


The new cost problem: AI agents don’t scale like software
Software teams historically learned how to forecast costs because most production systems behave predictably.
The cycle might sound familiar: feature ships, usage increases, infrastructure scales in relatively stable ways, and finance can model spending with reasonable confidence.
But AI agents change that relationship between usage and cost. They don’t execute a fixed path. Instead, they choose what to do next.
A single request can initiate a sequence of actions, like:
Retrieving context
Calling tools and APIs
Routing across models
Retrying uncertain outputs
Escalating to more capable reasoning
Two requests that appear identical to a user can produce very different token usage and external service consumption, causing costs to vary. Keep in mind this is all without any visible change in product functionality.
Consider a support assistant. In simple cases, it answers directly from a knowledge base. In more complex situations, it retrieves documents, summarizes context, calls internal systems, asks follow-up questions, and escalates to a more capable model when confidence is low. From the user’s perspective, the feature is still “resolve my issue.” Operationally, it’s a decision-driven workflow whose cost depends on runtime behavior, rather than request volume.
That’s why so many enterprises only discover cost issues after agents reach production. By 2026, more than 80% of enterprises will use generative AI models, yet fewer than 30% will have sufficient monitoring to connect cost with value. We’re seeing adoption accelerate faster than operational visibility.
Without agent-aware controls, teams tend to oscillate between two responses: restricting experimentation through hard budgets that slow innovation, or deploying agents broadly and learning the real unit economics only after invoices arrive.
This gap is what has led organizations to rethink FinOps for agent systems. Instead of treating AI spending as infrastructure usage, it attributes cost to agent behavior and outcomes, introducing guardrails that lets enterprises scale adoption while maintaining economic predictability.
As adoption expands, organizations realize cost is only the first visible symptom. Once multiple teams deploy agents across workflows and tools, the real challenge becomes operational: not just how much AI costs, but how it behaves.
In practice, that behavior is distributed across the organization. Sales teams deploy agents inside CRM systems, support teams automate workflows, product teams introduce copilots, and engineering launches internal automation. Each initiative works locally, but leaders still lack a global view of what agents are doing across the business.
Why traditional FinOps breaks for agentic systems
Traditional FinOps was designed for deterministic workloads. Infrastructure costs could be allocated, tagged, and optimized, as systems followed predictable execution paths.
Agentic systems introduce a different cost surface.
Their spending is driven less by infrastructure, and more by behavior. Think of model calls, token usage, tool interactions, retries, context growth, and routing decisions. A slightly longer prompt or a fallback to a more capable model can materially change the cost of a workflow without any visible change to the user. In industry, only 27% of organizations can allocate cloud costs accurately to business units or applications in real time.
To manage this volatility, teams are increasingly adopting runtime optimization techniques like intelligent model routing, workflow budgeting, and context control. Rather than statically selecting a single model, requests can be dynamically routed based on task complexity, latency targets, or cost constraints.
This makes traditional monitoring insufficient. Cloud dashboards can show total spend, but not why an agent became expensive, which step caused it, or whether the additional cost improved the outcome. Ownership adds another complication. Less than 25% of companies using AI report having fully standardized governance processes across business and technical teams.
Instead of optimizing token usage or infrastructure utilization, teams optimize cost per outcome with agent FinOps - cost per resolved ticket, qualified lead, completed task, or hours saved. To do that, financial signals need to be connected to operational behavior. That way, spending can be explained, forecasted, and controlled before it becomes a production problem.
From usage to outcomes: redefining FinOps for AI agents
In traditional systems, efficiency is measured through utilization: CPU usage, memory consumption, or infrastructure spend. If cost decreases while performance remains stable, teams usually consider their system to be optimized.
Agentic systems require a different standard, since an agent can use fewer tokens but fail to resolve a task. Or, consume more resources while successfully completing complex work that would otherwise require human effort. Optimizing purely for usage becomes misleading.
The relevant question isn’t how much the system consumed, but whether the consumption produced value.
Agent FinOps connects three layers of signals:
Cost signals: model usage, token consumption, API spend, and budgets
Operational signals: traces, retries, routing decisions, and evaluation results
Business signals: resolution rates, task completion, conversion, and time saved
Individually, each signal is incomplete. Cost shows spending, operational data shows behavior, and business metrics show outcomes. Combine all three, and they reveal the economics of an agent system.
Evaluating agent behavior becomes as important as monitoring usage, because response quality determines whether cost produces business value.
Teams can see which agents create value, which workflows require redesign, and when higher-cost models actually improve results.
Instead of asking “How many tokens did we use?” teams start asking “Which interactions solved a problem?” Financial data needs to be linked to runtime behavior and measurable outcomes. Cost attribution connects traces and user actions to business impact, letting teams refine prompts, adjust routing, change models, or retire automation when it doesn’t justify its cost.
