deploy behind a controlled rollout
Monitor deltas in cost, behavior, and outcomes
Promote, roll back, or retire
This is also where teams need discipline: changes that “feel small” can change unit economics and reliability.
6: Operational walkthrough: preparing an agent for evaluation
Understanding evaluation conceptually is straightforward, but implementing it in practice is a lot more difficult.
Most teams begin building AI agents the same way they experiment with LLMs: a prompt in a notebook, a chat interface, or a small internal tool. The system appears to work, feedback is gathered informally, and improvements are made by adjusting prompts, swapping models, or adding more context.
This approach works for prototyping, but it breaks down as soon as the agent becomes operational. Once multiple users interact with the system, behavior varies across requests, failures become harder to reproduce, and teams can no longer determine whether a change actually improved performance.
Evaluation requires a different approach from experimentation. An agent can`t be reliably evaluated if its behavior is informal, its inputs are inconsistent, and its executions are not recorded. Before metrics, benchmarks, or judges can be applied, the agent needs to be structured as a repeatable system.
This section walks through the operational steps teams take to move from a prototype agent to one that can be measured, compared, and safely improved.
6.1: Define the agent behavior
Before an agent can be evaluated, its expected behavior must be explicitly defined.
Most teams try to evaluate AI systems while the agent itself is still informal. Examples include a prompt in a notebook, a few instructions in a chat interface, or a workflow that multiple developers modify over time. In this state, behavior changes constantly.
When performance improves or degrades, it's unclear whether the change came from the model, the prompt, the retrieval configuration, or the surrounding logic. As a result, any evaluation performed at this stage produces inconsistent and misleading results.
To make evaluation meaningful, we need the agent to be a stable system. Rather than treating it as a conversational interface, you`ll want to define the agent as a configuration: a versioned specification describing what the system is responsible for, what information it may rely on, and how it should behave when it can`t complete a task.
This definition establishes several critical elements:
Scope: what types of questions the agent is intended to handle
Grounding requirements: which knowledge sources the agent should use
Response expectations: tone, structure, and level of detail
Failure behavior: how the agent should respond when information is missing or uncertain
By defining these constraints, you create a behavioral contract. The agent isn`t just an open-ended assistant anymore, but a bounded operational system. This distinction is essential because evaluation doesn`t measure whether a response “sounds good”; it measures whether the system behaves according to its intended role.
6.2: Discover failure modes through systematic error analysis
After defining the agent's expected behavior, the natural instinct is to immediately start writing test cases. Teams sit down and brainstorm scenarios they think the agent might struggle with: edge cases they can imagine, common questions they expect, a few adversarial prompts they've seen in demos.
The problem with this approach is that it's based on assumptions about how the system fails instead of observations of how it actually fails. A brainstormed test suite tends to cover the obvious cases while missing the failure patterns that only emerge under real usage.
Before building an evaluation dataset, teams need a structured way to observe the agent's real behavior and discover where it breaks down. This process is called error analysis. It produces a grounded understanding of the system's actual failure modes, which then directly informs what goes into the evaluation dataset.
Step 1: Collect an initial set of traces
Error analysis starts with traces, not test cases.
A trace is the full record of a single agent execution: the user input, every intermediate step (retrieval, tool calls, model responses), and the final output. Traces are essential because failures often originate in intermediate steps that aren't visible in the final response.
The goal is to collect roughly 100 diverse traces. This number provides enough variety to surface a broad range of failure patterns without requiring an overwhelming review effort.
There's two ways to collect these traces:
From production logs (preferred when available): If the agent is already handling real traffic, sample traces directly. Avoid sampling only the most common queries. Focus on using stratified sampling or clustering on query embeddings to ensure coverage across different types of user behavior. Keep in mind the goal is diversity, not representativeness of traffic volume.
From synthetic queries (when production data is sparse): If the agent hasn't been deployed yet or traffic is limited, generate synthetic queries to run through the system. However, simply prompting an LLM to "generate user queries" produces generic, repetitive results that don't reflect real usage patterns.
A more effective approach is to generate synthetic queries in two structured steps:
First, define key dimensions along which user queries vary. These dimensions should reflect where the agent is most likely to fail. For a support agent, useful dimensions might include:
Feature area: billing, account access, product configuration, returns
User persona: new customer, enterprise admin, frustrated repeat caller
Scenario complexity: straightforward question, ambiguous request, out-of-scope query, multi-step task
Second, create structured combinations (tuples) of these dimensions, then generate a natural-language query for each tuple. Start by writing 15–20 tuples manually, then use an LLM to scale up. You'll also want to separate the tuple generation from the query generation. This two-step approach produces more diverse and realistic queries than generating both at once.
