


A recent paper claimed that repeating the input prompt improves LLM accuracy. We replicated it across 13 next-gen models (GPT-5 Mini, Gemini 3 Pro, Claude Sonnet 4.6, DeepSeek R1), 6 benchmarks, and 334 experiment runs. The finding holds, and the gains are larger than we expected.
The paper's claim
"Prompt Repetition Improves Non-Reasoning LLMs" (arXiv:2512.14982) makes a simple claim: if you send the same prompt to an LLM twice in the same message, accuracy goes up. The authors tested this on older models (GPT-4o, Llama 3) and saw consistent improvements on knowledge and math benchmarks.
The proposed mechanism: LLMs struggle with information in the middle of their context window. Repeating the prompt gives the model a second chance to attend to the question and its constraints. It's cheap (just more input tokens), doesn't require prompt engineering expertise, and takes about 30 seconds to implement.
But the paper was published before the current generation of models. GPT-5.4, Gemini 3 Pro, Claude Sonnet 4.6, and DeepSeek R1 are substantially more capable. Does the trick still work when the baseline is already strong?
The experiment
We tested four repetition strategies plus a padding control, across 13 models and 6 benchmarks. 334 experiment runs total, all routed through the orq.ai platform. Standard models were called with temperature=0 for deterministic outputs; reasoning models (GPT-5 Nano, DeepSeek R1, and runs with reasoning explicitly enabled on DeepSeek V3 and GPT-5.4) were called with provider defaults.
Method | What it does | Why |
|---|---|---|
Baseline | Prompt as-is | Control group |
Repeat | Prompt concatenated with itself | Simplest repetition |
Verbose | Prompt + "Let me repeat that:" + prompt | Adds a natural-language separator |
x3 | Prompt repeated three times | Tests whether more repetition = more gain |
Padding | Prompt + random tokens (same length as repeat) | Mechanism test: isolates whether gains come from repeated content or just longer input |
The padding control is important: if repetition's benefit came from simply having a longer input (more attention layers engaged, more compute), then padding with random tokens should help equally. As it turns out, padding doesn't help. It makes things worse.
We tested across six benchmarks that cover different failure modes:
Benchmark | Task type | Tests |
|---|---|---|
ARC Challenge | Multiple-choice science | Knowledge recall |
OpenBookQA | Multiple-choice science + common knowledge | Knowledge recall |
GSM8K | Grade-school math | Reasoning |
MATH | Competition-level math | Hard reasoning |
NameIndex | Retrieve a name by position in a list | Mid-context attention |
MiddleMatch | Find a matching item in mid-sequence | Mid-context attention |
The last two benchmarks directly test the paper's proposed mechanism: models losing track of information in the middle of their context window.
The 13 models span three tiers. Cheap models ran all 5 methods on all 6 benchmarks. Expensive and reasoning-only models ran baseline + repeat.
Model | Reasoning | Tier |
|---|---|---|
Gemini 2.5 Flash Lite | Off | Cheap |
GPT-4.1 Mini | Off | Cheap |
GPT-4.1 Nano | Off | Cheap |
DeepSeek V3 (Chat) | Off | Cheap |
Claude Haiku 4.5 | Off | Cheap |
Gemini 3.1 Flash Lite | On (minimal) | Cheap |
Gemini 3 Flash | On (high) | Cheap |
GPT-5 Mini | On | Cheap |
GPT-5.4 | Off | Expensive |
Claude Sonnet 4.6 | On (adaptive) | Expensive |
Gemini 3 Pro | On (high) | Expensive |
GPT-5 Nano | On (always) | Reasoning-only |
DeepSeek R1 | On (always) | Reasoning-only |
Seven of thirteen models have reasoning enabled by default and can't be turned off via API. All received the system prompt "Do not reason. Answer directly." to match the original paper's setup. This instruction worked for non-reasoning models but was ignored by models with reasoning forced on, which means our results for those models reflect reasoning-enabled behavior.
It works. Here are the numbers.
