


When to use LLM judges
LLM-as-a-judge has become the default pattern for evaluating generative outputs at scale. You're producing thousands of completions (question-answering, summarisation, code, agents), and human evaluation gets expensive fast. Judges fill the gap: score or rank outputs in seconds, at a fraction of the cost, with consistent rubrics.
The convenience hides a critical tradeoff. You've replaced human judgement with machine judgement, and machine judgement has its own systematic biases.
One judge, several biases
A single LLM judge is not neutral. Different training data, different architectures, different instruction-tuning, different constitutional constraints. These manifest as measurable, repeatable biases:
Self-preference bias. Judges over-rate outputs from their own family. Yang et al. (2026) quantify this across GPT-4, Claude, Gemini.
Length / verbosity bias. Judges reward longer answers regardless of correctness, even when concise is better. Documented in MT-Bench.
Stylistic bias. Favouring argumentative structures that match the model's own training distribution.
Conservative bias. Defaults to "unsure" or "tie" on tricky or sensitive inputs, even when there's a clear answer.
Confidence bias. Judges reward confident-sounding answers and penalise "I don't know," even when "I don't know" is the right answer.
Specialist gaps. Some models can't reliably judge medical, legal, or technical answers. They don't know enough to spot mistakes.
Position bias. In comparative A-vs-B judging, order outranks content. Shi et al. (2025) show position consistency varies wildly across 15 judges × 22 tasks.
These biases are systematic, not random. Run the same prompt through the same judge twice and you'll get the same skewed score. If your evaluation metric leans one way, your whole pipeline silently selects for that lean.
A panel is an ensemble
What this looks like in practice: GPT tends to be verbose and sometimes over-hedges answers. Claude excels at nuance but can be conservative on edge cases. Gemini is faster but sometimes misses context. When you ask all three to judge the same output, a single model's systematic bias gets diluted. If only GPT is judging and it happens to be overly cautious on a particular style of response, you lose information. But if Claude and Gemini disagree with GPT's caution, you can inspect that disagreement; it's often where the interesting edge cases are.
This extends the ensemble principle. In machine learning, we combine weak models to reduce both bias (different models emphasizing different patterns) and variance (averaging smooths out individual prediction noise). With LLM judges, the dynamic is similar. Two independent judges might both make mistakes, but if their mistakes point in different directions, majority voting or inspection of disagreement becomes a very relevant signal.
A panel of LLM judges is an ensemble. Like every ensemble, it only works under two conditions:
Base learners are diverse. Different models, different families, different error profiles. Three correlated judges are one judge with 3× more requests.
You're using the ensemble for the right reason. Aggregation, uncertainty estimation, or both.
Re-running one judge ten times under identical conditions is a repeated trial, not an ensemble. Swap providers, vary the rubric, stack judges with different strengths. Now you've diversified the components, and aggregation gives you the ensemble effect: lower bias, lower variance, and a disagreement signal you can study.
