









The new problem: why agents fail after deployment, not at launch
Most AI agents perform well in demos and pilots. They follow instructions, produce accurate outputs, and appear ready for production.
Then real users arrive.
Data changes, edge cases multiply, and small prompts or model updates begin to shift behavior. What worked in a controlled environment before starts to degrade. To make matters worse, it happens in subtle ways that are hard to detect, and even harder to fix.
95% of generative AI deployments fail to deliver measurable business impact. This isn’t because the models are broken, but because they aren’t integrated or managed as systems once deployed. Additionally, Gartner predicts that over 40% of agentic AI projects will be canceled before delivering value without the right operational approach.
Unlike traditional software, agent behavior doesn’t stay fixed after release. It evolves continuously through interaction, data, and model updates.
That’s why most agent initiatives don’t fail at build time. They fail after deployment.
Without continuous evaluation tied to real usage, clear visibility into agent decisions, and structured feedback loops, teams are realizing they have no reliable way to keep agents accurate, safe, and aligned as they scale.
The agent itself isn’t breaking. Rather, it’s the lifecycle around it.
What is agent lifecycle management?
Agent lifecycle management is the discipline of running AI agents as products, not one-off features.
It covers how agents are designed, tested, deployed, observed, and continuously improved after they reach production. The focus isn’t on shipping the first version. Rather, it’s on keeping behavior reliable as the system evolves in real environments.
In traditional SaaS, software is mostly stable after release. In agent systems, behavior changes constantly. A small prompt update, a new data shift, a new model, or a tool failure can alter outcome in ways that are hard to predict. Without structure, teams can lose what is running, why results changed, and whether performance is improving or quietly degrading.
We see this from research highlighting that more than 80% of AI initiatives in the finance sector fail to deliver meaningful production value or stall before scaling, far higher than typical IT projects. In many cases, organizations simply abandon AI efforts altogether, with other surveys finding that 42% of companies dropped most of their AI initiatives in 2025.
That’s why many agent initiatives fail after launch, not before it.
Agent lifecycle management exists to solve this. It creates a closed operating loop between development, evaluation, deployment, and real-world feedback. Each change is tested, observed in production, and fed back into the system so agents improve instead of drift.
Put simply, agent lifecycle management is what turns AI agents into dependable products, rather than fragile experiments.
Why traditional software lifecycles don’t work for AI agents
Traditional software lifecycles assume that behavior is fixed once a feature ships. Teams design, test, release, and expect production behavior to match what they validated.
But AI agents break this model.
An agent’s behavior is shaped by prompts, models, tools, data, and user context. Keep in mind that all of these components can change without a code release. A model update, tool change, or new usage pattern can alter outcomes, even when the application itself hasn’t changed.
This makes versioning unclear and testing unreliable. In many cases, teams can’t trace why an agent behaved a certain way. Not to mention that many failures only appear in real, multi-step workflows after deployment.
Therefore, agents keep changing while organizations are still treating them like static features. The gap between what teams think is running and what is actually happening starts to grow over time at an alarming rate.
That’s why traditional software lifecycles collapse under agent systems: they were built for code that stays still and not intelligence that keeps evolving.