Averaged across all models:
Benchmark | Baseline | Repeat | Verbose | x3 | Padding |
|---|---|---|---|---|---|
ARC | 87.7% | 87.4% | 88.6% | 91.1% | 72.3% |
GSM8K | 59.1% | 64.3% | 58.1% | 58.6% | 44.8% |
MATH | 38.8% | 39.9% | 34.0% | 34.5% | 27.5% |
MiddleMatch | 27.3% | 41.2% | 46.4% | 48.3% | 20.8% |
NameIndex | 47.8% | 74.6% | 66.5% | 67.2% | 27.9% |
OpenBookQA | 88.6% | 89.6% | 89.2% | 89.5% | 66.1% |
Each comparison tests one method against the baseline on one model and one benchmark. Eight cheap models ran all three repetition methods (repeat, verbose, x3) on all six benchmarks; five expensive or reasoning-only models ran repeat only (GPT-5 Nano and DeepSeek R1 skipped GSM8K and MATH due to cost). This produced 170 model × benchmark × method comparisons, excluding the padding control.
Of those 170, 100 showed statistically significant improvement over baseline (McNemar test, p < 0.05). 15 showed significant degradation — and 13 of those 15 occurred on reasoning-enabled models, consistent with the finding that reasoning and repetition compete for the same gains.
The padding control was designed to test an alternative explanation: maybe repetition helps simply because the model gets more tokens to "think over," regardless of content. To rule this out, we re-ran every prompt with random tokens appended at the same input length as the repeat method.
The result: padding caused 12 significant degradations and zero improvements. GPT-4.1 Mini dropped from 93% to 29% on ARC; GPT-4.1 Nano fell from 82% to 18%. On Azure-hosted models, padding triggered what appears to be content filtering. Response lengths collapsed and latency spiked 6×. But even on unaffected providers (Gemini, Claude, DeepSeek), padding never helped. So the gains from repetition aren't a token-count artifact, they come from meaningful, repeated content.