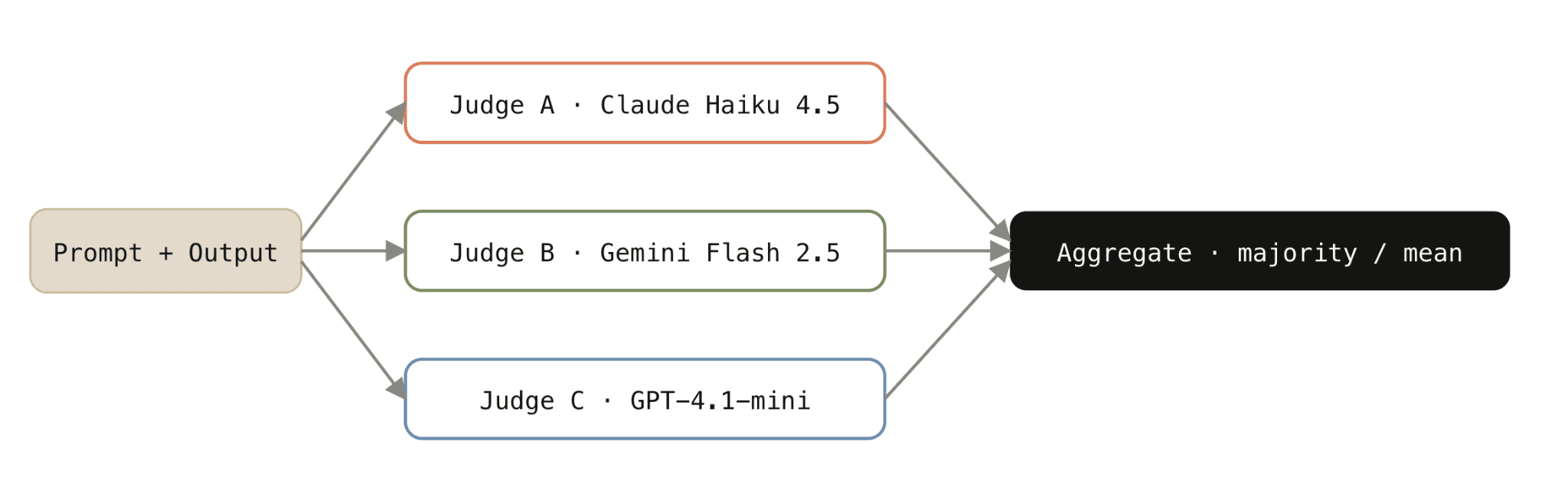
Panel architecture. Three judges run in parallel. Aggregator emits the verdict, the per-judge votes, and the disagreement signal.
Why 3 models? Research on multi-annotator agreement (Krippendorff's alpha, Fleiss' kappa) shows this effect is strongest with 3-5 annotators. More than that and marginal gain plateaus while costing more money. So the "3 judges" rule isn't arbitrary: it's the point where you capture the ensemble benefit (diverse error surfaces) without overpaying for diminishing returns.
Why are you running a panel?
Maintaining a panel is extra engineering and extra LLM calls. Before committing to the effort, name which signal you're interested in:
1. Hard-case discovery
You need automated eval to surface items it can't decide so a human can label them. The output you care about isn't the aggregate. It's the disagreement set. Best fit: direct-scoring tasks feeding an annotation queue.
2. Bias coverage
A single family carries a systematic distortion (verbosity, self-preference, position) you can't silently bake into your pipeline. The output is the aggregate, and its value is that no single family dominates. Best fit: comparative preference, RLHF data, anything that compounds.
3. Ensemble accuracy
The task is subjective enough that no single model clears the human-agreement baseline alone, but a diverse panel does. The output is the aggregate hitting κ ≥ target. Best fit: subjective scoring where single judges fall short.
A well-designed panel delivers all three at once. Can't name at least one? Don't run a panel.
Two protocols, two goals
Two protocols dominate the literature. The panel does different work for each. The rest of this post is two stories, one per protocol.
Direct scoring (pointwise). Judge sees one response, returns a score:
pass/fail, a category, or 0–100. Goal of the panel: find edge cases the rubric can't decide and route them to humans.Comparative (pairwise, A vs B). Judge sees two candidates and picks
A,B, orTIE. Goal of the panel: stabilize noisy verdicts; optimize panel composition for cost vs. agreement.
Why do the panels do different work? Because the protocols fail differently. Comparative judges contradict themselves about a third of the time on tiny prompt tweaks. Direct scores barely move. Wang et al. (2025) measured the gap:
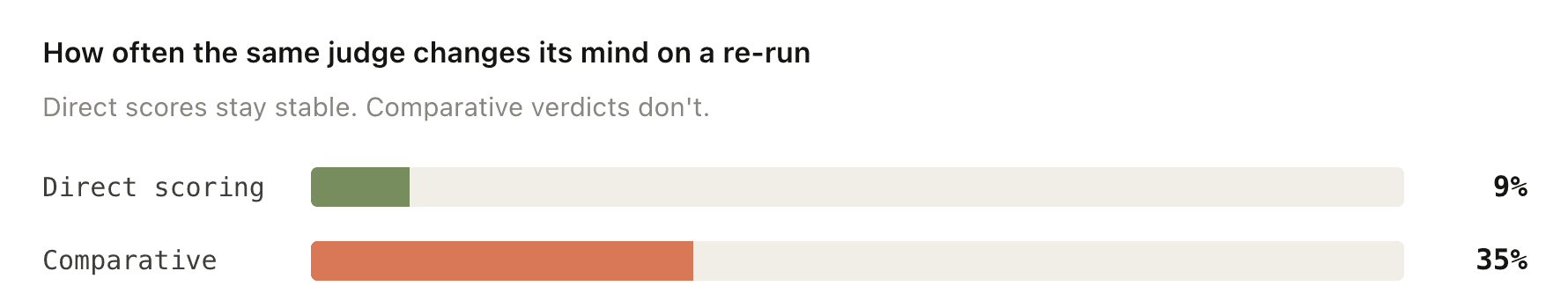
Same judge, same item, slightly tweaked prompt: % of verdicts that flip. Comparative is ~4× more unstable. Wang et al. 2025.
