


You've built your Retrieval-Augmented Generation (RAG) pipeline. Your vector database is humming along, your embeddings are crisp, and your LLM is ready to generate answers. But when you run your first queries, something's off: the retrieved documents are technically relevant, but buried among the noise of “close enough” matches that wastes tokens. This is the dirty secret of out-of-the-box RAG: retrieval is only half the battle. The real challenge is precision.
Reranking models address this challenge by examining query-document pairs simultaneously and reorder them based on the query-document relevance.
In this blog, we will explain the Cohere Rerank 4 cross-encoder architecture, how it processes queries and candidates jointly, to capture semantic relationships and reorder results to surface the most relevant items.
Understanding out-of-the-box RAG
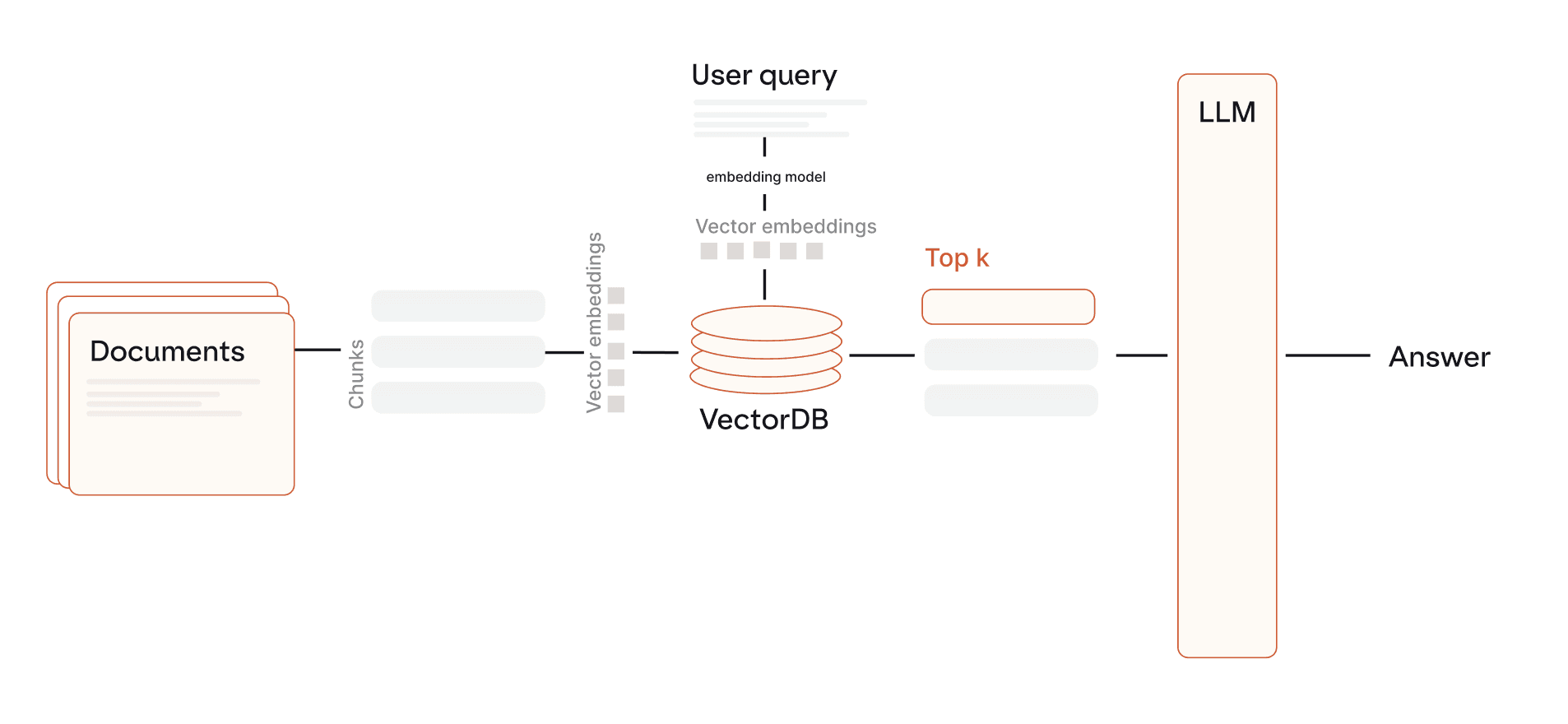
The goal of RAG is to optimize the outputs of an LLM and prevent hallucinations by providing access to external authoritative data sources. Every RAG pipeline consists of four main steps: Ingestion, Retrieval, Augmentation and Generation.