For each generated query, run it through the agent end-to-end and record the full trace. After filtering out duplicates and unrealistic queries, you should have roughly 100 traces ready for analysis.
Step 2: Read traces and annotate failures (open coding)
With traces collected, the next step is to read them carefully and take notes.
For each trace, focus on the first significant failure, which is the earliest point in the execution where something went demonstrably wrong. This is important because agent failures often cascade: a mistake in an early step (misinterpreting user intent, retrieving the wrong documents) causes a chain of downstream problems.
Record each trace with its annotation in a simple table: trace identifier, a summary of the trace, and the freeform observation. At this stage, don't try to categorize or organize. Just capture what you see.
In early stages, this annotation process is often done outside the platform using a spreadsheet or simple annotation tool. The goal is simply to capture observations consistently. As the system grows and more people become involved, teams often move this workflow into dedicated annotation queues inside the platform.
A few examples of what these annotations might look like for a knowledge base support agent:
Trace | Observation |
User asks about refund eligibility for a specific product | Agent cites the general refund policy but ignores the product-specific exception documented in the knowledge base. Retrieval returned the right document, but the agent used the wrong section. |
User asks for the CEO's personal phone number | Agent correctly refuses but gives a vague explanation. Should reference the data privacy policy explicitly. |
User asks a billing question in French | Agent switches to French mid-response but uses the English-language knowledge base, producing a mix of translated and untranslated policy terms. |
Continue this process until you've annotated at least 20 traces with clear failures and new traces are no longer revealing fundamentally different problems. This point is known as theoretical saturation, and typically arrives after reviewing 50–100 traces, depending on the system's complexity.
If you find yourself stuck and unsure how to describe what feels wrong about a trace, it can help to check against common LLM failure patterns: hallucinated facts, constraint violations, incorrect tool usage, inappropriate tone, missing information, or fabricated references. Use these as diagnostic lenses, but don't force your observations into predefined categories.
Step 3: Structure failure modes (axial coding)
Open coding produces a valuable but messy collection of observations. The next step is to organize them into a coherent set of failure categories.
Read through all your annotations and look for patterns. Some clusters will be obvious: traces where the agent ignores constraints, traces where it retrieves the wrong documents, traces where it fabricates information. Other distinctions will only become clear after reviewing several examples.
The goal is to define a small set of binary, non-overlapping failure modes. Each failure mode should be:
Specific enough to be consistently recognizable across different traces
Binary - it either occurred or it didn't (avoid rating scales at this stage)
Non-overlapping - a single failure should map to one category, not multiple
For a knowledge base support agent, the structured failure modes might look like:
Failure mode | Definition |
Missing constraint | The agent ignores a user-specified filter or condition (product type, date range, eligibility criteria) |
Wrong knowledge source | Retrieval returns relevant documents, but the agent uses information from the wrong section or document |
Fabricated policy | The agent references a policy, rule, or procedure that doesn't exist in the knowledge base |
Incomplete escalation | The agent should have escalated to a human but either didn't escalate or escalated without providing context |
Persona-tone mismatch | The response tone doesn't match the user's context (e.g., overly casual for a formal enterprise inquiry) |
You can paste your raw annotations in a LLM to help with the clustering and ask it to propose groupings, but don't accept its categories blindly. Review and adjust them based on your understanding of the system and its operational context.
Step 4: Quantify and label
Once the failure taxonomy is defined, go back through all your traces and label each one against the structured categories. For every trace and every failure mode, mark it as present (1) or absent (0).
This produces a table you can use to quantify the prevalence of each failure type. Count how often each failure mode appears across your traces. This quantification is critical for prioritization: it tells you which failures are common enough to warrant automated evaluation and which are rare edge cases you can address later.
Before building evaluators for these failure modes, apply the specification vs. generalization triage from section 4 first by improving prompts, tool descriptions, or system configuration.
Step 5: Iterate
Error analysis isn’t a one-pass process, so you’ll want to do the following after the first round:
Sample new traces (or generate new synthetic queries) to check whether additional failure modes emerge.
Refine your failure taxonomy - some categories may need to be split, merged, or redefined as you see more examples.
Re-label earlier traces if the taxonomy changed significantly.
Two serious rounds of analysis are usually sufficient to reach a stable taxonomy. Beyond that, additional effort produces diminishing returns.
What this produces
At the end of error analysis, you have three artifacts that directly feed into the next steps:
A failure taxonomy: a structured, application-specific vocabulary for describing how your agent fails. This replaces generic categories like "hallucination" or "bad response" with precise, observable failure modes grounded in real system behavior.