That stability gap is what assigns each protocol its panel job. Direct scoring: since a single judge already gives consistent answers, panel disagreement is rare, and when it shows up, it flags the item as hard. That's your escalation signal. Comparative: since a single judge can't even agree with itself, the panel's job is to vote down the noise before it reaches the verdict.
Which agreement metric to use
Both protocols need an agreement metric to compare judges against humans. Which one depends on your output shape:
Output type | Protocol | Agreement metric |
|---|---|---|
Boolean (PASS/FAIL, safe/unsafe) | Direct scoring | |
Categorical (3+ classes) | Direct scoring | |
Numeric (0–100, Likert) | Direct scoring | |
Pairwise (A / B / TIE) | Comparative |
From here, "agreement with humans" in the rest of this post means the metric appropriate to your output. The optimization framing applies universally; only the metric changes.
Direct scoring: a panel as a hard-case detector
In direct scoring, a competent single judge already produces stable, reproducible scores on easy items. Adding two more judges doesn't shift the easy cases (they already agree). The value lands on the hard cases: items where judges disagree are exactly the items your rubric doesn't decide cleanly. Those are the ones a human should label.
Escalation flow
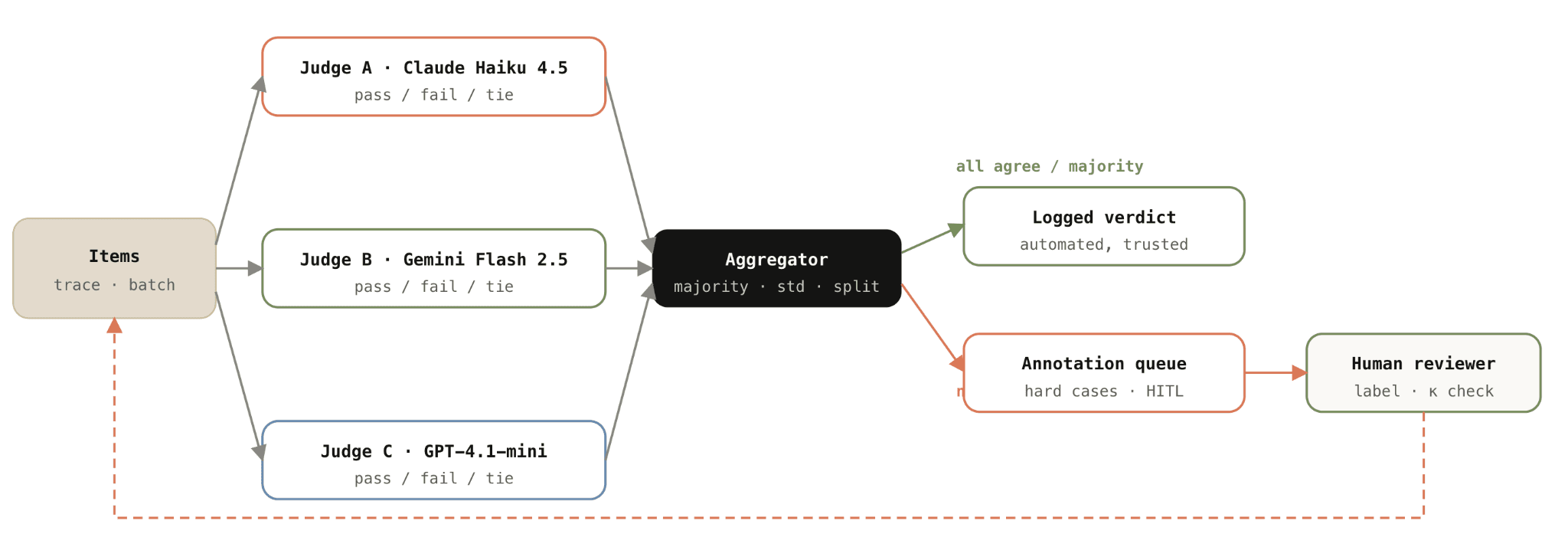
Escalation flow. The panel's real product is the routing decision, not the aggregated verdict. Items the panel can't decide form the annotation queue. Human labels close the loop back into the rubric, the dataset, and the next round of judge calibration.