FinOps across the agent lifecycle (experiment → deploy → operate → improve)
Cost problems in agent systems rarely begin in production. They emerge earlier, during experimentation and runtime behavior. By the time invoices reveal the issue, the workflow design that created the cost pattern is already in place.
That’s why agent FinOps can’t be applied only after deployment. It needs to be integrated across the full lifecycle of how agents are built and operated.
Experiment
Early prototyping is where cost patterns first appear. Teams test prompts, models, and workflows without always understanding how many model calls a workflow triggers or how context size grows. FinOps at this stage focuses on bounded experimentation: setting budgets, measuring cost per evaluation, and identifying unit economics before agents reach users.
Deploy
During rollout, variability becomes risk. Routing logic, fallback models, and tool access can significantly change spending. Guarded releases, routing policies, and token or timeout limits help ensure that production behavior remains economically predictable.
Operate
Teams need visibility into retries, escalations, and resource consumption so they can adjust routing, constrain actions, or pause workflows before inefficiency becomes an ongoing cost.
Improve
Evaluation results and outcome metrics reveal where agents succeed or fail. FinOps connects these insights back into development, guiding prompt refinement, workflow redesign, model selection, or retirement of low-value automation. After deployment, teams need to continuously refine prompts and workflows, but changes can affect real users. This makes safe iteration and controlled rollout necessary for production agents.
When cost controls exist only at the end of the process, organizations operate reactively. When embedded throughout the lifecycle, cost management becomes part of system design. Agent FinOps doesn’t scale by tracking spend more aggressively. It scales by shaping agent behavior at every stage of operation so experimentation, deployment, and production align with measurable outcomes.
Why enterprises need a Control Tower for agents
As organizations move from isolated pilots to multiple deployed agents, the nature of the problem changes.
A single agent is a feature. A collection of agents becomes an operational environment.
Different teams begin introducing agents for support, internal workflows, analytics, and automation. Each interacts with models, tools, and internal data. Individually they are manageable, but together they form a distributed system whose behavior and spending emerges from many independent runtime decisions.