A labeled dataset of ~100 traces: each annotated with which failure modes are present. This becomes the foundation of your evaluation dataset (covered in the next section, 6.3).
Prioritized failure modes: a quantified view of which failures are most common, which guides where you invest evaluation effort first.
This process will make sure your evaluation dataset isn't built on guesswork. Instead, it's grounded in systematic observation of how the system actually behaves, what patterns of failure it exhibits, and which issues are frequent enough to warrant ongoing measurement.
The goal isn’t to review every trace indefinitely. Teams typically continue this process until reviewing additional traces stops revealing new categories of failures. Once this point is reached, the failure taxonomy is considered saturated. At that stage, teams shift focus from discovery to improvement by investigating root causes and building regression tests to make sure they don’t return.
6.3: Build an evaluation dataset (representative scenarios)
With a failure taxonomy in hand, the next step is to convert observed failures into repeatable evaluation cases. Each important failure mode should be represented by multiple dataset entries, including both expected-success cases and failure-exposing cases. This will make sure the evaluation suite reflects how the system actually breaks, rather than how the team assumes it might break.
An agent can't be meaningfully evaluated if every interaction depends on unpredictable context. When teams test agents informally, asking different questions each time and providing varying background information, failures are tough to diagnose.
To address this, you need to define representative interaction scenarios. Instead of relying on ad-hoc conversations, they create structured datasets containing example user requests and the expected system behavior. Each entry functions as a repeatable test case: the same input can be run again after any change to determine whether the system improved or regressed.
These datasets don`t necessarily “train” the model. They establish a controlled environment for evaluation. By specifying both the user message and the intended outcome, you can make success criteria explicit. A support agent, for example, should correctly explain policy-related questions and refuse requests for sensitive information.
Once both the agent behavior and its interaction scenarios are defined, the system can be executed in a controlled manner. The next step is to run the agent and record what actually happens during real interactions.
6.4: Execute the agent and record traces
Once behavior and test scenarios are defined, the agent can be executed in a controlled environment. At this point, the goal isn`t any longer to see whether the system can produce a plausible answer. Instead, the objective is to observe how the system behaves when it processes real inputs.
In practice, the agent is executed as an experiment using the evaluation dataset. The platform runs the configured agent against each example user request and records the outcome of every interaction.
For each entry, the platform sends the same user message to the agent, generates a response, and records the full interaction. Each recorded interaction is stored as a trace. Without traces, teams can only evaluate outputs. When an answer is incorrect, the cause remains ambiguous.
The failure might come from reasoning, missing documentation, incorrect retrieval, or even unexpected prompt behavior. Observability solves this ambiguity by turning each interaction into inspectable evidence.
By opening the trace view, it's possible to inspect the full execution timeline. You can see when the model was called, whether retrieval occurred, how long each step took, and which evaluator produced the final result.
After execution, the platform automatically compares the generated outputs with the reference answers using an evaluator. Instead of checking for exact wording, the evaluator assesses whether the response fulfills the agent’s intended role, as we defined earlier in 6.1. A response that uses different phrasing but communicates the same capability may pass, while a fluent but misleading answer fails.
Because every dataset entry is repeatable, the same experiment can be run again after any change, such as a prompt update, a new model, or modified documentation. The platform then produces a pass/fail result for each case. Over time, these results form a measurable quality signal and you can determine whether the system improved, regressed, or behaved inconsistently.
7: What actually needs to be evaluated
After understanding that agents can’t be validated with simple prompt testing, the next question becomes practical:
What should we evaluate?
A common mistake is to evaluate only the final response. Teams check whether the answer “looks right,” and if it does, they assume the system is working. That approach fails because agents aren’t single outputs. Instead, they’re workflows. A response might seem correct on the surface while the system behaves incorrectly underneath.
Production evaluation expands beyond response quality. To operate an agent reliably, teams need to evaluate four distinct layers simultaneously: response quality, safety and governance, behavioral execution, and operational performance.
Each layer answers a different operational question.
7.1 Quality of answers
The most visible aspect of an agent is the response itself, so this serves as a natural starting point. But it’s important to realize quality isn’t a single metric. It’s a combination of correctness, relevance, grounding, and conversational reliability.
The first measure is task success. Did the agent actually accomplish what the user asked? A fluent answer does not necessarily mean the task was completed. A support agent that politely explains a refund policy but gives the wrong eligibility rule has failed, even though the response sounds helpful.
Closely related is answer relevance. The agent may provide technically correct information that does not address the user’s intent. This often happens when agents over-generalize or latch onto keywords rather than understanding the request.
Quality evaluation answers: can users depend on the agent’s answers across real conversations, not just isolated prompts?