The standout results aren't the averages. They're the individual model-benchmark pairs where repetition transforms a struggling model:
Model | Benchmark | Baseline | Best Method | Delta |
|---|---|---|---|---|
DeepSeek V3 | NameIndex | 26% | x3 | +74pp |
Gemini 2.5 Flash Lite | NameIndex | 25% | repeat | +75pp |
GPT-5.4 | MiddleMatch | 26% | repeat | +49pp |
GPT-5 Mini | ARC | 69% | x3 | +21pp |
Claude Haiku 4.5 | NameIndex | 32% | verbose | +64pp |
Gemini 3 Pro | GSM8K | 81% | repeat | +12pp |
All p < 0.001. DeepSeek V3 goes from 26% to 100% on NameIndex just by repeating the prompt three times.
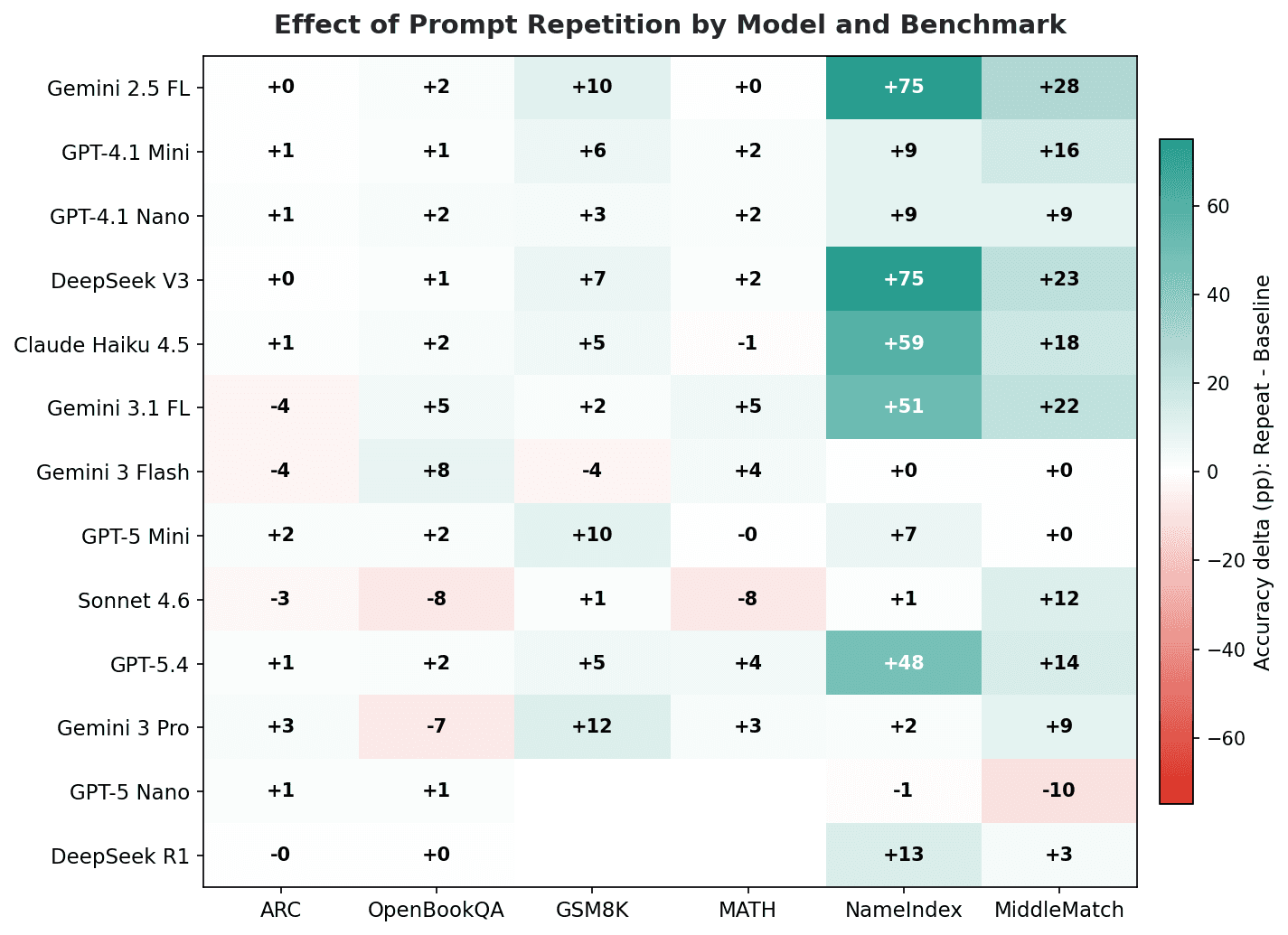
Accuracy change (percentage points) when repeating the prompt, by model and benchmark. Green = improvement, red = degradation. NameIndex and MiddleMatch (attention tasks) show the largest gains across nearly all models.
Mid-context retrieval tasks benefit most
Strictly speaking, every LLM task uses attention. What we mean here is more specific: tasks where the answer is a single piece of information buried in the middle of a list of plausible distractors, and the model has to locate it by position rather than reason about it. NameIndex (retrieve the name at position k from a list of 50 names) and MiddleMatch (find the item in the middle of a sequence that matches a pattern) are designed to stress this, as they're the canonical "lost in the middle" failure mode from Liu et al. 2023.
These two benchmarks showed by far the largest gains: NameIndex +32pp on average across all 13 models, MiddleMatch +14pp. Knowledge tasks (ARC, OpenBookQA) and math tasks (GSM8K, MATH) involve attention too, but the bottleneck there is reasoning or recall, not mid-context retrieval, so repetition helps much less.