What you also get is a routing decision for the annotation queue. Hard cases are selected for manual human annotation. They refine the rubric, seed the eval dataset, and recalibrate the next round of judges.
Diagnostic signals
Signal | Meaning | Action |
All three agree | Easy case, rubric works | Log automated verdict |
High inter-judge std (numeric) | Borderline score | Escalate to human |
Categorical TIE | Judges can't distinguish | Escalate to human; consider rubric refinement. |
Example direct-scoring prompt
Run the same prompt to each of the three judges in parallel, then aggregate:
3 PASS : log automated PASS
3 FAIL : log automated FAIL
2:1 split : escalate to human (the disagreement signal)
Diversity of perspective reduces systematic error. One empirical case for doing this is Verga et al. (2024), "Replacing Judges with Juries". Their Panel of LLM evaluators (PoLL), three small models from different providers (command-r, gpt-3.5-turbo, haiku), beat a single large judge across six datasets. In that case, the 3 models mitigated the biases at about 7× lower cost.
The math is this: if three uncorrelated judges agree, the joint error is small. If they disagree, you've detected a hard datapoint that probably warrants human review. This mirrors ensemble classification in machine learning, where the core assumption is that multiple smaller models collectively outperform a single large model. They complement each other, making more reliable predictions.
Comparative: a verdict stabilizer and a selection problem
Different goal. Comparative verdicts flip ~35% of the time when you re-run the same item with a slightly tweaked prompt. A single judge is not just biased but structurally unreliable. The panel here is how you get a verdict that survives multiple runs and stays stable.
That changes the question. In direct scoring, the question was which items escalate? In comparative, the question is which judges do I pick, and how do I prove the panel reaches human-level agreement at minimum cost?
How to choose your judges
Start by establishing a realistic agreement ceiling. Human annotators in real life don't hit perfect agreement on pairwise judgments, so demanding it from judge models is counterproductive: it sets an unrealistic standard instead of improving evaluation quality.
The ceiling is human–human agreement
Humans don't hit perfect agreement on A-vs-B either. Targeting κ = 1.0 is not realistic.
MT-Bench (Zheng et al., 2023) reports human-human pairwise agreement around 0.81 (excluding ties) and GPT-4 vs humans at 0.85 on the same setup.
Chatbot Arena (Chiang et al., 2024) reports crowd-vs-expert agreement of 72–83%, and expert-vs-expert at 79–90% on a sampled re-annotation.
The Cohen’s Kappa interpretation table most papers cite puts agreement coefficient 0.6 to 0.8 in the "substantial agreement" band and κ > 0.8 in "near-perfect". With ties included and harder prompts, even strong human pools land in the lower half of that band, around κ ≈ 0.65.