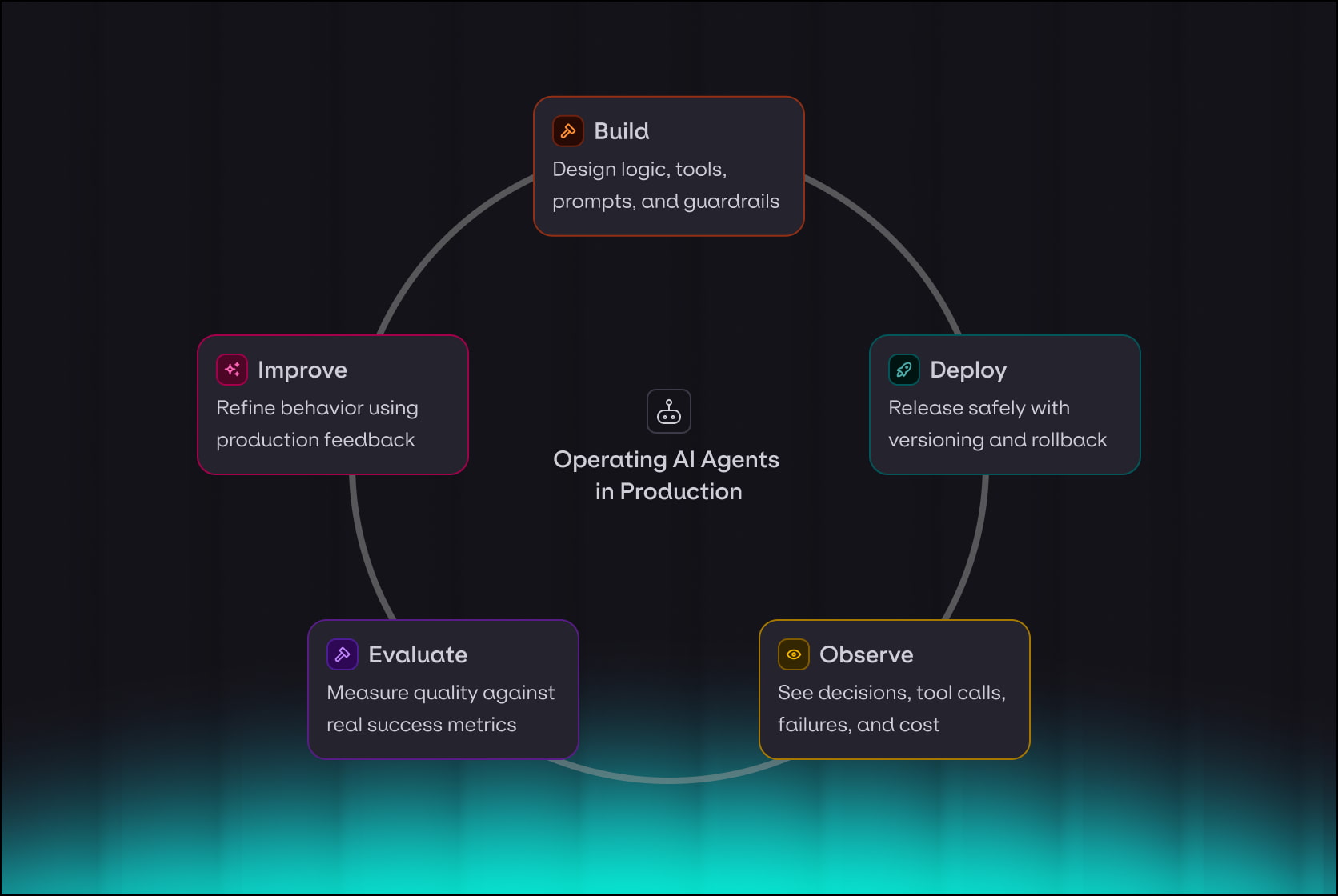
The agent lifecycle: build → deploy → observe → evaluate → improve
AI agents learn from usage, interact with new data, and operate across complex workflows.
You can think of them as living systems.
The agent lifecycle describes the continuous loop required to keep agents reliable in production:
Build: Design the agent’s logic, tools, prompts, and policies. This is where workflows, guardrails, and success criteria are defined.
Deploy: Release the agent into real workflows with versioning, access controls, and safe rollout mechanisms so changes can be tested and rolled back.
Observe: Track what the agent actually does in production - its decisions, tool calls, failures, costs, and user impact.
Evaluate: Measure outputs against real success metrics, not just test prompts. Detects regressions, bias, and edge-case failures using live data.
Improve: Use insights from evaluation to update prompts, logic, tools, or models - then repeat the cycle.
This loop only works when it’s supported by the five core building blocks, which form the foundation of agent lifecycle management.
The five core building blocks of agent lifecycle management
Operating AI agents in production requires more than just good models or prompts.
It requires a system that connects how agents are built, deployed, observed, evaluated, and improved as one continuous improvement loop.
When any of these layers are missing or disconnected, the consequences are immediate. Teams lose visibility, confidence, and control. The result? Fragile systems that perform well in demos, but degrade in production.
These five building blocks form the foundation for running agents as reliable systems.