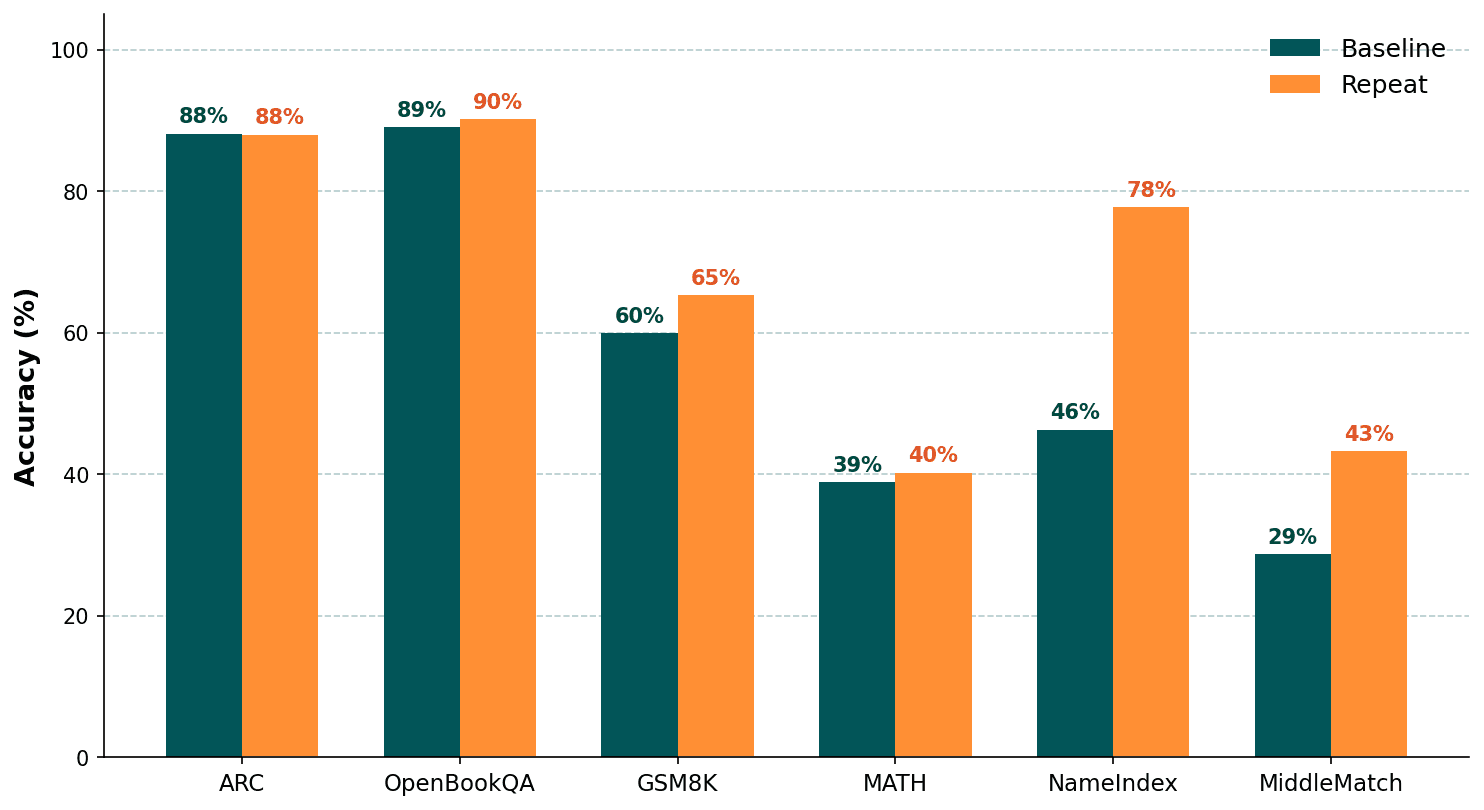
Average accuracy across all 13 models, baseline (teal) vs repeat (orange). The biggest gaps appear on NameIndex (+32pp) and MiddleMatch (+14pp) — both mid-context attention tasks.
Knowledge benchmarks (ARC, OpenBookQA) already had high baselines (87-89%) and showed smaller but consistent improvements. Math benchmarks (GSM8K, MATH) were mixed. Repeat helped on GSM8K, but verbose and x3 sometimes hurt on MATH, suggesting that for hard reasoning problems the extra context can be distracting.
Think about where this matters in practice. You have a RAG pipeline that retrieves three documents and stuffs them into the prompt alongside detailed formatting instructions. The model nails the answer from the first document but ignores the constraint from the third. That's a mid-context attention failure, exactly the class of problem where repetition showed its largest gains. Repeating the full prompt (retrieved docs, instructions, and all) gives the model a second pass at the material it dropped the first time.
Reasoning models gain less — by a lot
Splitting the same data by whether the model has reasoning enabled by default reveals a clean pattern: on the two attention benchmarks where repetition shines, reasoning-enabled models gain roughly a third as much as non-reasoning ones.