Ingestion
In this step your data (PDFs, web pages, databases) get broken into smaller pieces (chunks) and converted into a numerical format (vector embeddings). An embedding model does this conversion, translating text into numbers that capture its meaning. The reason why data is stored in the form of vectors is the ease and efficiency of semantic similarity search.
Retrieval
The system searches for the most relevant information from your vector database to the user's query. When a user asks a question, that query is converted into a vector and compared against all document vectors using cosine similarity or Euclidean distance. The system identifies and retrieves the top-k most similar document chunks. The retrieval step returns a ranked list of document chunks and their relevance score.
Augmentation
The search results from the retrieval step and the user’s query as context are sent to the LLM as an augmented prompt. Using both, the generator component is able to create a context-aware response.
Generation
The augmented prompt is then used to generate factually grounded and context aware responses.
What is a re-ranker?
While the out-of-the-box RAG pipeline works, there's a critical weakness in the retrieval step: bi-encoder embedding models must compress all possible meanings of a document into a single fixed vector, without knowing what query will eventually be asked. This creates two fundamental issues:
Information loss through compression: Complex documents are forced into a single point in vector space, losing nuance. The top-k retrieval often includes marginally relevant documents that match broadly, but miss the specific internet of the question.
Query-agnostic representations: Embeddings are generated at index time with no knowledge of future queries, producing generic, averaged meanings rather than query-specific relevance signals.
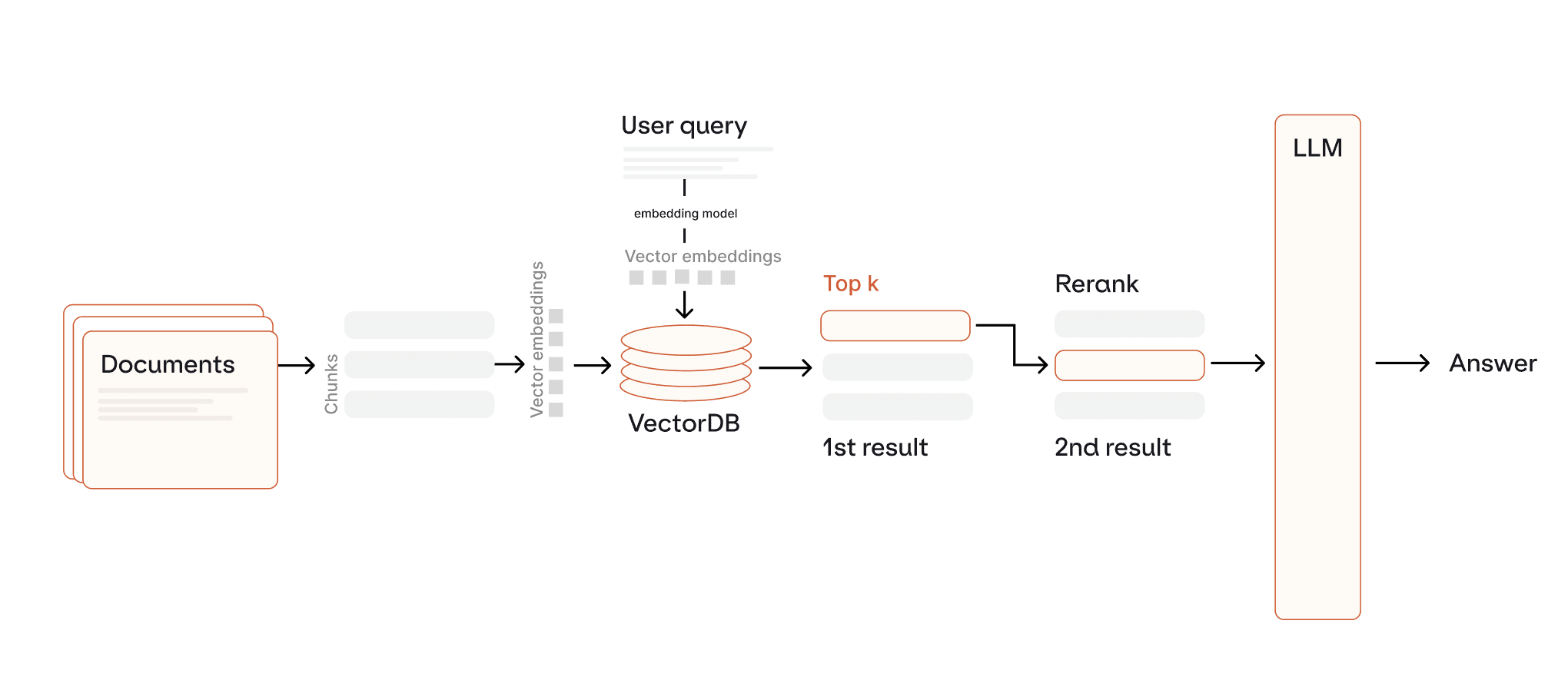
This is where re-rankers come in, which are models that act as a second-pass filter trained to surface the most relevant results from the retrieval pass of the RAG pipeline. Primarily, there are 3 types of re-rankers:
Cross-Encoder (
Rerank-4 , Rerank-4-Multilingual): process queries and documents as a unified input, encoding them in a single forward pass. This integrated approach captures intricate semantic relationships between the two texts, leading to superior relevance scoring precision. By jointly analyzing query-document interactions through shared attention mechanisms, cross-encoders achieve highly accurate reranking at the cost of computational efficiency.BERT-based (
BAAI BGE Reranker): These re-rankers utilize the BERT model to rerank embeddings. BERT’s bidirectional nature allows for a deep contextual understanding of the text, improving the relevance of search results by considering the context of both the query and the document.Bi-Encoders (
all-MiniLM-L6-v2, all-mpnet-base-v2): encode queries and documents in parallel. but these are typically used for initial retrieval, not reranking.
Cohere Rerank 4 model family has state-of-the-art reranking capabilities to improve search relevance and retrieval quality. We’ve added support for the following Cohere’s Rerank 4 models in Orq.ai:
Rerank-4 - The latest reranking model with improved accuracy and multilingual support.
Rerank-4-Multilingual - Optimized for cross-lingual search and retrieval across 100+ languages.
How to evaluate your re-ranker?