In many enterprises, agents aren`t only built in-house but also embedded within third-party SaaS platforms such as CRM, support, analytics, and workflow tools. Different teams adopt these capabilities independently, often without a centralized view of how many agents are active, how they interact with internal systems, or how their usage-based pricing models affect overall spend. It’s also important to have visibility for all of them at a centralized level, as managing each agent in their own system results in fragmentation.
Because each platform exposes its own metrics, controls, and billing logic, organizations struggle to understand cumulative runtime behavior or identify overlapping automation. Even when individual agents appear manageable in isolation, their combined impact can drive unpredictable cost patterns and hidden operational risk.
At that point, the challenge isn’t just development. Rather, it’s coordination and oversight.
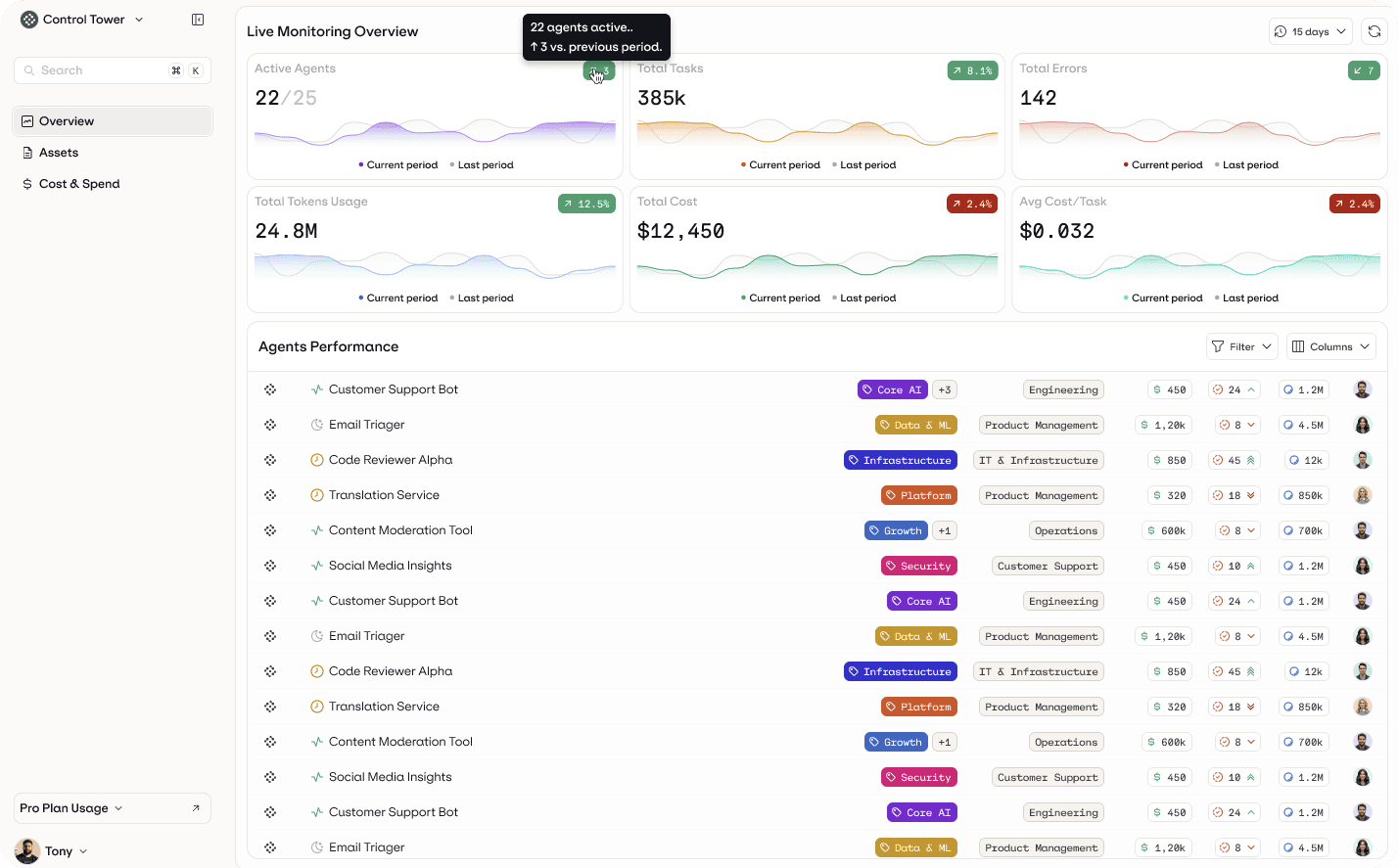
Teams have been finding out the hard way that they lack a single operational view of what their agents are doing.
Leaders can’t easily answer practical questions like:
Which agents are currently active?
Which workflows deliver measurable value?
Where are retries, escalations, or unnecessary model calls occurring?
Which agents consume disproportionate resources relative to outcomes?
Traditional monitoring tools provide infrastructure visibility, but agents require behavioral observability. In regulated environments, teams also need traceability - understanding why a specific output was produced before they can rely on the system in operational workflows.
The system’s cost and performance are determined not just by resources, but by runtime decisions: routing logic, tool usage, confidence thresholds, and workflow design. Surveys of enterprise AI adoption point to the same conclusion: monitoring and operational oversight are the primary barriers preventing organizations from safely scaling AI systems.
As the number of agents grows, enterprises understand that no single team owns their operational behavior - product owns use cases, engineering owns workflows, and infrastructure owns compute. As a result, agents operate across organizational boundaries. Each team can deploy automation, but no team has a unified view of how agents interact, overlap, or affect each other.
Enterprises aren't struggling because they can't build agents. They’re struggling because they can’t coordinate them. Different departments deploy automation independently across sales, support, product, and engineering systems. Organizations can infrastructure usage, but they lack visibility into how agents interact, overlap, or create operational risk.
Once multiple agents interact across workflows and teams, organizations need an operational command layer, not just development tooling.