7.2 Safety and governance
Quality alone is insufficient for production deployment. An agent that performs tasks correctly but behaves unsafely cannot be trusted in a real workflow.
Safety evaluation focuses on harmful behavior. This includes generating toxic or biased content, responding inappropriately to sensitive requests, or following malicious instructions. Agents must also resist jailbreak attempts, where prompts try to override system rules or policies.
Governance extends beyond content moderation. Production agents interact with real data, which introduces compliance requirements. Systems must properly handle personally identifiable information, respect access controls, and avoid exposing restricted data. For example, an internal enterprise assistant should not reveal information from another department’s records, even if the request sounds reasonable.
Safety evaluation answers a different question than quality:
Even when the agent is capable, is it safe to allow it to operate?
7.3 Agent behavior and system outcomes
One of the most important (and often overlooked) evaluation targets is how the agent reaches its answer.
Agents carry out various tasks like retrieving documents, calling APIs, querying databases, and interacting with other services. A system can produce a correct final answer while executing the wrong workflow, which becomes unstable at scale.
This is why teams evaluate tool usage. Did the agent choose the correct tool? Did it pass valid arguments? Did the call succeed? Repeated failed calls, unnecessary retries, or incorrect parameters often indicate deeper reasoning problems.
In multi-step workflows, teams also evaluate planning behavior. The agent should make forward progress toward the goal rather than looping, stopping prematurely, or performing redundant actions. In multi-agent setups, coordination matters as well: agents should hand off tasks correctly and avoid conflicting decisions.
7.4 Operational performance and business impact
Even a high-quality, safe, well-behaved agent may still fail operationally if it is too slow, too expensive, or economically ineffective.
Latency matters because users expect responsive interactions. An agent that takes thirty seconds to answer a simple question will not be adopted, regardless of correctness.
Cost is equally critical. Agents make runtime decisions: they choose models, retry steps, expand context, and call external services. These behaviors directly affect spending. Without measuring cost per interaction and cost per successful task, teams cannot predict scalability.
Finally, evaluation connects to business outcomes. Organizations measure whether the agent improves operational metrics such as resolution time, task completion rate, deflection from human support, or customer satisfaction. A technically impressive system that does not improve real workflows does not create value.
Layer | Question it answers | Example metrics |
Quality | “Is the answer useful/correct?” | task success, relevance, groundedness |
Safety & governance | “Is it safe/compliant?” | jailbreak rate, PII violations |
Behavior | “Did it act correctly?” | tool success, loops, plan progress |
Ops & business | “Is it viable at scale?” | latency, cost per task, deflection |
8: Types of AI evaluations
After knowing what needs to be measured, the next question becomes operational: how do you actually evaluate an AI agent?
Note that there isn’t a single evaluation method that works for every agent system. Production agents combine language generation, reasoning, tool usage, and decision-making. Because of this, teams rely on multiple complementary evaluation approaches rather than a single metric.
Modern agent evaluation typically uses four categories of methods. Each answers a different question about reliability, and none of them is sufficient on its own.
8.1 Reference-based evaluations
The most familiar evaluation method is the closest to traditional testing. A dataset of labeled examples is created, each with an expected outcome, and the agent’s responses are compared against it.
For example, a support agent may be tested on historical tickets. A sales agent might be evaluated on lead-qualification decisions. A RAG system may be tested on known questions with verified answers. The agent’s outputs are then scored using accuracy-like measurements such as correctness, task success, relevance, or recall.
However, reference-based evaluation has an important limitation: many real-world tasks don’t have a single correct answer. A response may be technically correct but unhelpful. Another may be slightly inaccurate but still useful.
Best for: regressions, deterministic tasks, and correctness checks where a gold answer exists.
Weak for: open-ended helpfulness, tone/brand fit, and cases where multiple answers are acceptable.
8.2 Heuristic and rule-based evaluations
The second category consists of automated checks written as rules.
Instead of judging whether an answer is “good,” these evaluations verify whether the agent followed constraints. For example:
Did the output follow a schema?
Did it include required fields?
Did it leak sensitive information?
Did it call the correct tool?
Did it stay within the allowed response format?
These checks are precise and inexpensive. They run quickly and can evaluate thousands of interactions continuously.
Rule-based evaluations are essential for safety and governance. They can detect toxicity, policy violations, PII exposure, or off-topic outputs before they reach users, acting as guardrails embedded directly in the system.
Their limitation is scope, as rules only catch what they were designed to detect. They can’t reliably measure nuanced qualities such as reasoning quality, helpfulness, or groundedness.
Best for: enforceable constraints (schemas, tool usage rules, PII/policy checks) at high volume and low cost.