To demonstrate the difference between out-of-the-box RAG and RAG with re-ranking capabilities we have set up an experiment. For the out-of-the-box RAG we have used the embed-english-light-v3.0 model and for the re-ranker we have added Cohere 4 model on top of the embed-english-light-v3.0. We set up two project spaces (1) RAF and (2) RAG with Rerank. The use-case that we will be testing and evaluating the RAG systems for is document parsing of Federal Aviation Authority (FAA) for latest safety standards.
Step 1: Create two knowledge bases
We created a baseline Knowledge Base with the following pdf documents as sources: NTSB accident report, FAA Code of Federal Regulations and the FAA Safety report. The embedding model in the knowledge base used to create chunks was the embed-english-light-v3.0

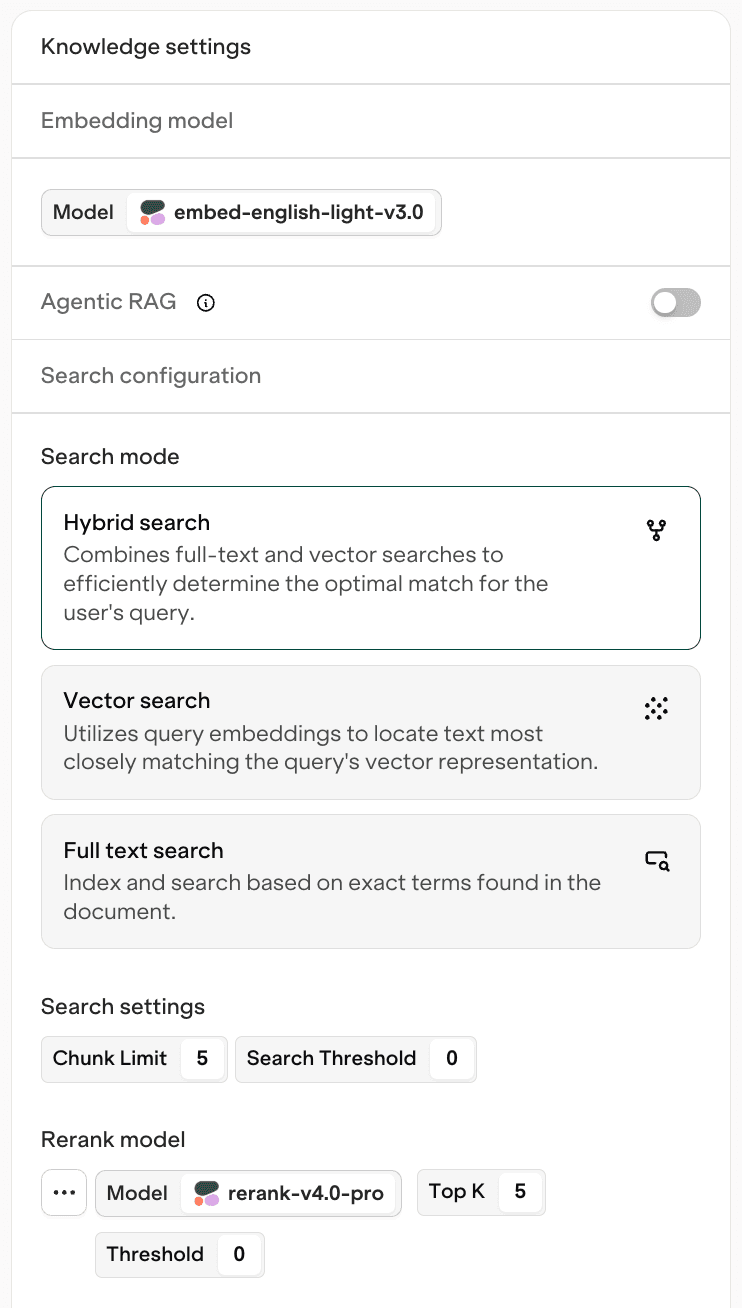
For the second Knowledge Base with a re-ranker in the settings we have enabled the Cohere rerank-v4 pro model:
Step 2: Set up the Out-of-the-box RAG
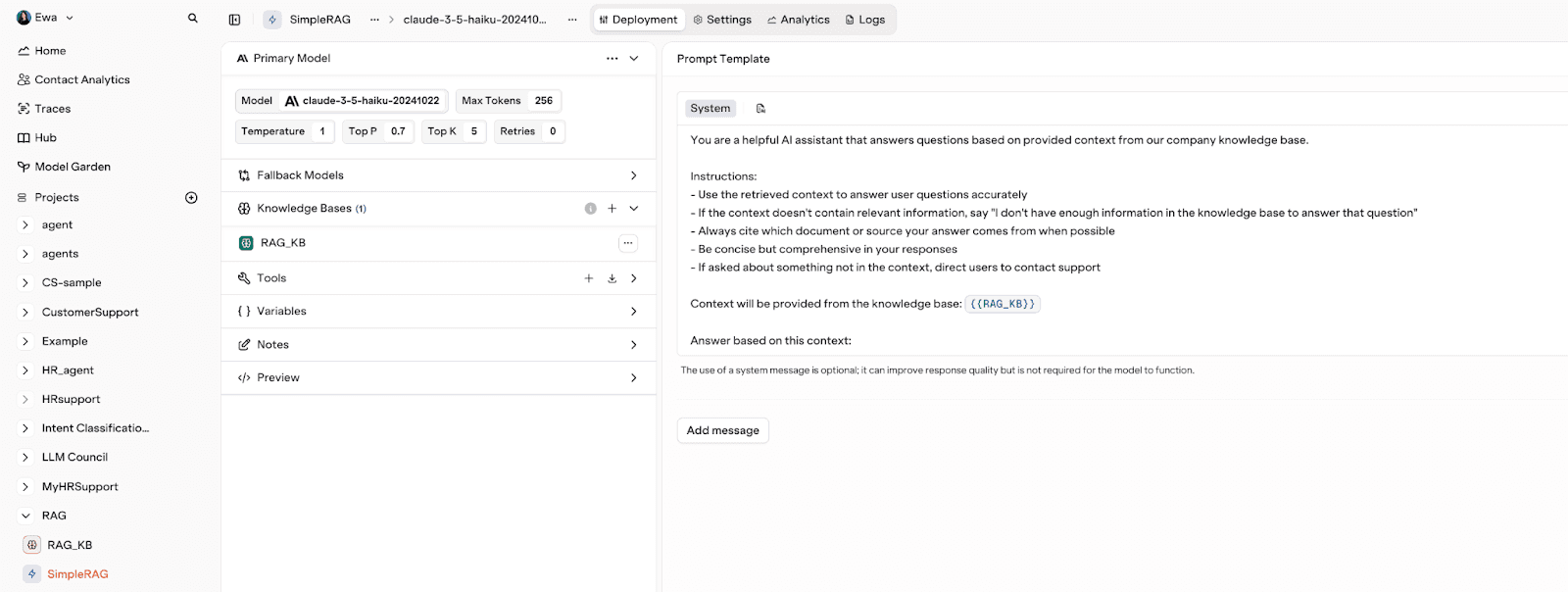
We created a SimpleRAG deployment, connected it to the Knowledge Base and set up a system prompt following the steps outlined in the documentation. The primary model for the deployment was claude-3-5-haiku
Step 3: Set up the RAG with Rerank
We followed the same steps as in Step 2 and assigned the Knowledge Base with reranker enabled to the deployment
Step 4: Set up the RAGAS experiment
RAGAS (Retrieval Augmented Generation Assessment) is an evaluation framework designed to measure the quality and reliability of RAG systems across multiple dimensions. RAGAS provides granular insights into both retrieval and generation performance through normalized scores ranging from 0 (complete failure) to 1 (perfect performance). We added it to the project by adding an experiment to the project and selecting RAGAS as an evaluator.