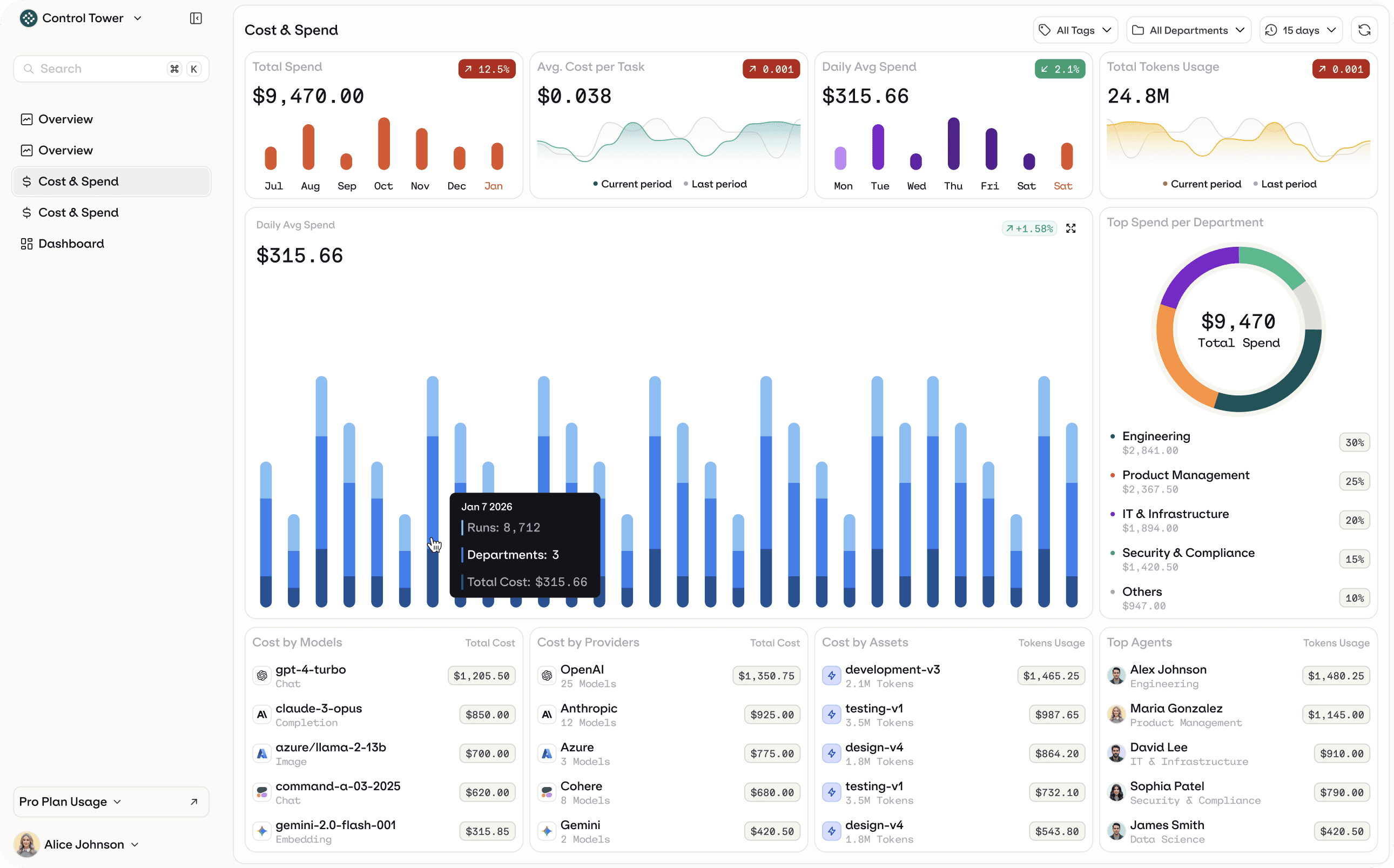
This is where the concept of an agent control plane emerges. At Orq.ai, we call this layer the Control Tower. It's a centralized operational view that connects agent behavior, spending, and governance across the organization. A Control Tower surfaces the agent “asset inventory” across the org, covering both internally built agents and those embedded in third-party SaaS platforms. It also includes rollups like total cost and token usage, plus spend over time and per-agent cost breakdowns, so teams can see what’s running and where the spend is coming from.
What happens when cost, control, and lifecycle are fragmented
Enterprises rarely introduce AI agents all at once. Instead, adoption is typically incremental. Each initiative evolves independently, often using different models and evaluation methods.
At first, this certainly feels like progress. Teams ship features quickly and demonstrate early value. Over time, the cracks start to appear and teams see fragmentation. Industry research supports this pattern: most organizations struggle to move from isolated AI pilots to scaled operational deployment, remaining caught between experimentation and measurable business impact.
Engineering teams become cautious because every change may affect behavior and cost unpredictably. Finance cannot forecast spending due to runtime variability. Product leaders cannot clearly connect agent activity to business outcomes. This hesitation reflects a broader enterprise reality: organizations expand AI adoption only when they trust its governance, transparency, and operational oversight.
Without shared visibility, companies fall into a familiar pattern: either agents are tightly restricted to avoid cost surprises, or they continue operating without clear accountability.
In both cases, progress slows.
From cost control to operating confidence at scale
Agent initiatives rarely fail because models are weak. They stall when organizations aren’t able to connect spending, system behavior, and business outcomes once agents reach production scale.
Agent FinOps closes this gap by linking cost signals (budgets and model usage) with operational signals (traces and evaluations) and business metrics, such as resolution rates or completed workflows. The goal isn’t to simply lower cost, but predictable operation.
As adoption grows, organizations have to manage agents the way they manage other production infrastructure. Cost visibility, evaluation, and governance have to exist within a centralized operational layer.
Book a demo to see how Orq.ai’s Control Tower connects cost attribution, runtime behavior, and governance, so that enterprise leadership has full visibility and internal teams can scale production agents without budget surprises.