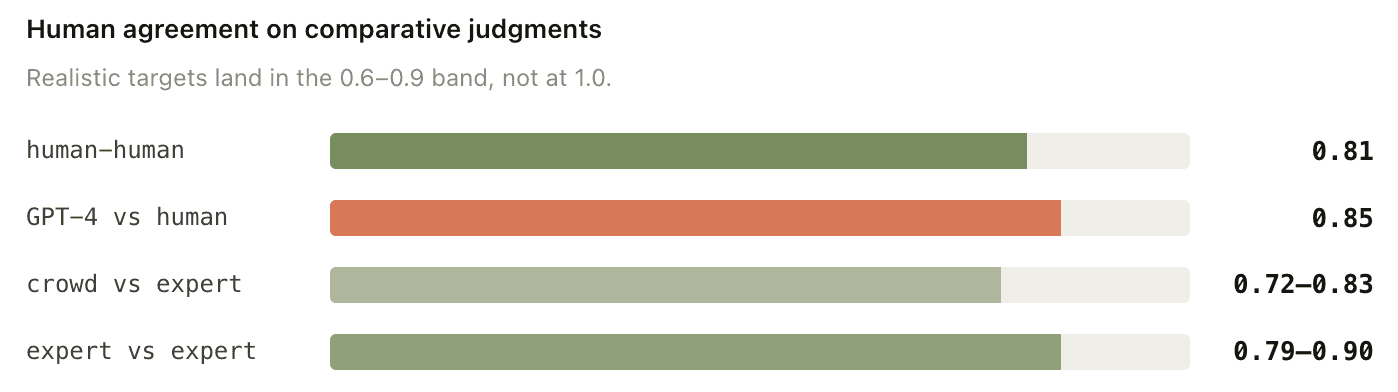
Sources: human-human and GPT-4 vs human from MT-Bench (Zheng et al. 2023); crowd-vs-expert and expert-vs-expert from Chatbot Arena (Chiang et al. 2024). Cohen's κ scale: 0.6–0.8 = substantial, > 0.8 = near-perfect. Targeting κ ≥ 0.65 is the realistic baseline.
The baseline is judges whose agreement with humans lands in the same 0.6–0.8 band that humans hit with each other. Inside that band, you're at the noise floor of the task, performing at human-level consistency.
For our prototype, we needed to judge which answer was better between two options. Since this is subjective, we adopted κ ≈ 0.65 as our working baseline: the lower edge of the substantial-agreement band and the typical performance of human raters on harder pairwise comparisons (including ties). This is intentionally conservative. A panel that exceeds it is performing well; a panel that falls short isn't production-ready.
If you're working on a new subjective task without labeled data to calibrate against (say, evaluating a fresh domain with no annotation budget), use the selection protocol below. It's the most cost-effective way to bootstrap a defensible panel before you have your own ground truth.
Panel selection as an optimization problem
Now that we know the baseline agreement for comparative evaluation, the judges selection is a combinatorial optimization problem. Pick the cheapest subset of candidate judges whose aggregated agreement clears your target κ, subject to a diversity constraint (uncorrelated error profiles).
Formal problem
Diversity is measured on error profiles, not only on providers. Provider mix is a useful proxy. Two judges from different providers that happen to make the same mistakes, swap one.
This reframes the problem: you are maximizing diversity and agreement while minimizing cost. Recent work covers this from different angles:
Tornede et al. (2025), "Tuning LLM Judge Design Decisions for 1/1000 of the Cost" use multi-objective hyperparameter search to find optimal configurations across cost and accuracy.
"Don't Always Pick the Highest-Performing Model" (2026) shows that diverse imperfect judges outperform correlated perfect ones
Auto-Prompt Ensemble (Li et al., 2025) demonstrates that dynamic confidence weighting (per-judge, per-item) can improve panels on top of static selection
Model selection protocol:
Literature review. Find the most similar task with published agreement results. In our example, human preference between two answers was about 0.65 κ, our baseline target.
Get a small human-labeled set. 100 pairwise items, ideally annotated by 2+ people so you can compute human-human κ as your in-house ceiling.
Score every candidate against it. Per-judge κ vs the human consensus. Drop anything well below the human-human floor on your data (in practice: κ < ~0.5 is usually a discard).
Pick 3 from different providers that hit the baseline, ideally with different error profiles. Two judges that agree with humans at 0.7 but with each other at 0.95 give you no panel benefit.
Example comparative prompt
Run the same prompt to each of the three judges in parallel, then aggregate:
If 2+ judges pick A → Winner = A
If all three pick different options → hard case, flag for human review
If 2+ judges pick TIE → the question may be ambiguous, improve the prompt
The diversity test
Universal health check. If your judges agree on everything, fire two of them.