Weak for: semantic quality (helpfulness, reasoning, groundedness) and novel failure modes you didn’t explicitly encode.
8.3 LLM-as-judge evaluations
To measure semantic quality at scale, teams increasingly use language models themselves as evaluators.
In this approach, another model reviews the agent’s output and scores it according to a rubric. Instead of exact matching, the evaluator can judge properties such as:
helpfulness
groundedness
safety
policy adherence
reasoning quality
This method sits between automated rules and human review. It captures nuance while remaining scalable.
For instance, rather than checking whether a response exactly matches a reference answer, the evaluator can determine whether the answer actually solves the user’s problem or whether it hallucinated unsupported facts.
LLM-based scoring is widely used because it enables continuous evaluation across large volumes of real interactions. It also allows teams to compare prompt versions, model choices, and workflow changes objectively.
However, it still requires calibration. Evaluator models can be biased, inconsistent, or overly lenient if the scoring criteria are not clearly defined. As a result, teams often combine LLM scoring with other evaluation types rather than relying on it alone.
Best for: semantic scoring at scale (helpfulness, groundedness, policy adherence) using clear rubrics.
Weak for: consistency without calibration because judges can drift, be biased, or over-reward fluent but wrong answers.
8.4 Human evaluation
Despite automation, human review remains essential.
Humans evaluate aspects that automated systems still struggle to judge reliably:
whether an answer is actually helpful
whether tone matches brand expectations
whether reasoning is misleading
whether behavior creates real-world risk
Production systems therefore include annotation workflows. A subset of interactions is reviewed manually, often selected from edge cases, failures, or high-risk scenarios. These reviews validate automated metrics and refine evaluation criteria.
Human-in-the-loop review is also used to audit system performance and verify reliability, especially in sensitive domains.
While expensive, human evaluation serves as the ground truth that keeps automated metrics meaningful.
Best for: ground truth on ambiguous or high-stakes cases (safety, compliance, brand tone) and calibrating automated metrics.
Weak for: continuous coverage, as review is slow and expensive. Must be sampled and targeted to high-risk slices.
Evaluation type | What it checks | Best used for | Weak for | Typical implementation |
Reference-based | Whether the output matches an expected answer or known outcome | regressions, deterministic workflows, structured tasks with clear ground truth | open-ended helpfulness, conversational quality, and multi-valid answers | labeled datasets, gold answers, accuracy/task-success scoring |
Heuristic / rule-based | Whether the agent followed defined constraints | safety enforcement, schemas, tool usage rules, PII/compliance checks at scale | nuanced reasoning quality, helpfulness, and unseen failure modes | tool argument checks, policy filters, guardrails |
LLM-as-judge | Semantic quality of the response and behavior | helpfulness, groundedness, policy adherence, comparing prompts/models at scale | strict reliability without calibration; may reward fluent but wrong answers | rubric-prompted evaluator models scoring responses or traces |
Human evaluation | Real-world usefulness and risk | high-stakes workflows, ambiguous cases, brand tone, calibration of automated metrics | continuous coverage due to cost and speed limitations | annotation queues, sampled audits, expert review workflows |
Together, they form a layered reliability strategy rather than a single metric.
If the task has a clear correct output → reference-based (fast regression signal)
If the system must obey constraints → rules (schemas, PII, tool usage, permissions)
If you need semantic judgment at scale → LLM-as-judge (with calibration)
If stakes are high or ambiguity is real → human review (targeted sampling)
Most production teams run all four as a layered strategy: rules catch hard violations, references catch regressions, judges catch semantic drift, humans keep everything honest.
Next, we’ll look at how these evaluation approaches are applied in practice inside the Orq platform.
9: Measuring agent quality and deciding what to improve
After an agent can be executed and observed, the next challenge is determining whether it is actually reliable. A single successful interaction doesn't fully demonstrate quality. Even a series of successful interactions can be misleading if failures occur in situations that were not tested. That's why it's important to have a consistent way to judge correctness across many scenarios, not individual conversations.
Traditional software systems solve this with automated tests. AI agents complicate this model because correctness isn't always a precise output. Two responses may use different wording yet both be valid, while a fluent response may still be incorrect.
Evaluation provides a structured alternative. Instead of asking whether the agent “seems to work,” you can measure behavior against defined expectations across repeatable scenarios. Each run produces evidence: which cases passed, which failed, and how consistently the system performs.
The following sections describe how automated evaluation, repeatable experiments, and human review work together to determine agent readiness and guide iterative improvement.
9.1: Automated evaluation (LLM judges and rule checks)
In practice, teams rarely start with complex evaluation suites. A common starting point is evaluating tool correctness (when the application uses tools) together with a basic groundedness or hallucination check.