Benchmark | Non-reasoning models | Reasoning-on models |
|---|---|---|
NameIndex | +46.0pp | +10.4pp |
MiddleMatch | +24.2pp | +5.1pp |
GSM8K | +6.1pp | +4.2pp |
MATH | +1.4pp | +0.7pp |
OpenBookQA | +2.1pp | +0.2pp |
ARC | +0.2pp | −0.7pp |
Average accuracy change from repeat method, vs baseline. Reasoning-on group: 7 models with reasoning enabled by default. Non-reasoning group: 6 models with reasoning off.
The non-reasoning group's gain on NameIndex (+46pp) and MiddleMatch (+24pp) is dramatic — these are the models that benefit most from a second pass over the prompt. Reasoning-on models still benefit, but their internal chain-of-thought already does some of the work repetition would do, so the marginal uplift is much smaller. On ARC, OpenBookQA, GSM8K, and MATH the two groups behave similarly: small positive gains across the board.
Where repetition hurts
Not every model benefits. Of 170 model × benchmark × method comparisons, 15 showed statistically significant degradation — and the pattern is clear: reasoning-enabled models on tasks they already handle well.
Model | Benchmark | Baseline | Method | Δ |
|---|---|---|---|---|
GPT-5 Mini | OpenBookQA | 83% | verbose | −17pp |
GPT-5 Mini | OpenBookQA | 83% | x3 | −17pp |
GPT-5 Nano | MiddleMatch | 13% | repeat | −10pp |
Claude Sonnet 4.6 | MATH | 68% | repeat | −8pp |
Claude Sonnet 4.6 | OpenBookQA | 89% | repeat | −8pp |
Gemini 3 Pro | OpenBookQA | 84% | repeat | −7pp |
Aggregated by model, the worst offenders are Claude Sonnet 4.6 (3 degradations, avg −6pp), GPT-5 Mini (2 degradations, avg −17pp), and the Gemini 3 family (7 degradations across Flash / Flash-Lite / Pro). Every one of these has reasoning enabled by default. The only non-reasoning models with a significant degradation were GPT-5.4 on ARC (−3pp) and DeepSeek V3 on MATH (−2pp), both small.
Rule of thumb: if reasoning is on and the baseline is already strong (>80%), repetition is more likely to hurt than help. This is consistent with the "pick one" finding below — reasoning and repetition compete for the same gains, and stacking them can confuse the model.
Reasoning and repetition: pick one
Seven of our thirteen models had reasoning enabled by default, and we ran explicit reasoning-toggle experiments on two more (DeepSeek V3 and GPT-5.4) — running the full grid of reasoning-off vs reasoning-on, with and without repetition, on all 6 benchmarks. That gives us 12 head-to-head cells to test the hypothesis directly.
Three patterns hold across all 12:
Repetition-only beats reasoning-only on 9 of 12 cells. On every retrieval and instruction-following benchmark (NameIndex, MiddleMatch, GSM8K, OpenBookQA), repetition alone matched or beat reasoning alone.
Stacking both rarely helps on retrieval tasks. "Both" matched or underperformed repetition-only in 3 of 4 retrieval cells. The clearest case: GPT-5.4 on MiddleMatch goes from 47% (baseline) to 75% with repetition alone, but only 61% with reasoning + repetition — a 14-point regression from adding reasoning on top of a working solution.
Reasoning wins on hard math. DeepSeek V3 on MATH was the cleanest reasoning-only win (+6.5pp from reasoning, −1.7pp from repetition). On harder reasoning problems, the chain-of-thought adds value that repetition can't.
Model | Benchmark | + Reasoning | + Repetition | + Both |
|---|---|---|---|---|
DeepSeek V3 | NameIndex | −5pp | +71pp | +70pp |
DeepSeek V3 | MiddleMatch | +2pp | +25pp | +25pp |
DeepSeek V3 | GSM8K | −0pp | +7pp | +7pp |
DeepSeek V3 | MATH | +7pp | −2pp | +8pp |
GPT-5.4 | NameIndex | +5pp | +53pp | +53pp |
GPT-5.4 | MiddleMatch | +21pp | +49pp | +35pp |
GPT-5.4 | GSM8K | +3pp | +5pp | +8pp |
GPT-5.4 | MATH | +2pp | +6pp | +6pp |
Accuracy change vs baseline (no reasoning, no repetition). Showing the 4 most informative benchmarks per model. Bold = best of the three interventions.