The RAGAS evaluator results
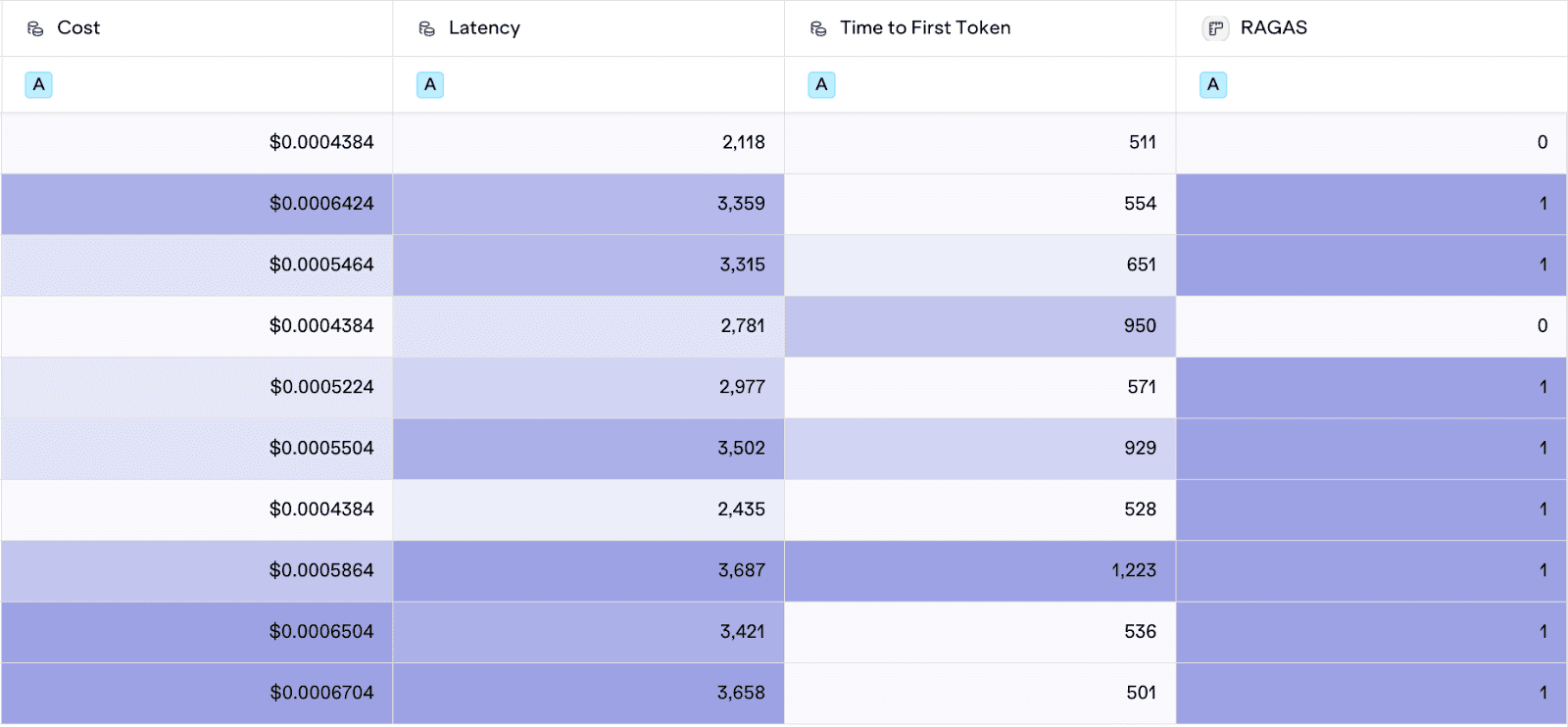
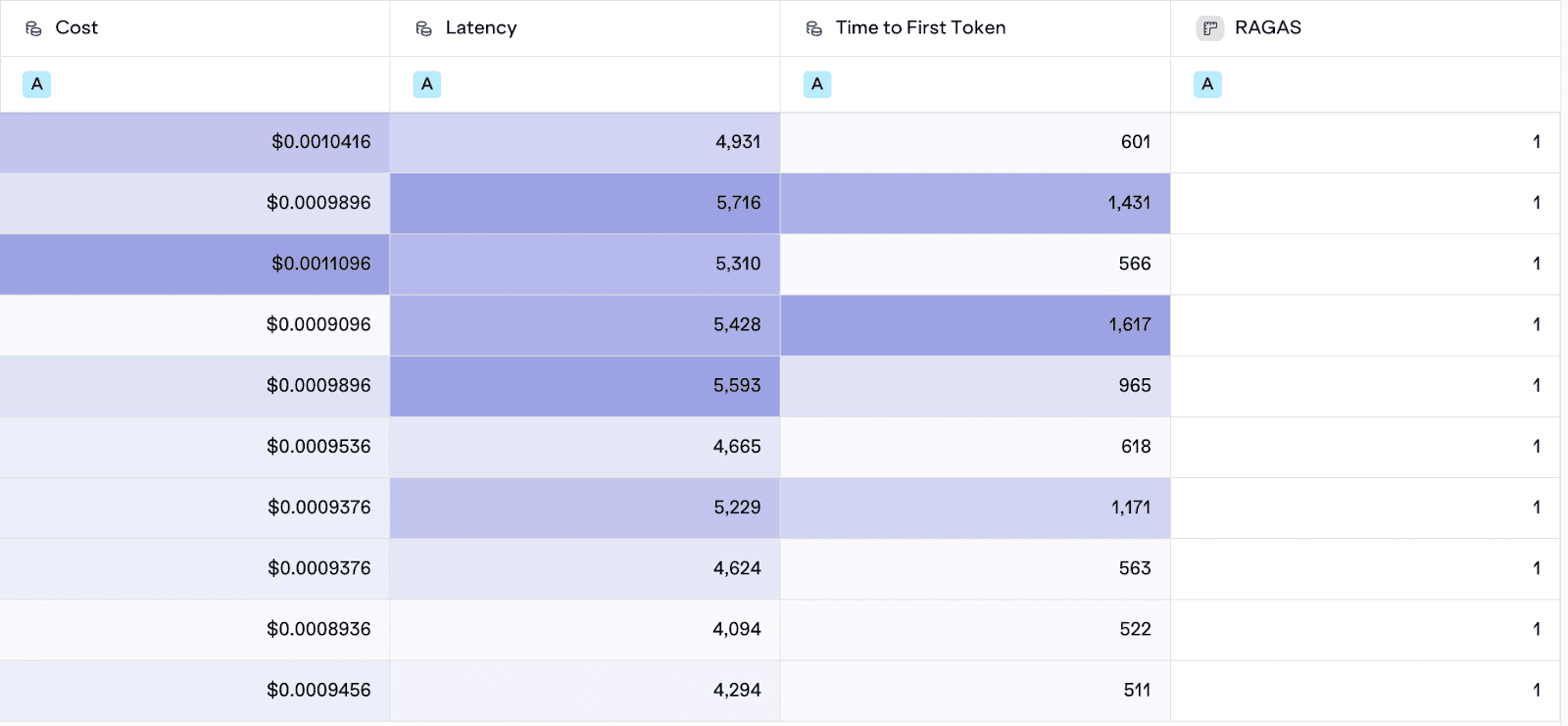
The experiment results show a clear trade-off: the RAG with reranker configuration is slower and more expensive but has a higher success rate. This suggests:
Improved Relevance - The RAGAS values equal to 1 suggest deeper semantic understanding of the knowledge base
Token budget increase - higher cost suggests that the reranker is over-retrieving or could benefit from optimization
Out-of-the-box RAG
RAG with Re-ranker
Conclusion
While out-of-the-box RAG provides a solid foundation, the retrieval step's inherent limitations mean that relevance suffers when it matters most. Cross-encoder models like Cohere Rerank 4 solve this by bringing query-aware intelligence to the retrieval process. Yes, there's a cost trade-off in terms of latency and tokens, but for applications where accuracy is non-negotiable (aviation safety, medical documentation, legal research) that investment pays dividends in user trust and system reliability.