The key recommendation is to start simple. A small number of focused evaluators is usually more useful than building many evaluators prematurely. Once experiments and traces are running end-to-end, teams can analyze outputs and gradually introduce more specialized evaluators for answer quality, reasoning, or domain-specific constraints.
After the agent has been executed and traces have been recorded, the platform can automatically assess whether the system behaved correctly. Instead of relying on manual review, Orq uses automated evaluators to analyze each interaction and determine if the agent fulfilled its intended role.
Two categories of automated checks are commonly used:
Rule-based checks verify structural or deterministic conditions. These include requirements such as refusing restricted requests, using approved tools, or staying within defined operational boundaries. They are precise and reliable but limited to conditions that can be explicitly defined.
LLM judges evaluate behavioral correctness. Instead of comparing wording, the evaluator analyzes whether the generated response satisfies the expected outcome defined in the dataset. The platform compares three elements: the user query, the agent’s generated response, and the reference answer.
The evaluator then determines whether the response is semantically correct.
Unlike traditional testing, the system doesn't exact phrasing. A response may pass even if it uses different wording, as long as it communicates the same capability or instruction. Conversely, a fluent and well-written answer may fail if it provides incorrect information or violates the defined behavior.
The inspection view shows how the evaluator processes an interaction. The platform sends the query, response, and expected output to the judge model, which returns a verdict and explanation. This turns evaluation into an objective decision rather than a subjective review.
Each interaction now produces a measurable result. Instead of reviewing conversations manually, teams receive consistent pass/fail judgments across the entire dataset. This enables reliable comparison when prompts, models, or knowledge sources change.
9.2: Running repeatable evaluation experiments
Evaluating a single response is useful for debugging, but it does not tell a team whether the agent is dependable. An agent may answer one question correctly and another incorrectly, even though both appear similar. For this reason, evaluation needs to be performed across many representative scenarios rather than individual conversations.
To achieve this, Orq executes the agent against the full dataset of test cases in a single run. Each dataset entry is processed using the same configuration: the same prompt, model, knowledge sources, and system behavior. Because the inputs are fixed, the results become directly comparable across time.
This process creates an evaluation experiment.
During an experiment, the platform:
sends each dataset question to the agent
records the generated response
evaluates the response using automated judges
records performance metrics such as latency and cost
The results are aggregated into a structured report where each row represents one interaction scenario.
The table shows the outcome of every test case. For each scenario, you can see:
the generated answer
whether the evaluator passed or failed it
operational metrics such as response time and cost
This is important because reliability problems rarely appear as total failure. Instead, they appear as partial correctness. An agent may perform well on common questions but fail on edge cases such as clarification requests, procedural instructions, or policy boundaries. Running the full dataset exposes these patterns immediately.
Repeatability is the key property. The same experiment can be executed again after any system change. For example:
updating the prompt
switching models
modifying documentation
adjusting retrieval configuration
Because the test cases remain constant, differences in results reflect actual system changes rather than random variation. You'll be able to determine whether performance improved, regressed, or shifted in specific categories of behavior.
9.3: Human review and edge-case validation
Automated evaluation measures whether an agent behaves correctly in known scenarios. However, real users do not always behave like predefined test cases. They ask unexpected questions, interpret responses differently, and interact with the system in ways the dataset cannot fully anticipate.
For this reason, evaluation doesn't end after an experiment run. Teams also monitor production interactions.
In Orq, this is done using annotation queues and automations. Instead of manually reviewing conversations, the platform automatically samples real interactions and routes them to human reviewers. Each sampled conversation appears in a review queue, where reviewers can identify incorrect answers, unclear explanations, or policy violations.
This serves a different purpose from automated evaluation. Evaluators measure known behavior, while human review detects unknown failure modes.
When issues are discovered, you can update prompts, documentation, or test cases and re-run evaluation experiments. In this way, monitoring feeds back into structured evaluation, and evaluation feeds back into system improvements.
10: From evaluation to observability (add more later with platform)
Evaluation helps you answer a specific question: did this version of the agent behave correctly on a defined set of cases? Observability answers a different one: what is the agent actually doing in the real world right now, and why?
Instead of only checking whether the final answer looked correct, observability inspects the trajectory: which tools were called, what context was retrieved, how the model reasoned, and where a decision changed.
Evaluation tells you whether a change improved behavior.
Observability explains why the behavior occurred.
In practice, production agent systems rely on three complementary forms of runtime visibility:
Logs capture inputs and outputs: what the user asked and what the agent answered.
Metrics measure aggregate performance: latency, error rate, cost, and usage patterns.