This squares with the cross-model finding above: across the 7 always-reasoning models, average gains from repetition were roughly a third of what non-reasoning models saw on the attention benchmarks. Reasoning and repetition both help the model attend to and retrieve information from context — and once the model is already reasoning, repeating the prompt is mostly redundant. For retrieval and instruction-following workloads, repetition wins on cost (no thinking tokens) and on speed (no extended generation), at equal or better accuracy. Save reasoning for the hard math.
Caveat: the explicit toggle experiment is n=2 models, so this is suggestive rather than conclusive. But combined with the per-benchmark split across all 13 models (see "Reasoning models gain less" above), the direction of the effect is consistent across two independent slices of the data.
What it costs
Repetition roughly doubles your input tokens and triple repetition triples them. But the cost increase is negligible at current pricing. Response length and latency didn't increase for any repetition method; models produced shorter, more focused answers with repeated prompts. (The 6x latency spike mentioned earlier was specific to the padding control on Azure-hosted models, likely due to content filtering — not an issue with actual prompt repetition.) The only cost is input tokens, and at $0.10-$0.80 per million tokens for cheap models, doubling a 500-token prompt costs fractions of a cent.
For comparison: reasoning tokens (thinking tokens on models like DeepSeek R1 or GPT-5 Nano) are billed at output rates ($0.40-$4.00/1M) and can add thousands of tokens per request. Prompt repetition achieves comparable gains on retrieval tasks at 10-100x lower cost.
When to use it (and when not to)
Repetition helps most when the model needs to follow precise instructions embedded in a long context: RAG pipelines with multiple retrieved documents, tool-use agents with detailed system prompts, or any workflow where you've seen the model "forget" a constraint mid-response. If you're on a budget and reasoning models are too expensive, repetition gets you partway there for 100x less.
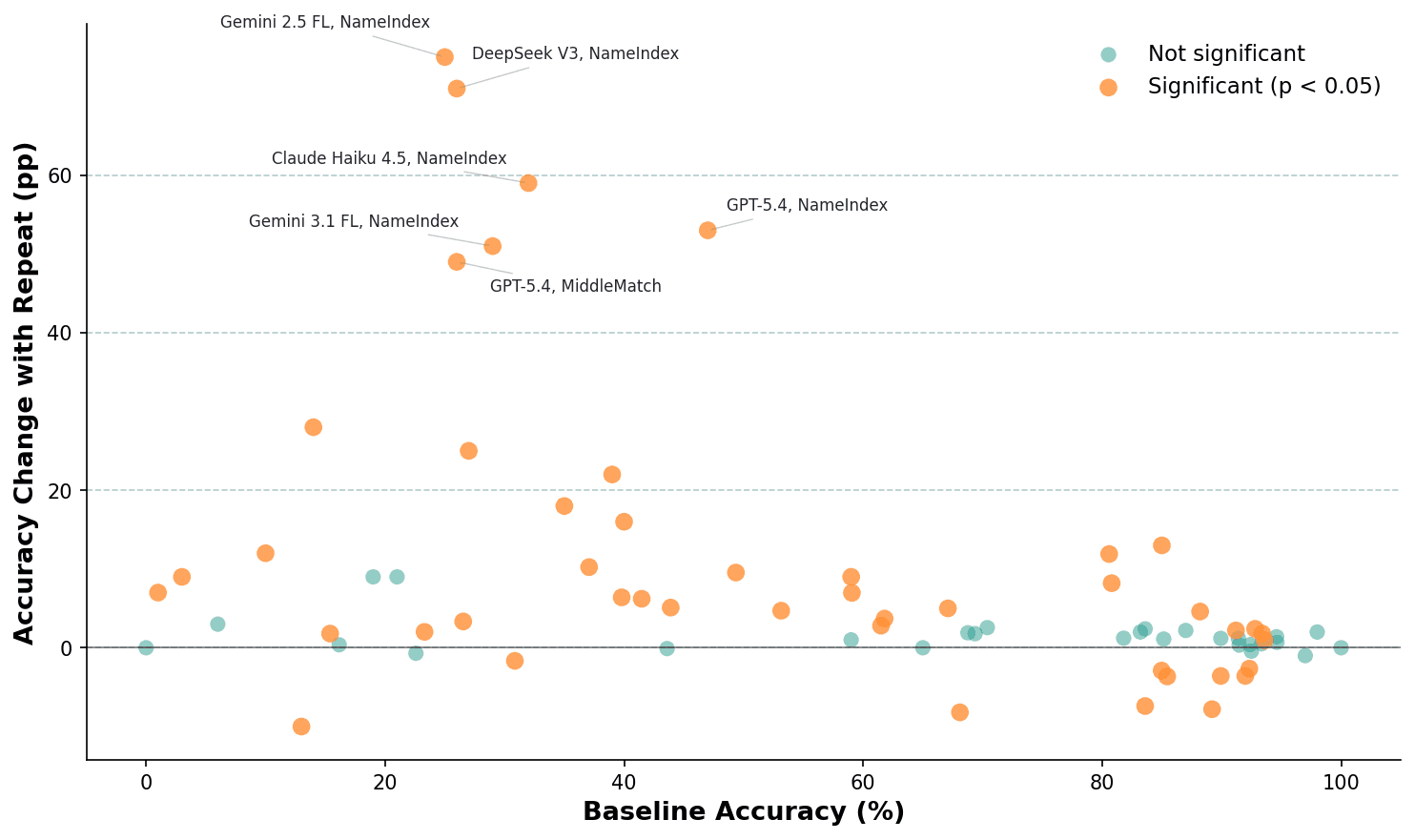
Each dot is one model-benchmark pair. Models with low baselines (left) see the largest gains from repetition; above ~90% baseline, gains flatten out. Orange = statistically significant (p < 0.05).