Development & orchestration
This layer is responsible for how agents reason and act across workflows. It includes prompts, tools, decision logic, policies, and multi-step orchestration between systems. Without centralized orchestration, logic becomes scattered across codebases and services, making it difficult to understand, test, or change how the agent actually behaves, which is why it’s typically owned jointly by application and platform/ML teams.
Deployment & control
This layer reassures enterprises that changes are safe, versioned, and reversible. It includes environment separation, access control, rollout strategies, and the ability to pause or roll back behavior when outputs drift or risk increases. Without deployment controls, every change becomes a production risk, so this layer often sits with platform/SRE and security teams that already own production safeguards.
Observability
Visibility into how agents behave in the real world. This includes traces, tool calls, failures, latency, cost, and user impact. Observability shows what the agent actually did, not what it was supposed to do. Surprisingly, nearly half of organizations don’t monitor their AI systems for accuracy, drift, or misuse.
If enterprises don’t have proper visibility, teams can’t diagnose failures, explain outcomes, or understand where systems are degrading. That’s why observability is usually shared between infrastructure and product teams.
Evaluation
Evaluation is a way of measuring agent performance against real success criteria, not just static test prompts. It moves beyond test prompts to assess behavior in production contexts. It detects regressions, bias, quality drops, and edge-case failures as workflows evolve.
Without continuous evaluation, teams can’t tell if agents are improving, or quietly getting worse in the background, so it’s usually led by ML and product working together on concrete success criteria.
Continuous improvement
Continuous improvement is how agents evolve based on real-world feedback. Insights from observability and evaluation feed back into prompts, logic, tools, and guardrails. This creates a closed loop where behavior improves over time instead of drifting.
If this loop isn’t present, systems stagnate and trust erodes, which is why continuous improvement requires a closed feedback loop across ML, product, and operations.
Together, these five layers turn agents from fragile features into operational systems - systems that can scale and remain reliable as conditions change.
A simple way to sanity-check your own setup is to check whether your enterprise has each of these in place:
A single place to define agent behavior (prompts, tools, policies)
Safe ways to roll out and roll back changes
Traces and logs that show what the agent did for which users
Evaluations tied to business metrics, not just offline tests
A feedback loop so every change is measured and fed back into design
Why lifecycle platforms are emerging
As agents move into production, teams are dealing with the harsh reality that the hardest part isn’t building them anymore - it’s operating them.
From our experience, most teams try having multiple tools at once: one for orchestration, another for evaluation, a third for logging, and a fourth for deployment. In practice, this works for prototypes, but teams quickly notice this breaks down as soon as agents become part of real workflows. It’s important to realize that the issue doesn’t lie with any particular tool - it’s more so the gaps between them.
When orchestration, evaluation, observability, and deployment live in separate systems, enterprises find themselves losing valuable contextual data. They can’t see how a change in a prompt affected production behavior or trace failures back to specific decisions.
Studies of enterprise AI adoption show a visibility gap that undermines reliable operation. While a large majority of companies report using AI tools, only a small fraction have deeply embedded them into workflows in a way that delivers measurable business value.
This disconnect creates three key pressures:
Rising operational cost from custom integrations and manual coordination
Slower iteration because every change feels risky
Lower confidence as teams lose visibility into how agents behave at scale
To handle this tricky coordination problem, teams are starting to turn to lifecycle platforms as a solution. Instead of treating each stage as a separate workflow, they connect the entire agent lifecycle into a single operating system. The same agent definition flows through every stage, with shared context and controls.
Platforms like Orq.ai provide an end-to-end lifecycle environment for agent development, deployment, observability, and continuous evaluation, helping teams move from prototype to production with confidence.
The real shift is operational
AI agents are quickly moving from experiments into the core of modern products and workflows. What once worked for deterministic systems isn’t sufficient for software that reasons, adapts, and changes after deployment anymore.
Agent lifecycle management connects development, deployment, observability, evaluation, and continuous improvement into a single operating loop. That way, teams gain the control and visibility needed to scale agents safely and with confidence.
To see how this lifecycle approach works in practice, explore how Orq.ai helps teams build, operate, and continuously improve AI agents across the full lifecycle.