Traces show the execution path: the sequence of reasoning steps, retrieval operations, and tool calls.
11: Why evaluation becomes an organizational function
Early on, evaluation looks like an engineering activity: write a few test prompts, compare outputs, ship changes. That framing breaks as soon as agents move from a single sandbox workflow to real, cross-team usage. In practice, evaluation becomes organizational because agents create shared operational risk, and shared risk always forces shared ownership.
One reason is scale and autonomy. As agents move from prototypes to real deployment, organizations quickly realize they’re unsure how to evaluate, manage, and govern them responsibly. This is particularly the case as autonomy increases and agents start interacting with tools, systems, and real users.
Another reason is accountability. An agent system touches multiple stakeholders: product defines success criteria, engineering owns workflows and integrations, security cares about access control and misuse, legal/compliance cares about policy and regulatory boundaries, and finance cares about cost predictability.
So the shift is predictable: evaluation starts as a quality technique, but becomes an operating model. You end up with shared definitions (what counts as success), shared tooling (where evals run and where results live), and shared processes (who reviews failures, who approves changes, and what gets blocked).
12: How evaluation connects to cost
Many teams first notice an AI agent problem as a financial problem.
An invoice arrives, usage spikes, or leadership asks why operating the assistant suddenly costs more than expected. The immediate reaction is usually to inspect model usage: token counts, API calls, or the price of the chosen model. But those numbers rarely explain what actually happened. They show how much was spent, not why it was spent or whether the spending produced useful outcomes.
Without evaluation, teams can observe spending but cannot interpret it. They can see token usage rise, but they can’t determine whether the agent became more helpful, less reliable, or simply inefficient. Cost becomes actionable when you can attribute spend to behavior patterns (retries, long traces, tool loops) and tie it to success rate.
Over time, evaluation allows organizations to connect three signals that were previously isolated: what the agent did, what it cost, and whether it worked. Once those signals are linked, cost becomes explainable. Engineers can identify inefficient workflows, product teams can understand tradeoffs between quality and latency, and leadership can forecast operating expenses with confidence.
13: From debugging to operating: the real role of evaluation
At the start of this guide, we described a common experience: an AI agent works in demos but becomes unpredictable once real users arrive. Responses seem correct most of the time, yet occasional failures appear without a clear cause. Teams investigate incidents one by one, adjust prompts, and hope behavior improves.
Evaluation changes that.
When interactions are measured consistently, failures stop looking random. Patterns emerge. Agents often struggle in specific situations: ambiguous requests, long contexts, or multi-step workflows. What appears to be hallucination frequently turns out to be a system issue: missing context, poor retrieval, incorrect tool usage, or an unsafe execution path.
Evaluation also shows that agents rarely “break.” They drift. Small changes to prompts, models, tools, or knowledge bases gradually affect outcomes while the system still appears healthy. Without measurement, teams notice only after trust declines.
Instead of reacting to incidents, teams begin to:
Turn failures into regression cases
Compare changes before release
Detect behavior shifts early
Expand usage safely
In practice, evaluation doesn’t primarily measure model quality. It makes the system understandable and controllable. Combined with observability and controlled rollouts, it turns an agent from a black box into a managed production service.
The original problem, an agent that shows value but can’t be trusted, isn’t solved by a better prompt or a larger model. Instead, it’s solved by measurement. Evaluation provides the bridge between experimentation and reliable operation, letting teams treat AI agents not as demos, but as systems they can safely depend on.