It won't help much if your prompt is already short and simple, if you're already at the context window limit, or if your baseline is above 95%. And for hard math or logic problems, reasoning tokens add more value than repetition does — reasoning models scored 56–68% baseline on MATH versus 15–40% for non-reasoning models, a gap that repetition alone can't close. In fact, 13 of 15 statistically significant degradations in our experiments occurred on reasoning-enabled models, suggesting that repetition can interfere with chain-of-thought when the model is already reasoning internally.
The simplest implementation is repeat: just concatenate the prompt with itself, separated by a newline. If you want more, verbose (adding "Let me repeat that:") or x3 (three copies) showed stronger results on attention tasks, but repeat is the safest default across all benchmarks.
The takeaway
Copying your prompt twice is the cheapest accuracy improvement available in LLM engineering today. It works on 13 current-generation models, including GPT-5.4 and Claude Sonnet 4.6. It costs fractions of a cent per request and requires zero prompt engineering skill.
The largest gains appear on tasks where models struggle with mid-context attention, exactly the tasks that matter in production RAG pipelines, tool-use agents, and instruction-following systems. If your LLM is dropping instructions or ignoring retrieved context, try repeating the prompt before reaching for a more expensive model or a reasoning mode.
Two caveats. First, our benchmarks use 100-sample runs on synthetic tasks — production prompts are longer, messier, and domain-specific, so your mileage will vary. Second, if your model already reasons internally (GPT-5 Nano, DeepSeek R1, Claude Sonnet 4.6), repetition can sometimes interfere: 13 of our 15 degradation cases came from reasoning-enabled models. For reasoning-heavy workloads, test before shipping.
That said, the consistency across 13 models, 6 benchmarks, and 334 runs makes the direction of the effect hard to dismiss. 100 out of 170 comparisons showed statistically significant improvement. The expected value is positive, the downside is small and predictable (watch out for reasoning models), and the implementation is a one-line code change.
We ran these experiments at orq.ai, which made it straightforward to test 13 models across 334 experiment configurations with consistent evaluation. The original paper (arXiv:2512.14982) deserves credit for the finding; we just confirmed it still works on the models shipping today.
Sources:
Prompt Repetition Improves Non-Reasoning LLMs, the original paper (Dec 2024)
Lost in the Middle: How Language Models Use Long Contexts, foundational work on mid-context attention degradation