Above 95% inter-judge agreement, one of two things is happening:
Task is objectively easy. Drop the panel.
Judges are correlated (same family, same training data, same prompt artifacts). You have the illusion of redundancy. Swap one for a different provider.
Sweet spot: panel agreement below the human-human ceiling on hard prompts, within the substantial-agreement band overall (κ in 0.6–0.8). Inside that range, easy cases are settled and disagreement reliably points at the hard ones.
This mirrors ensemble learning. Bagging and boosting work because base learners make different mistakes, so averaging cancels them. Three judges with uncorrelated error surfaces are a real ensemble. Three judges that always agree are not.
When NOT to use a panel
Judge panels add latency and cost. They're not always the right choice:
Judges agree on everything. >95% agreement on real data? You bought one verdict three times. Drop two, or swap them.
Genuinely objective task with a tight rubric. Code compiles or it doesn't. A fact is cited or it isn't. Single strong model wins on speed and cost.
For subjective evaluation, comparative preference, or any objective task feeding a human-review queue: panels earn their keep.
The minimal-jury checklist
Distilling the literature plus our prototypes into a defaults table:
Decision | Recommended | Why |
|---|---|---|
Panel size | 3 (odd) | Avoids tied votes; PoLL paper showed 3 is enough. |
Provider mix | One per provider (Anthropic + OpenAI + Google) | Different families. Less intra-family bias |
Judge tier | Small / fast models | A panel of small judges can beat one large judge; Make sure they hit the baseline agreement |
Aggregation (boolean) | k-of-N majority | Fail-closed on ties unless told otherwise. |
Aggregation (numeric) | Mean + report std | Std is the disagreement signal. |
Aggregation (categorical) | Mode + emit explicit | Don't hide ties in nulls. |
Aggregation (pairwise) | Majority over A / B / TIE | TIE means panel split, not a draw between answers. |
Position swap | For comparative | Make the position random. Position bias is a pairwise problem. |
Disagreement routing | High-split -> send to human | Use as triage for further annotation of edge cases |
References
Zheng et al. (2023), Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. NeurIPS. Human-human pairwise ~0.81, GPT-4 vs humans ~0.85.
Chiang et al. (2024), Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference. ICML. Crowd-vs-expert 72–83%, expert-vs-expert 79–90%.
McHugh (2012), Interrater reliability: the kappa statistic. Kappa interpretation: 0.6–0.8 substantial, >0.8 near-perfect.
Tornede et al. (2025), Tuning LLM Judge Design Decisions for 1/1000 of the Cost. Multi-objective, multi-fidelity HPO for judge configs.
"Don't Always Pick the Highest-Performing Model: An Information Theoretic View of LLM Ensemble Selection" (2026). Greedy MI for budget-constrained ensemble selection; correlation matters, not just accuracy.
Li et al. (2025), Auto-Prompt Ensemble for LLM Judge. APE with Collective Confidence metric for dynamic judge weighting.
Wang et al. (2025), Pairwise or Pointwise? Evaluating Feedback Protocols for Bias in LLM-Based Evaluation. Pairwise prefs flip ~35% vs ~9% for pointwise; pairwise more vulnerable to distractor and position bias.
Verga et al. (2024), Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models. arXiv:2404.18796.
Shi et al. (2025), Judging the Judges: A Systematic Study of Position Bias in LLM-as-a-Judge. IJCNLP.
Yang et al. (2026), Quantifying and Mitigating Self-Preference Bias of LLM Judges. arXiv.
Justice or Prejudice? Quantifying Biases in LLM-as-a-Judge: twelve-bias survey + the CALM framework.
Bradley-Terry model: the classical paired-comparison MLE; useful when you want to roll panel verdicts into a leaderboard.
Every judge call in our prototypes routes through orq.ai AI Router, which let us swap and benchmark multiple models combinations, and a dozen others behind a single OpenAI-compatible endpoint, with traces, cost, and per-judge agreement logged automatically. If you're running LLM-as-judge today and want to pilot a jury, drop us a line.