Source for section 2
https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
https://www.domo.com/blog/ai-evaluations-101-testing-llms-agents-and-everything-in-between
https://www.ibm.com/think/topics/ai-agent-evaluation
https://www.getmaxim.ai/articles/ai-agent-evaluation-metrics-strategies-and-best-practices/
https://deepeval.com/guides/guides-ai-agent-evaluation
https://aisera.com/blog/ai-agent-evaluation
https://arxiv.org/html/2507.21504v1
https://huggingface.co/papers/2503.16416
http://scis.scichina.com/en/2025/121101.pdf
https://openreview.net/forum?id=zAdUB0aCTQ
https://arxiv.org/html/2512.08273v1
Section 3 Source
https://coralogix.com/ai-blog/why-traditional-testing-fails-for-ai-agents-and-what-actually-works/
https://techstrong.ai/aiops/rethinking-ai-testing-why-traditional-qa-methods-fall-short/
https://www.disseqt.ai/articles/why-traditional-testing-fails-in-the-age-of-ai
https://blog.sigplan.org/2025/03/20/testing-ai-software-isnt-like-testing-plain-old-software/
https://arxiv.org/html/2503.03158v1
https://arxiv.org/abs/2307.10586
https://www.arxiv.org/abs/2503.03158
https://arxiv.org/abs/2503.16416
Section 4 source
https://arxiv.org/abs/2401.05856
https://arxiv.org/html/2508.07935v1
https://arxiv.org/html/2510.06265v2
https://dl.acm.org/doi/10.1145/3703155
https://www.nature.com/articles/s41598-025-15416-8
https://www.evidentlyai.com/blog/llm-hallucination-examples
https://arxiv.org/abs/2510.13975
https://arxiv.org/abs/2401.05856
https://chrislema.com/ai-context-failures-nine-ways-your-ai-agent-breaks/
https://manveerc.substack.com/p/ai-agent-hallucinations-prevention
https://arxiv.org/html/2508.07935v1
https://galileo.ai/blog/agent-failure-modes-guide
https://arxiv.org/abs/2401.05856
https://arxiv.org/html/2508.07935v1
Section 5
https://arize.com/blog/evaluating-and-improving-ai-agents-at-scale-with-microsoft-foundry/
https://www.fiddler.ai/blog/end-to-end-agentic-observability-lifecycle
https://www.adopt.ai/blog/observability-for-ai-agents
https://microsoft.github.io/ai-agents-for-beginners/10-ai-agents-production/
https://www.sciencedirect.com/science/article/abs/pii/S1566253525009273
https://openreview.net/forum?id=sooLoD9VSf
https://arxiv.org/html/2510.03463v2
https://onereach.ai/blog/llmops-for-ai-agents-in-production/
https://www.braintrust.dev/articles/best-llmops-platforms-2025
https://www.fiddler.ai/blog/end-to-end-agentic-observability-lifecycle
https://www.youtube.com/watch?v=5jMEf2-CPDY&t=4s
Section 7
https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
https://www.kore.ai/blog/ai-agents-evaluation
https://arxiv.org/html/2507.21504v1
https://samiranama.com/posts/Evaluating-LLM-based-Agents-Metrics,-Benchmarks,-and-Best-Practices/
https://www.confident-ai.com/blog/llm-agent-evaluation-complete-guide
https://www.geeksforgeeks.org/nlp/evaluation-metrics-for-retrieval-augmented-generation-rag-systems/
https://www.aviso.com/blog/how-to-evaluate-ai-agents-latency-cost-safety-roi
https://www.deepchecks.com/llm-agent-evaluation/
Section 8
https://www.domo.com/de/blog/ai-evaluations-101-testing-llms-agents-and-everything-in-between
https://www.confident-ai.com/blog/llm-agent-evaluation-complete-guide
https://arxiv.org/html/2507.21504v1
https://www.deepchecks.com/llm-agent-evaluation/
https://arxiv.org/html/2408.09235v2
https://mirascope.com/blog/llm-as-judge
https://agenta.ai/blog/llm-as-a-judge-guide-to-llm-evaluation-best-practices
https://agenta.ai/blog/llm-as-a-judge-guide-to-llm-evaluation-best-practices
Section 10
https://langfuse.com/blog/2024-07-ai-agent-observability-with-langfuse
https://agentsarcade.com/blog/observability-for-ai-agents-logs-traces-metrics
https://www.fiddler.ai/blog/end-to-end-agentic-observability-lifecycle
https://www.datarobot.com/blog/agentic-ai-observability/
https://opentelemetry.io/blog/2025/ai-agent-observability/
Section 11
https://aigrowthlogic.com/ai-data-evaluation-pipelines/
https://www.aigl.blog/ai-model-risk-management-framework/
https://www.obsidiansecurity.com/blog/what-is-ai-model-governance
https://www.weforum.org/publications/ai-agents-in-action-foundations-for-evaluation-and-governance/
https://www.responsible.ai/news/navigating-organizational-ai-governance/ https://www.diligent.com/resources/blog/ai-governance
https://www.oecd.org/en/publications/2025/06/governing-with-artificial-intelligence_398fa287.html
Section 12
https://developer.ibm.com/tutorials/awb-comparing-llms-cost-optimization-response-quality/
https://arxiv.org/html/2507.03834v1
https://www.usagepricing.com/blog/choosing-ai-models-cost-quality/ https://www.prompts.ai/blog/task-specific-model-routing-cost-quality-insights
https://www.finops.org/wg/finops-for-ai-overview/
https://www.cloudzero.com/blog/finops-for-ai/
https://konghq.com/solutions/ai-cost-governance-finops
https://www.codeant.ai/blogs/llm-production-costs
https://debmalyabiswas.substack.com/p/agentic-ai-finops-cost-optimization
